







这里只是说明模型的概率图,具体实现算法以后研究。文章综述参考Probabilistic topic models (DaviD m. Blei)
LDA模型
文献参考LDA数学八卦、parameter estimation for text analysis。
思路:类似聚类,认为有一个隐藏的主题作为词标签,对词可分类;此外认为文档中词可交换、文档可交换、主题个数固定且不改变。文档每个词的主题题标生成以及每个主题下词的生成都是服从多项分布,其多项分布概率服从dirichlet分布,注意这里dirichlet分布各自取决于两个超参数
α,η
,这些参数也是事先给定的。
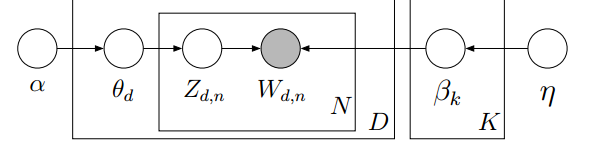
概率图:
概率公式:
我们想做的无非是推断参数
θ,β
,那么只有求出这个概率图的随机量的联合概率,然后积分求期望,至于是不是能得到解析解,那是变分法或者采样所要解决的事情了。
首先生成一个词,对于文档d,生成一个主题分布
θ
,对其中一个词W,由这个主题分布得到一个主题标记Z,然后根据这个主题标记选取相应的词分布
β
,在词分布和主题标记的情况下生成一个词。
p(Wd,n,Zd,n,βk,θd)=p(Wd,n∣Zd,n,βk)∗p(Zd,n∣θd)∗p(βk;η)∗p(θd;α)
这里分布依次是类别分布,类别分布,dirchlet分布,dirchlet分布。
现在生成这个语料,即先取好k个主题-词分布,这是独立的;然后对每个文档D,取一个文档-主题分布,这也是独立;对N个词,各生成词标记,最后生成词,这也是独立的。
所以最后的生成概率是:
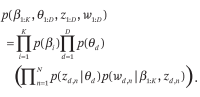
CTM
这里也可以参考TOPIC MODELS(m.blei,2009)。
现实存在这样一个问题,即健康这个主题应该会和基因主题相关,然后LDA模型没法捕获这样的相关性。因为LDA中dirchlet分布采样得到的向量之间近似独立(近似因为他们和必须为1)。容易想到的是用协方差来描述这种关系,可以放宽词袋模型。
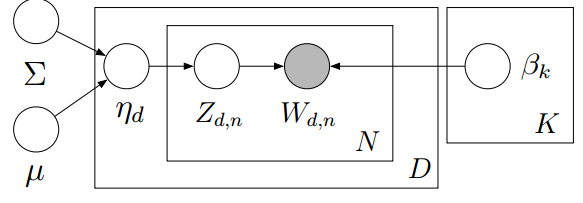
概率图:
概率公式:
这里和LDA的概率一致,唯一的区别是,
η
这个量现在取于高斯分布。但是高斯分布样本是连续的而且正负无穷,因此需要正则化,这里采用logit-gauss分布,即将
η
指数化并映射到单纯性上,简单说就是规范化。(为什么取指数,好像是和自然参数有关,可去wiki上搜索指数分布-自然参数)
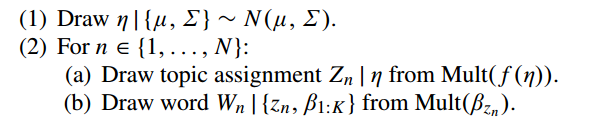
(idea:这里一个只是描述了固定相关性,是否存在可变的相关性呢;这里也只是描述两两相关性)
DTM
这里参考TOPIC MODELS(m.blei,2009)和Dynamic Topic Models
前面CTM只是建模描述主题间本身存在固定关系,然而还有一个事实是,同一个主题的词分布有可能是改进的。比如今年家电主题词中可能电视比例大一些,明年电脑比例大一些。也就是说把\beta建立为可变的,可以放宽文档可交换的假设。
假定给定上一次的词分布情况下,当前主题词分布服从高斯分布,可以体现一种发展性。然后同样采用logit-gauss分布方式,规范化这个主题词分布。
概率图:
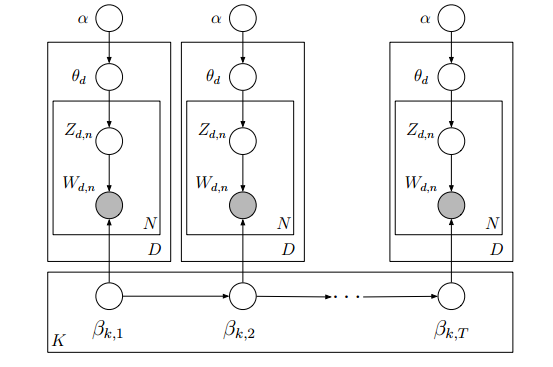
生成过程:

(idea:我感觉其实就是将每年的主题词分布用前一年的主题词分布平滑而已,如果我直接采用每年的dirchlet分布,然后直接用前年的结果平滑应该有差不多的效果;很明显可以考察的问题是文档主题分布的超参数是否也是时间可变的呢;这里只是用高斯转移来描述这种变化,是否可以采用更加复杂的自回归模型呢;这里假定了每年的主题都是固定的,如果有些主题消失或者有新的主题出现呢)
BTM
参考Topic Modeling: Beyond Bag-of-Words
这里是考虑这样一个问题,词的生成可能依赖于前一个词,而不是仅仅依赖于对应主题的词分布。反过来,词的顺序可能会影响主题的确定。有点类似于根据上下文来理解内在含义。
先说下这篇论文,他先介绍了两个分布:层级dirichlet语言模型和LDA,然后想把这两种方法结合起来,提出BTM模型。
概率图:
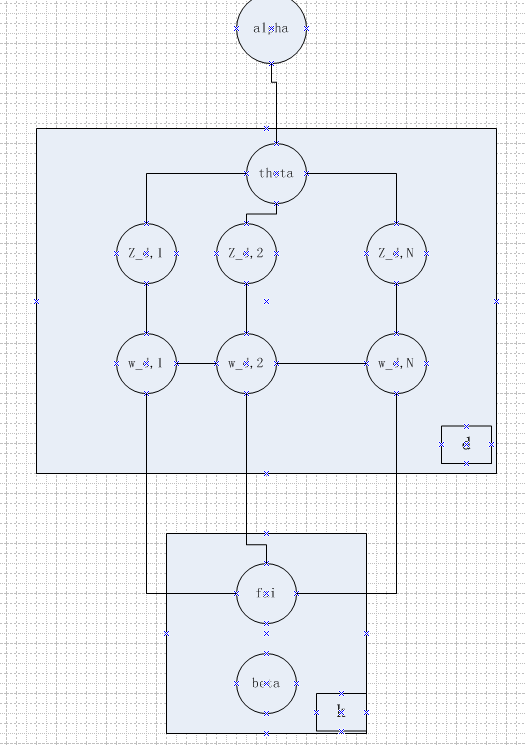
生成过程:
这里公式仍然类似LDA公式,所需要注意的是:
1、词分布的先验:文中有两种假设。一个是
β
外置,即认为所有的词分布共享同一种统计信息,一种是
β
内置,表明同一个词分布下,所有的前一个词不同情况下的当前词分布共享同一信息,其实文中最后提到一点,就是把
β
连同
ϕ
一起内置到文档d中,这个假设更加宽泛,当然计算量更大。
2、超参数是推断出来的,而不是自己设定的
(从结果上看,这种方法可以自动提取出停用词,感觉比较奇怪)
PAM
参考Pachinko Allocation:DAG-Structured Mixture Models of Topic Correlations和Mixtures of Hierarchical Topics with Pachinko
Allocation
这篇文章同样是model主题间的关系,就是为了建模LDA的
θ
部分。他还和很多模型进行了比较。
对于HDP(层级dirichlet过程,是懂非懂囧)首先要定义一个层级结构,每一个层级都和一个DP相关,就是说DP中的基础分布H是采样于上一层的DP。但是要事先定层级。
对于CTM,只是两两关系建模,而且协方差矩阵计算困难。
PAM其实就是用树形结构的全概率有向图来建模主题间的关系。这里以4层PAM为例。
概率图:
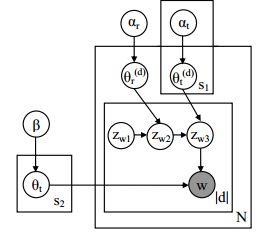
解释:
这里
Zwi
代表第w个词对应的第i层主题,第一层主题就是root,大家都是一样,我认为这里好像没必要这个作为随机量吧。第二层是超级主题,每个超级主题下有S1个子主题,每个子主题概率决定第三层子主题的的生成。















 1473
1473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









