







向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号: datayx
手写汉字脱机识别的困难
手写汉字脱机识别跟印刷汉字识别系统同属光符阅读器OCR的范畴。它们的识别对象都是二维的方块汉字,工作原理相同,系统构成也基本相似,但手写汉字脱机识别问题更多,困难更大。
手写汉字脱机识别为什么那么困难呢?我们认为:最根本的原因是手写汉字的字形变化太大!我国有一句俗语:“人心不同,各如其面”。这句话对手写汉字的字形也完全适用。可以说,不同的人书写的字是千差万别,各不相同,即使是同一个人所写的同一个字,往往也因时、因地而有明显的变化。我们知道,脱机汉字识别的对象是方块汉字的图形,用于识别的特征是根据汉字图形提取的,因而字形变化对识别结果具有决定性的影响。
手写汉字的一些特点:
①基本笔画变化。印刷体汉字的笔画基本上是横平竖直,折笔(乛、乙、く)的拐角大都是尖锐的钝角、锐角或直角,因而折笔基本上可以看做是由折线段所组成。我国手写汉字的笔画大都不具备上述的特点:横不平、竖不直,直笔画变弯,折笔的拐角变为圆弧,等等,例如,“品”字的三个“口”变成三个圆圈,“阝”变成“”;有时把较短的笔画变为“点”,有时则在起笔或折笔的拐角处增加额外的“笔锋”等。
②笔画该连的不连,不该连的相连,这种情况十分普遍。它不是由于干扰等客观原因而产生,主要是由于书写者的习惯而造成的。应,笔画的长短及部件的大小也发生变化。以图4.l(a)的钢笔字帖为例,“担、打、报、择”几个字的偏旁“扌”,其竖笔长短不一,“阳、队、陈、陶”的部首“阝”也大小不同,它们在整字中的位置就有差异。方块汉字字形是一种艺术,书写时要求笔画及部件的形态和相互关系,尽量彼此协调,使整字字形结构匀称美观,因此上述笔画与部件的大小、位置变化,客观上是不可避免的。此外,由于书写者文化水平、习惯等的不同,他们所写的字差别就更大。样本属于比较工整的字样,但字形变化仍相当明显。这说明即使是同一个人写的字也有一定的差异。笔画长短、部首大小及位置等的变化,使我们难以仿照印刷体汉字识别的办法事先确定它们的位置,按规定区域提取笔画或部首特征。
a)一种钢笔字帖的字样;
(b)我国IAAS-4M手写标准汉字库字样;
(c)一般的手写字字样
上面讨论的几种手写字样大体上都是比较工整的楷书,它们字形尚有明显的差别,更何况日常见到的各种手稿或书信中的字,其差别会更大。我国主要的手写字体有楷书、行书和草书三种,如图4.2所示。可以看出,同一个字的笔画和字形几乎迥然不同,相差甚远。草书的字甚至文化较高的人有时也不认识,要求计算机能自动识别这样的手写字显然是不可能,也是不合理的。
因此,对用于计算机自动识别的手写汉字应有所要求。具体地说,对构成汉字的笔画及其相互关系,应有必要的规定和限制,不能无约束地随意书写。这种字叫做“限制性手写汉字”。显然,这种限制不能太严,规定不能过于复杂,否则用户难以适应,识别系统也不容易推广应用。另一方面,对书写的要求也不宜太宽,否则难以使系统具有足够高识别率。这是一个不容易解决的矛盾。通常对书写的基本要求有如下几点:
①书写工整,笔画横平竖直,粗细均匀;
②不同笔画不连笔书写,联机识别时,应按常规笔顺书写。
③每个字符应写在规定方格内(通常为6mm×6mm~12mm×12mm),字符大小尽量一致,笔画不应超出方格。
上述要求并不复杂,但实际上很难完全做到,即使是文化水平较高的人,除非曾经受过书写工程字的训练,否则也不易按上述规定自始至终地书写。这就是手写字符识别的困难所在。
开源项目
CRNN(CNN+RNN+CTCLoss)
完整代码 以及预训练模型 获取方式:
关注微信公众号 datayx 然后回复 汉字识别 即可获取。
如何去测试
1.加载模型,将模型放入./model/中
2.向test_img_list中添加需要测试的图片列表
test_img_list = ['/home/tony/ocr/test_data/00023.jpg'
]
3.运行模型
python3 test_crnn.py如何去train
1.处理train 数据集
python3 ./utils/make_data.py2.训练网络
python3 train.py
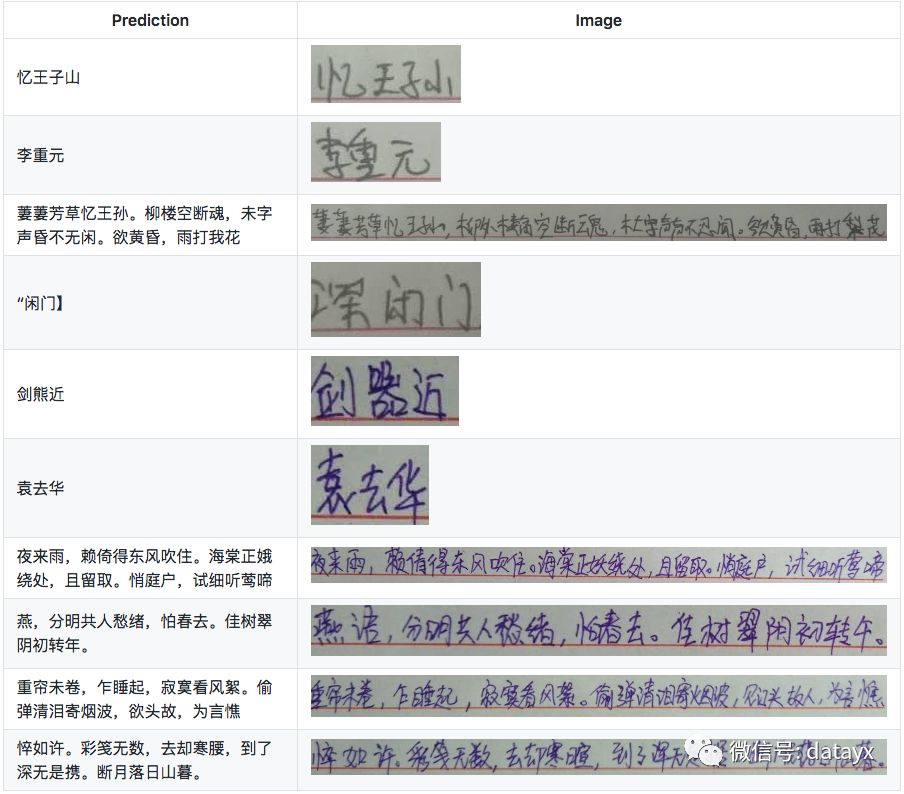
效果展示
阅读过本文的人还看了以下:
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

长按图片,识别二维码,点关注
















 4461
4461











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









