







向AI转型的程序员都关注了这个号👇👇👇
在轩辕系列大模型研发过程中,我们积累了大量的高质量数据和模型训练经验,构建了完善的训练平台,搭建了合理的评估流水线。在此基础上,为丰富轩辕系列模型矩阵,降低轩辕大模型使用门槛,我们进一步推出了XuanYuan-6B系列大模型。不同于XuanYuan-13B和XuanYuan-70B系列模型在LLaMA2上继续预训练的范式,XuanYuan-6B是我们从零开始进行预训练的大模型。当然,XuanYuan-6B仍采用类LLaMA的模型架构。在预训练基础上,我们构建了丰富、高质量的问答数据和人类偏好数据,并通过指令微调和强化学习进一步对齐了模型表现和人类偏好,显著提升了模型在对话场景中的表现。XuanYuan6B系列模型在多个评测榜单和人工评估中均获得了亮眼的结果。模型训练细节请参考我们的技术报告。
项目开源代码获取地址:
关注微信公众号 datayx 然后回复 度小满 即可获取。
本次开源的XuanYuan-6B系列模型包含基座模型XuanYuan-6B,经指令微调和强化对齐的chat模型XuanYuan-6B-Chat,以及chat模型的量化版本XuanYuan-6B-Chat-4bit和XuanYuan-6B-Chat-8bit。
主要特点:
收集多个领域大量的训练语料,进行了多维度数据清洗和去重,保证数据的量级和质量
从零开始预训练,预训练中动态调整数据配比,模型基座能力较强
结合Self-QA方法构建高质量问答数据,采用混合训练方式进行监督微调
构建高质量人类偏好数据训练奖励模型并进行强化训练,对齐模型表现和人类偏好
模型尺寸小并包含量化版本,硬件要求低,适用性更强
在多个榜单和人工评估中均展现出良好的性能,具备领先的金融能力
性能评测
基础评测
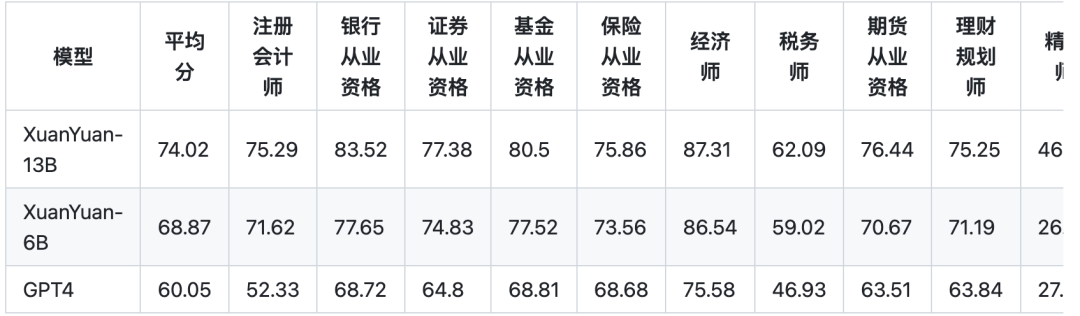
金融一直是轩辕大模型重点关注的领域和主要应用目标,因此我们首先在金融场景评测了XuanYuan-6B模型。我们使用自己构建并开源的FinanceIQ数据集,该数据集是一份专业的大模型金融能力评估数据集,涵盖了10个金融大类,36个金融小类,总计7173题。评估结果如下表所示。从表中可以看出,XuanYuan-6B模型在该评估数据中的性能甚至超越了GPT4,显示出了其强大的金融能力。
除金融外,我们也注重轩辕大模型的通用能力,因此我们也在多个主流评测集上进行了模型评测,观察轩辕大模型在知识、逻辑、代码等通用能力上的表现。评测结果如下表所示。
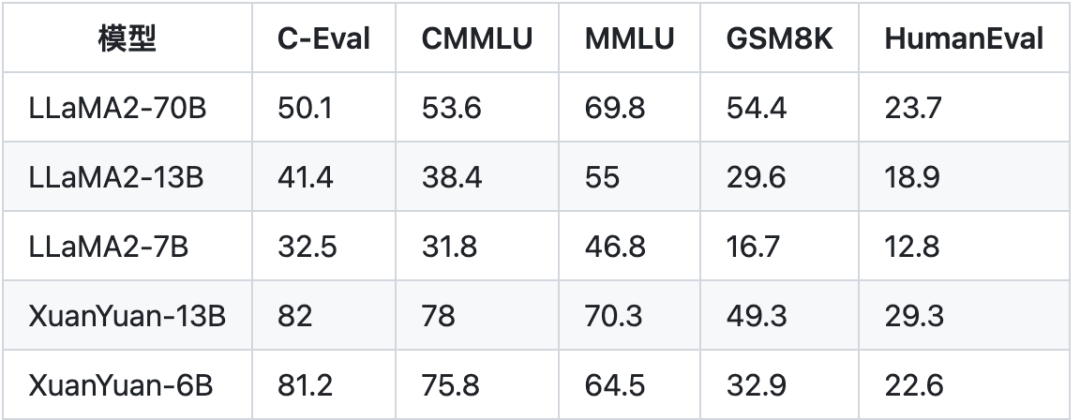
从表中结果可以看出,在五个评测集上,XuanYuan-6B的表现均超越了类似尺寸的LLaMA2-7B和LLaMA2-13B模型,展现出了强大的通用能力。在中文相关场景下,XuanYuan-6B甚至可超越更大尺寸的LLaMA2-70B模型。
值得注意的是,在上述所有评测中,XuanYuan-6B均进行了考试场景增强,具体细节可见我们的技术报告。另外榜单结果也不代表模型在真实场景中的实际能力。为进一步验证模型的实际能力,我们对模型进行了人工评测。
人工评测
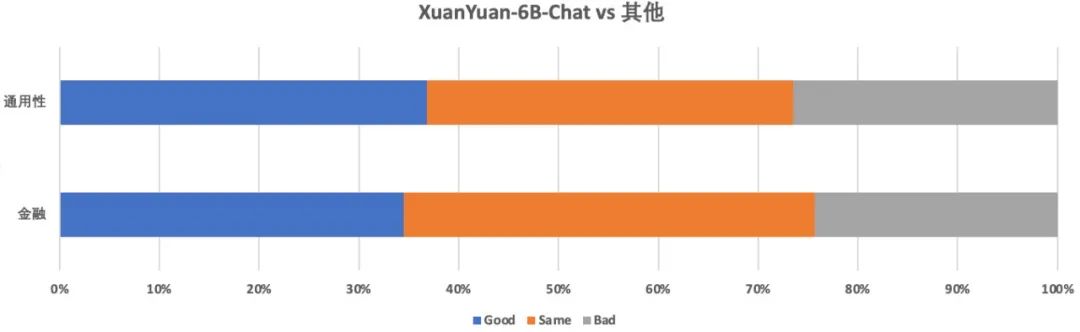
除在各榜单进行评测外,我们进一步对XuanYuan-6B-Chat模型进行了人工评估,来公正客观地评估chat模型在对话场景中的真实能力。评估集包含一定量级的问题且对研发人员完全封闭,每个问题均由三个不同的人员进行评估来减轻偏见。评估对比对象为业界开源的类似尺寸的主流大模型,我们并采用GSB(Good,Same,Bad)指标来展示评估结果,具体结果如下图所示。从图中可以看出,在通用性(安全性在评估时被纳入了通用性)和金融能力上,XuanYuan-6B-Chat模型均超过了对比对象,显示出更强的模型能力。
推理部署
XuanYuan-6B系列模型均已上传到HuggingFace和modelscope网站,请点击上述链接进行下载。XuanYuan-6B基座模型、chat模型及其量化模型的使用方法和XuanYuan-70B,XuanYuan2-70B类似,但是tokenizer加载方式和在对话场景中使用的prompt格式不同(不包含system message)。下面以XuanYuan-6B-Chat模型为例,来展示XuanYuan-6B系列模型的使用方法。

XuanYuan-13B
介绍
最懂金融领域的开源大模型“轩辕”系列,继176B、70B之后推出更小参数版本——XuanYuan-13B。这一版本在保持强大功能的同时,采用了更小的参数配置,专注于提升在不同场景下的应用效果。同时,我们也开源了XuanYuan-13B-Chat模型的4bit和8bit量化版本,降低了硬件需求,方便在不同的设备上部署。
主要特点:
“以小搏大”的对话能力:在知识理解、创造、分析和对话能力上,可与千亿级别的模型相媲美
金融领域专家:在预训练和微调阶段均融入大量金融数据,大幅提升金融领域专业能力。在金融知识理解、金融业务分析、金融内容创作、金融客服对话几大方面展示出远超一般通用模型的优异表现
人类偏好对齐:通过人类反馈的强化学习(RLHF)训练,在通用领域和金融领域均与人类偏好进行对齐
模型训练与创新
在模型训练中,团队在模型预训练阶段动态调整不同语种与领域知识的比例,融入了大量的专业金融语料,并在指令微调中灵活运用之前提出的Self-QA和混合训练方法,显著提升了模型在对话中的性能表现。此外,本次“轩辕13B”还通过强化学习训练,与人类偏好进行对齐。相比于原始模型,RLHF对齐后的模型,在文本创作、内容生成 、指令理解与遵循、安全性等方面都有较大的提升。
通用评测
XuanYuan-13B在各评测集(通用评测、金融评测)上的结果已在XuanYuan-6B的评测内容中给出,请参考。从评测结果来看,XuanYuan-13B具备很强的通用能力和金融能力,其性能甚至可比肩更大尺寸的模型,做到了以小搏大。和XuanYuan-6B类似,XuanYuan-13B在评测中也进行了考试场景优化。此外,由于评测集是固定且有限的,因此相关评测结果并不完全代表模型的真实能力。
除在固定测试集进行评估外,我们非常关注模型在实际对话中的能力,组建专业的人工评测团队将XuanYuan-13B与其他开源系列的70B左右参数模型进行GSB比较,结果显示:在通用评测中的绝大部分指标,XuanYuan-13B都可以与其他开源系列的70B左右参数模型相媲美。
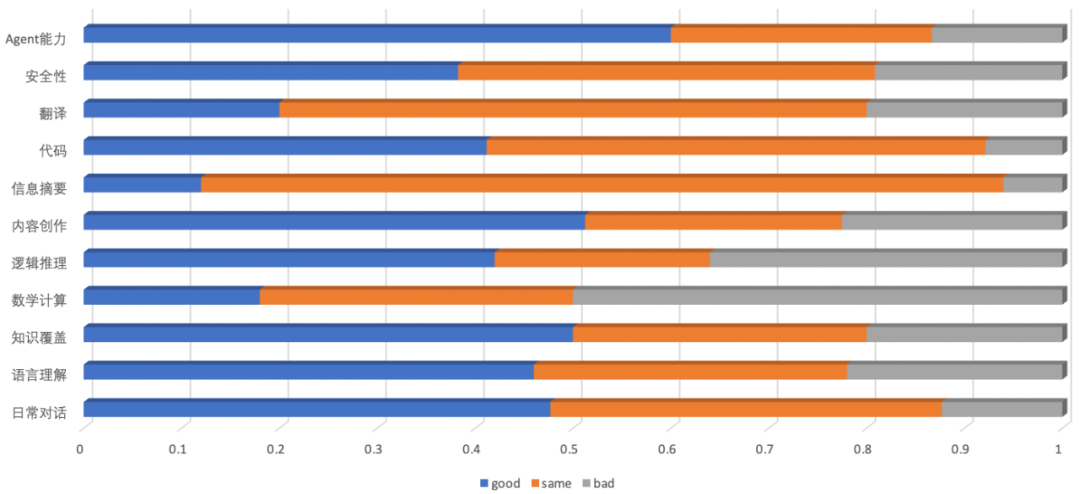
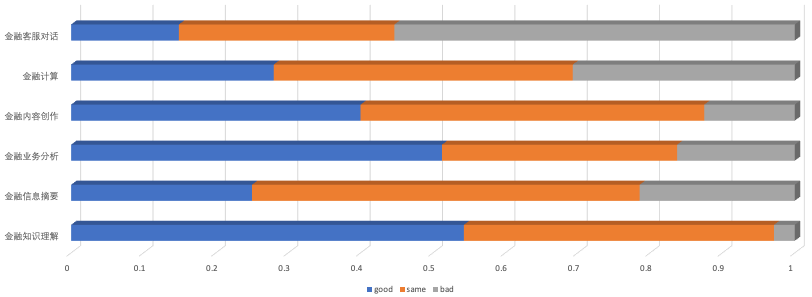
金融评测
XuanYuan-13B在金融评测也表现出极高的水平,以小博大获得了很好的表现。金融的主要评测指标如下(轩辕vs其他):
推理部署
XuanYuan-13B的Chat模型已发布在Hugging Face,请根据上述的链接进行下载。下面我们给出Chat模型的推理部署使用方法。



















输出:根据所提供的财务报表,可以分析销售毛利占销售额的比例增加对公司盈利能力的影响。
毛利率的提高:报告中提到,第三季度的毛利率从上年同期的19.9%增至22.2%,增长了2.3个百分点。这意味着公司在销售商品或提供服务时,每单位的销售收入中,有更多的部分可以转化为毛利。这是一个积极的信号,因为它表明公司在控制成本和提高效率方面取得了进展。
毛利率提高的原因:报告指出,毛利率的提高主要归因于建筑玻璃的定价更高,店面和安装业务的增长对利润率的影响,更好的项目组合以及公司所有业务的良好运营表现。这些因素表明公司在市场上具有竞争优势,能够通过提高产品价格或改进业务流程来提高毛利率。
对盈利能力的影响:销售毛利占销售额的比例是衡量公司盈利能力的一个重要指标。随着毛利率的提高,公司的盈利能力也会相应提高。这意味着公司能够在销售额不变的情况下,获得更多的利润,或者在保持利润水平的情况下,实现更高的销售额。
其他因素:尽管毛利率的提高是积极的信号,但还需要考虑其他因素,如销售、总务和行政开支的增加。报告中指出,这些开支的增加主要是由于激励和长期高管薪酬计划的支出增加,以及公司继续投资于新产品、市场和地理区域。这些开支的增加可能会对公司的盈利能力产生负面影响。
综上所述,销售毛利占销售额的比例增加通常会提高公司的盈利能力。然而,还需要考虑其他因素,如销售、总务和行政开支的增加,以及市场竞争等因素。投资者可以通过进一步分析这些因素来评估公司的整体盈利能力和未来发展潜力。
机器学习算法AI大数据技术
搜索公众号添加: datanlp

长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









