







在流数据处理应用中,一个很重要、也很常见的操作就是窗口计算。所谓的“窗口”,一 般就是划定的一段时间范围,也就是“时间窗”;对在这范围内的数据进行处理,就是所谓的 窗口计算。所以窗口和时间往往是分不开的。
时间语义
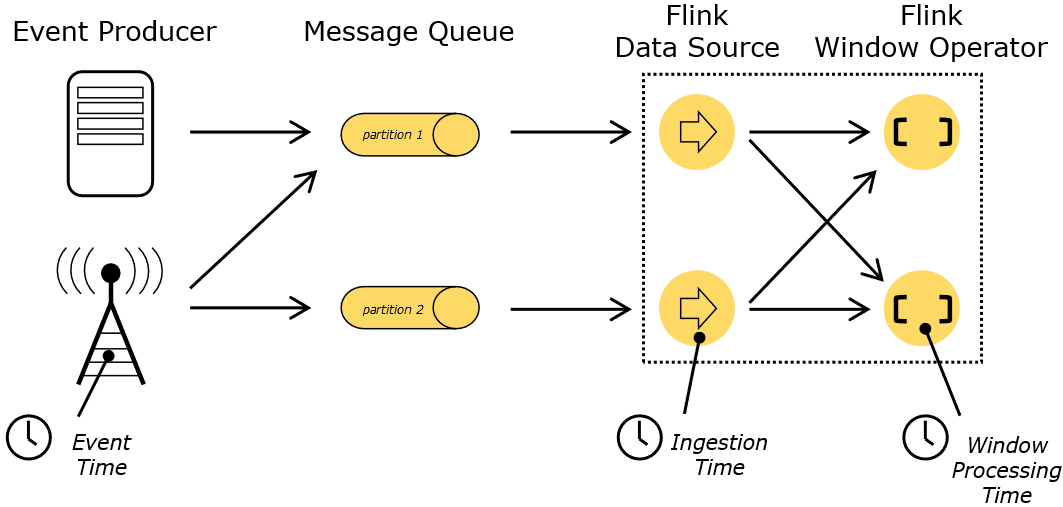
- 事件时间(Event Time):每个事件在对应的设备上发生的时间,也就是数据生成的时间。
- 处理时间(Processing Time):执行处理操作的机器的系统时间
- 摄取时间(Ingestion Time):事件进入到flink的时间
哪种 时间语义更重要
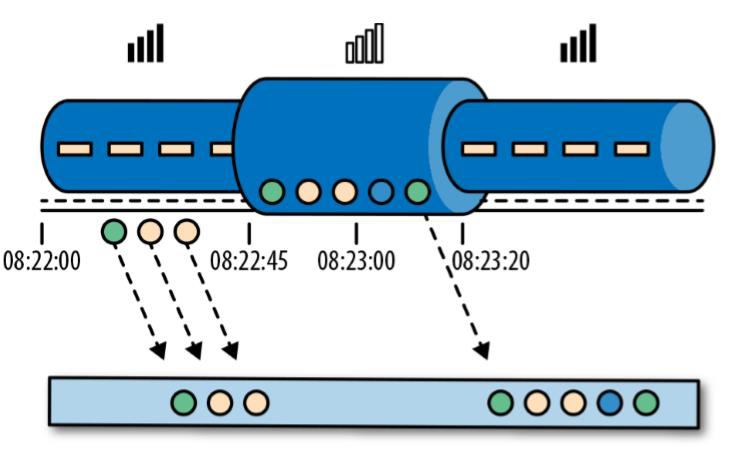
一般情况下,业务日志数据中都会记录数据生成的时间戳,它就可以作为事件时间的判断基础。处理时间是我们计算效率的衡量标准,而事件事件更符合我们的业务计算逻辑。而处理时间是我们计算效率的衡量标准,由于没有任何附加考虑,数据一来就直接处理,因此这种方式可以让流处理延迟降到最低,效率达到最高。
flink1.13版本开始,将事件时间作为默认的时间语义。
水位线(Watermark)
什么是水位线
在事件时间语义下,我们不依赖系统时间,而是基于数据自带的时间戳去定义了一个时钟,用来表示当前时间的进展。于是每个并行子任务都会有一个自己的逻辑时钟,它的前进是靠数据的时间戳来驱动的。
我们可以把时钟也以数据的形式传递出去,告诉下游任务当前时间的进展;而且这个时钟的传递不会因为窗口聚合之类的运算而停滞。一种简单的想法是,在数据流中加入一个时钟标记,记录当前的事件时间;这个标记可以直接广播到下游,当下游任务收到这个标记,就可以更新自己的时钟了。由于类似于水流中用来做标志的记号,在 Flink 中,这种用来衡量事件时间(Event Time)进展的标记,就被称作“水位线”(Watermark)。
具体实现上,水位线可以看作一条特殊的数据记录,它是插入到数据流中的一个标记点,主要内容就是一个时间戳,用来指示当前的事件时间。而它插入流中的位置,就应该是在某个数据到来之后;这样就可以从这个数据中提取时间戳,作为当前水位线的时间戳了。
watermark特点
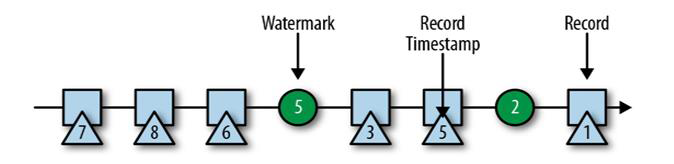
- 水位线时插入到数据流中的一个标记,可以认为是一个特殊的数据
- 水位线主要的内容是一个时间戳,用来表示当前事件时间的进展
- 水位线时基于数据的时间戳生成的
- 水位线的时间戳必须单调递增,以保证正确处理乱序数据
- 一个水位线表示在当前流中事件时间已经达到了时间戳
t,t之前的所有数据都到齐了,之后流中不会出现时间戳t'<t的数据
总结起来,水位线(watermark)在Flink中的作用是用于处理乱序事件流,确保事件按照正确的顺序进行处理,以便进行准确的窗口计算和延迟处理。也就是, 牺牲掉一定的实时性,为了保证数据的完整性。
水位线的传递
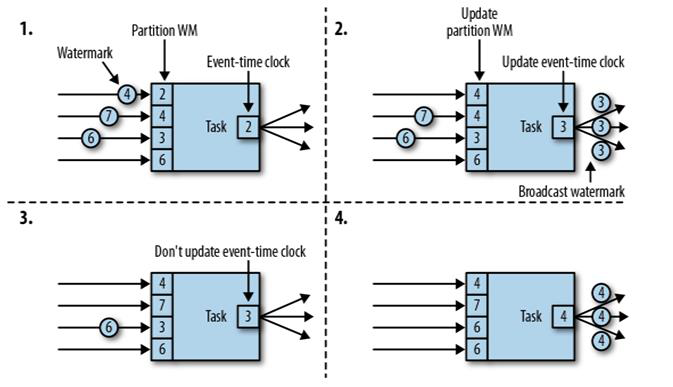
在 Flink 的数据流处理中,水位线是以特定的事件元素形式插入到数据流中的。这个特殊的事件元素被称为水位线事件(Watermark Event),它包含了水位线的时间戳信息。当数据流中的水位线事件到达算子(Operator)时,Flink 会根据其时间戳更新当前的水位线。
在源算子(Source Operator)中,可以通过调用特定的方法(如assignTimestampsAndWatermarks)来插入水位线事件。这样,在源算子产生的数据流中就会包含水位线事件,以及普通的数据事件。
然后,水位线事件会随着数据流在不同的算子之间进行传递。当算子处理数据时,它会检查接收到的事件的时间戳,并与当前水位线进行比较。如果事件的时间戳大于当前水位线,算子会更新水位线,并触发相应的操作。
在“重分区”的传输模式下,一个任务有可能会收到来自不同分区上游子任务的数据。而不同分区的子任务时钟并不同步,这时我们应该以最慢的那个时钟,也就是最小的水位线为准。
水位线在上下游任务之间的传递,非常巧妙的避免了分布式系统中没有统一时钟的问题,每个任务都以“处理完之前所有数据”为标准来确定自己的时钟,就可以保证窗口处理的结果总是正确的。
如何生成水位线
生成水位线的总体原则
如果我们希望计算结果能更加准确,那可以将水位线的延迟设置得更高一些,等待的时间越长,自然也就越不容易漏掉数据。不过这样做的代价是处理的实时性降低了,我们可能为极少数的迟到数据增加了很多不必要的延迟。如果我们希望处理得更快、实时性更强,那么可以将水位线延迟设得低一些。这种情况下,可能很多迟到数据会在水位线之后才到达,就会导致窗口遗漏数据,计算结果不准确。
所以 Flink 中的水位线,其实是流处理中对低延迟和结果正确性的一个权衡机制,而且把控制的权力交给了程序员,我们可以在代码中定义水位线的生成策略。
水位线生成策略(Watermark Strategies)
在 Flink 的 DataStream API 中 , 有 一 个 单 独 用 于 生 成 水 位 线 的 方 法 :assignTimestampsAndWatermarks(),它主要用来为流中的数据分配时间戳,并生成水位线来指示事件时间。
assignTimestampsAndWatermarks()方法需要传入一个 WatermarkStrategy 作为参数,这就是 所谓的“水位线生成策略”。WatermarkStrategy 中包含了一个“时间戳分配器”TimestampAssigner 和一个“水位线生成器”WatermarkGenerator。
TimestampAssigner: 由 WatermarkStrategy 显示地指定从数据里面哪一个字段提取当前的时间戳,然后把它分配到当前的数据上。 就相当于再数据上追加了一个字段,这个字段是真正的 timestamp。它有可能和之前某个字段一样,也可能基于之前的字段做了一定的改变。
**时间戳的分配是生成水位线的基础。**基于时间戳,我们可以指定水位线生成策略
WatermarkGenerator。
WatermarkGenerator: 主要负责按照既定的方式,基于时间戳生成水位线。在 WatermarkGenerator 接口中,主要又有两个方法:onEvent()和 onPeriodicEmit()。
onEvent:基于事件生成 watermark 。onPeriodicEmit:基于周期性的发射生成watermark。默认200ms
Flink 内置水位线生成器
有序流
对于有序流,主要特点就是时间戳单调增长(Monotonously Increasing Timestamps),所以 永远不会出现迟到数据的问题。这是周期性生成水位线的最简单的场景,直接调用.
val stream = env.addSource(new ClickSource)
.assignTimestampsAndWatermarks(
WatermarkStrategy.forMonotonousTimestamps[Event]()
.withTimestampAssigner(new SerializableTimestampAssigner[Event]
{
override def extractTimestamp(element: Event, recordTimestamp: Long): Long = {
element.timestamp
}
}
)
)
乱序流
由于乱序流中需要等待迟到数据到齐,所以必须设置一个固定量的延迟时间(Fixed Amount of Lateness)。这时生成水位线的时间戳,就是当前数据流中最大的时间戳减去延迟的 结果,相当于把表调慢,当前时钟会滞后于数据的最大时间戳。调用 WatermarkStrategy.forBoundedOutOfOrderness()方法就可以实现。这个方法需要传入一个 maxOutOfOrderness 参 数,表示“最大乱序程度”,它表示数据流中乱序数据时间戳的最大差值;如果我们能确定乱序 程度,那么设置对应时间长度的延迟,就可以等到所有的乱序数据了。
val stream1 = env.addSource(new ClickSource)
//插入水位线的逻辑
.assignTimestampsAndWatermarks(
//针对乱序流插入水位线,延迟时间设置为 5s
WatermarkStrategy
.forBoundedOutOfOrderness[Event](Duration.ofSeconds(5))
.withTimestampAssigner(
new SerializableTimestampAssigner[Event]
{
override def extractTimestamp(element: Event, recordTimestamp: Long): Long = element.timestamp
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









