







 本文详细介绍了Flink1.13的DataStream API,包括执行环境创建、执行模式(流执行、批执行和自动模式)、数据源(Socket、Kafka、自定义Source)和转换算子(map、filter、flatMap、聚合)。重点讲述了水位线(Watermark)和窗口(时间窗口、计数窗口、滑动窗口、会话窗口)的概念、生成策略和使用,强调了处理乱序数据的重要性。最后,讨论了迟到数据的处理方法,包括水位线延迟、允许迟到时间和侧输出流。
本文详细介绍了Flink1.13的DataStream API,包括执行环境创建、执行模式(流执行、批执行和自动模式)、数据源(Socket、Kafka、自定义Source)和转换算子(map、filter、flatMap、聚合)。重点讲述了水位线(Watermark)和窗口(时间窗口、计数窗口、滑动窗口、会话窗口)的概念、生成策略和使用,强调了处理乱序数据的重要性。最后,讨论了迟到数据的处理方法,包括水位线延迟、允许迟到时间和侧输出流。
文章目录
- 第五章 DataStreamAPI(基础篇)
- 第六章 Flink中的时间和窗口
第五章 DataStreamAPI(基础篇)
一个 Flink 程序,其实就是对 DataStream 的各种转换。具体来说,代码基本上都由以下几
部分构成
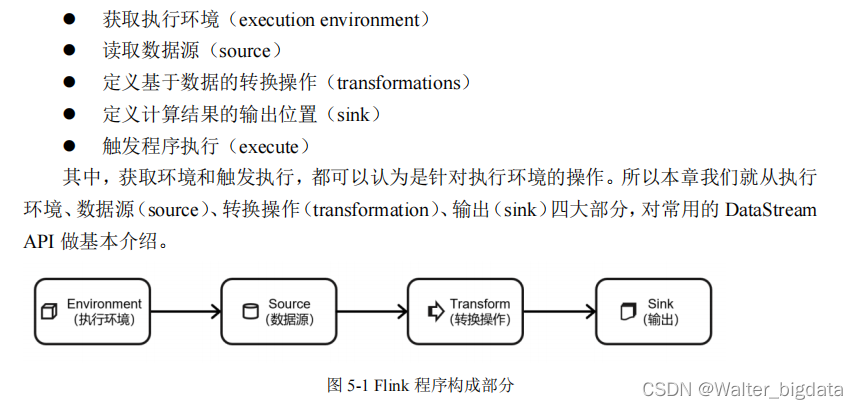
5.1 执行环境(Execution Environment)
5.1.1 创建执行环境
Flink 程序可以在各种上下文环境中运行:我们可以在本地 JVM 中执行程序,也可以提交
到远程集群上运行。
不同的环境,代码的提交运行的过程会有所不同。这就要求我们在提交作业执行计算时,
首先必须获取当前 Flink 的运行环境,从而建立起与 Flink 框架之间的联系。只有获取了环境
上下文信息,才能将具体的任务调度到不同的 TaskManager 执行。
1.getExecutionEnvironment
最简单的方式,就是直接调用 getExecutionEnvironment 方法。它会根据当前运行的上下文
直接得到正确的结果:如果程序是独立运行的,就返回一个本地执行环境;如果是创建了 jar
包,然后从命令行调用它并提交到集群执行,那么就返回集群的执行环境。也就是说,这个方
法会根据当前运行的方式,自行决定该返回什么样的运行环境。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
这种“智能”的方式不需要我们额外做判断,用起来简单高效,是最常用的一种创建执行
环境的方式。
2.createLocalEnvironment
这个方法返回一个本地执行环境。可以在调用时传入一个参数,指定默认的并行度;如果
不传入,则默认并行度就是本地的 CPU 核心数。
StreamExecutionEnvironment localEnv = StreamExecutionEnvironment.createLocalEnvironment();
3.createRemoteEnvironment
这个方法返回集群执行环境。需要在调用时指定 JobManager 的主机名和端口号,并指定
要在集群中运行的 Jar 包。
StreamExecutionEnvironment remoteEnv = StreamExecutionEnvironment
.createRemoteEnvironment(
"host", // JobManager 主机名
1234, // JobManager 进程端口号
"path/to/jarFile.jar" // 提交给 JobManager 的 JAR 包
);
在获取到程序执行环境后,我们还可以对执行环境进行灵活的设置。比如可以全局设置程
序的并行度、禁用算子链,还可以定义程序的时间语义、配置容错机制。关于时间语义和容错
机制,我们会在后续的章节介绍。
5.1.2 执行模式(Execution Mode)
上节中我们获取到的执行环境,是一个 StreamExecutionEnvironment,顾名思义它应该是
做流处理的。那对于批处理,又应该怎么获取执行环境呢?
在之前的 Flink 版本中,批处理的执行环境与流处理类似,是调用类 ExecutionEnvironment
的静态方法,返回它的对象:

基于 ExecutionEnvironment 读入数据创建的数据集合,就是 DataSet;对应的调用的一整
套转换方法,就是 DataSet API。这些我们在第二章的批处理 word count 程序中已经有了基本
了解。
而从 1.12.0 版本起,Flink 实现了 API 上的流批统一。DataStream API 新增了一个重要特
性:可以支持不同的“执行模式”(execution mode),通过简单的设置就可以让一段 Flink 程序
在流处理和批处理之间切换。这样一来,DataSet API 也就没有存在的必要了。
1.流执行模式(STREAMING)
这是 DataStream API 最经典的模式,
一般用于需要持续实时处理的无界数据流。默认情况下,程序使用的就是 STREAMING 执行模式。
2.批执行模式(BATCH)
专门用于批处理的执行模式, 这种模式下,Flink 处理作业的方式类似于 MapReduce 框架。
对于不会持续计算的有界数据,我们用这种模式处理会更方便。
2.1 BATCH 模式的配置方法
由于 Flink 程序默认是 STREAMING 模式,我们这里重点介绍一下 BATCH 模式的配置。
主要有两种方式:
(1)通过命令行配置
bin/flink run -Dexecution.runtime-mode=BATCH ...
在提交作业时,增加 execution.runtime-mode 参数,指定值为 BATCH。
(2)通过代码配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
在代码中,直接基于执行环境调用 setRuntimeMode 方法,传入 BATCH 模式。
建议: 不要在代码中配置,而是使用命令行。这同设置并行度是类似的:在提交作业时指
定参数可以更加灵活,同一段应用程序写好之后,既可以用于批处理也可以用于流处理。而在
代码中硬编码(hard code)的方式可扩展性比较差,一般都不推荐。
2.2 什么时候选择 BATCH 模式
我们知道,Flink 本身持有的就是流处理的世界观,即使是批量数据,也可以看作“有界
流”来进行处理。
所以 STREAMING 执行模式对于有界数据和无界数据都是有效的;而 BATCH模式仅能用于有界数据。
看起来 BATCH 模式似乎被 STREAMING 模式全覆盖了,那还有必要存在吗?我们能不
能所有情况下都用流处理模式呢?
当然是可以的,但是这样有时不够高效。
我们可以仔细回忆一下 word count 程序中,批处理和流处理输出的不同:在 STREAMING
模式下,每来一条数据,就会输出一次结果(即使输入数据是有界的);而 BATCH 模式下,
只有数据全部处理完之后,才会一次性输出结果。最终的结果两者是一致的,但是流处理模式会将更多的中间结果输出。在本来输入有界、只希望通过批处理得到最终的结果的场景下,
STREAMING 模式的逐个输出结果就没有必要了。
所以总结起来,一个简单的原则就是:用 BATCH 模式处理批量数据,用 STREAMING
模式处理流式数据。因为数据有界的时候,直接输出结果会更加高效;而当数据无界的时候, 我
们没得选择——只有 STREAMING 模式才能处理持续的数据流。
当然,在后面的示例代码中,即使是有界的数据源,我们也会统一用 STREAMING 模式
处理。这是因为我们的主要目标还是构建实时处理流数据的程序,有界数据源也只是我们用来
测试的手段。
3.自动模式(AUTOMATIC)
在这种模式下,将由程序根据输入数据源是否有界,来自动选择执行模式。
5.1.3 触发程序执行
有了执行环境,我们就可以构建程序的处理流程了:基于环境读取数据源,进而进行各种
转换操作,最后输出结果到外部系统。
需要注意的是,写完输出(sink)操作并不代表程序已经结束。因为当 main()方法被调用
时,其实只是定义了作业的每个执行操作,然后添加到数据流图中;这时并没有真正处理数据
——因为数据可能还没来。Flink 是由事件驱动的,只有等到数据到来,才会触发真正的计算,
这也被称为“延迟执行”或“懒执行”(lazy execution)。
所以我们需要显式地调用执行环境的 execute()方法,来触发程序执行。execute()方法将一
直等待作业完成,然后返回一个执行结果(JobExecutionResult)。
env.execute();
5.2 源算子(Source)
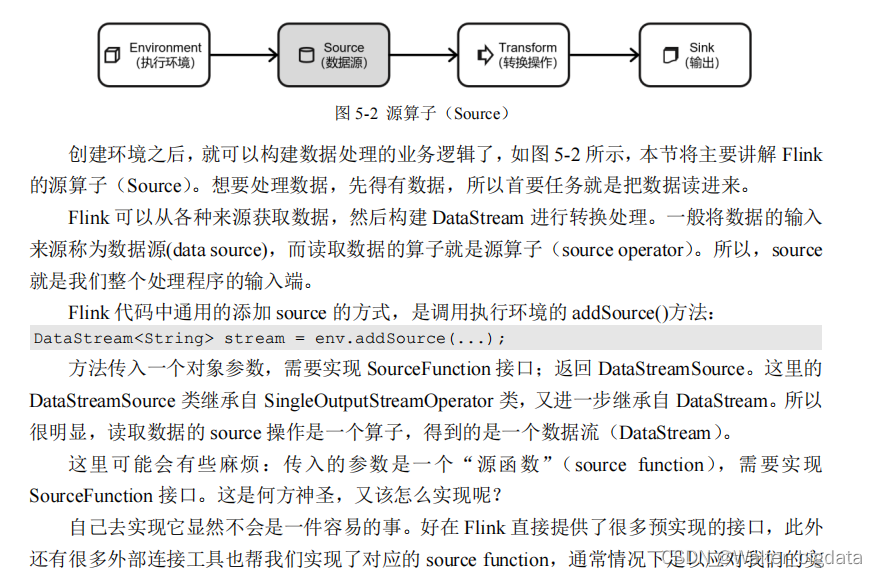
5.2.1 准备工作
import java.sql.Timestamp;
public class Event {
public String user;
public String url;
public Long timestamp;
public Event() {
}
public Event(String user, String url, Long timestamp) {
this.user = user;
this.url = url;
this.timestamp = timestamp;
}
@Override
public String toString() {
return "Event{" +
"user='" + user + '\'' +
", url='" + url + '\'' +
", timestamp=" + new Timestamp(timestamp) +
'}';
} }

5.2.2 读取有界流数据(从文本、集合、元素中读取)
最简单的读取数据的方式,就是在代码中直接创建一个 Java 集合,然后调用执行环境的
fromCollection 方法进行读取。这相当于将数据临时存储到内存中,形成特殊的数据结构后,
作为数据源使用,一般用于测试。
package com.scy.chapter01;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.ArrayList;
public class SourceTest {
public static void main(String[] args) throws Exception {
//创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.从文件中读取有界数据(仅用于测试将数据读取内存作为数据源)
DataStreamSource<String> stream1 = env.readTextFile("input/clicks.txt");
//2.从集合中读取数据(仅用于测试将数据读取内存作为数据源)
ArrayList<Integer> nums = new ArrayList<>();
nums.add(2);
nums.add(5);
DataStreamSource<Integer> numstream = env.fromCollection(nums);
ArrayList<Event> events = new ArrayList<>();
events.add(new Event("mary","./home",1000L));
events.add(new Event("bob","./cart",2000L));
DataStreamSource<Event> stream2 = env.fromCollection(events);
//3.从元素读取数据(仅用于测试将数据读取内存作为数据源)
DataStreamSource<Event> stream3 = env.fromElements(
new Event("mary", "./home", 1000L),
new Event("bob", "./cart", 2000L)
);
stream1.print("1");
numstream.print("nums");
stream2.print("2");
stream3.print("3");
env.execute();
}
}
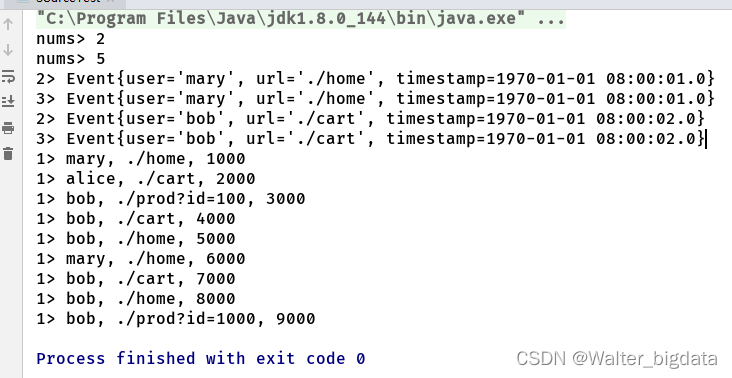
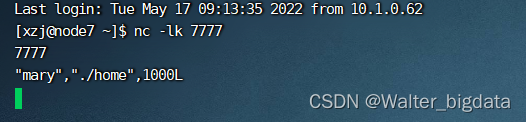
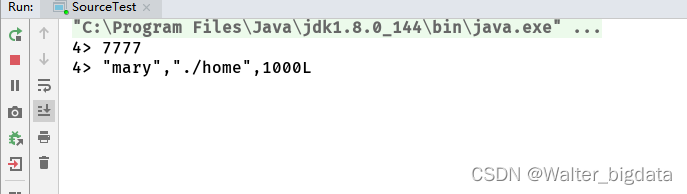
5.2.3 从socket读取流数据
package com.scy.chapter01;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.ArrayList;
public class SourceTest {
public static void main(String[] args) throws Exception {
//创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//4.从socket文本流中读取数据
DataStreamSource<String> stream4 = env.socketTextStream("node7", 7777);
stream4.print("4");
env.execute();
}
}
5.2.4 从Kafka读取流数据(重点)

<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
然后调用 env.addSource(),传入 FlinkKafkaConsumer 的对象实例就可以了。
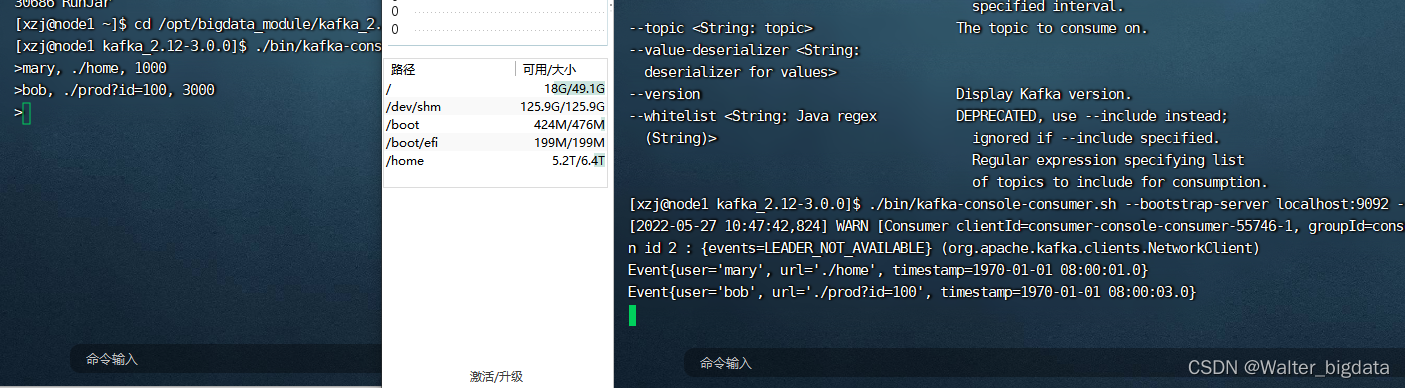
kafka创建clicks生产者
[xzj@node1 kafka_2.12-3.0.0]$ ./bin/kafka-console-producer.sh --broker-list node1:9092 --topic clicks
package com.scy.chapter01;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.ArrayList;
import java.util.Properties;
public class SourceTest {
public static void main(String[] args) throws Exception {
//创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//5.从Kafka中读取数据
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","node1:9092");
properties.setProperty("group.id", "consumer-group");
properties.setProperty("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("auto.offset.reset", "latest");
DataStreamSource<String> kafkaStream = env.addSource(new FlinkKafkaConsumer<String>("clicks", new SimpleStringSchema(), properties));
kafkaStream.print();
env.execute();
}
}

5.2.5 自定义Source(一般用于测试)
package com.scy.chapter01;
import java.sql.Timestamp;
public class Event {
public String user;
public String url;
public Long timestamp;
public Event() {
}
public Event(String user, String url, Long timestamp) {
this.user = user;
this.url = url;
this.timestamp = timestamp;
}
@Override
public String toString() {
return "Event{" +
"user='" + user + '\'' +
", url='" + url + '\'' +
", timestamp=" + new Timestamp(timestamp) +
'}';
}
}
1.自定义数据源
package com.scy.chapter01;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import java.util.Calendar;
import java.util.Random;
public class ClickSource implements SourceFunction<Event> {
//声明一个标志位
private Boolean running = true;
@Override
public void run(SourceContext<Event> ctx) throws Exception {
//随机生成数据
Random random = new Random();
//定义字段选取的数据集
String[] users = {"mary","alice","bob","cary"};
String[] urls ={"./home","./cart","./fav","./prod?id=100","./prod?id=200"};
//循环不停的生成数据
while (running){
String user = users[random.nextInt(users.length)];
String url = urls[random.nextInt(urls.length)];
Long timestamp = Calendar.getInstance().getTimeInMillis();
ctx.collect(new Event(user,url,timestamp));
Thread.sleep(1000L);
}
}
@Override
public void cancel() {
running = false;
}
}
2.打印自定义数据源产生的随机数据
package com.scy.chapter01;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SourceCustomTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> customStream = env.addSource(new ClickSource());
customStream.print();
env.execute();
}
}
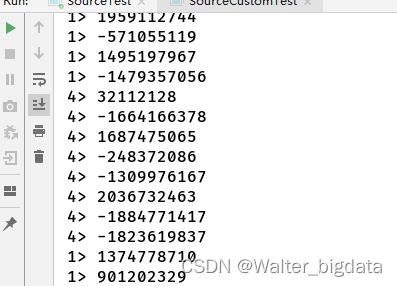
5.2.6 自定义并行Source(一般用于测试)
package com.scy.chapter01;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;
import java.util.Random;
public class SourceCustomTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
// DataStreamSource<Event> customStream = env.addSource(new ClickSource());
DataStreamSource<Integer> customStream = env.addSource(new ParallelCustomSource()).setParallelism(2);
customStream.print();
env.execute();
}
//实现自定义并行的SourceFunction
private static class ParallelCustomSource implements ParallelSourceFunction<Integer> {
private boolean running = true;
private Random random = new Random();
@Override
public void run(SourceContext<Integer> ctx) throws Exception {
while (running){
ctx.collect(random.nextInt());
}
}
@Override
public void cancel() {
running = false;
}
}
}
5.2.7 Flink 支持的数据类型
1.Flink 的类型系统

2.Flink 支持的数据类型
简单来说,对于常见的 Java 和 Scala 数据类型,Flink 都是支持的。Flink 在内部,Flink
对支持不同的类型进行了划分,这些类型可以在 Types 工具类中找到:
(1)基本类型
所有 Java 基本类型及其包装类,再加上 Void、String、Date、BigDecimal 和 BigInteger。
(2)数组类型
包括基本类型数组(PRIMITIVE_ARRAY)和对象数组(OBJECT_ARRAY)
(3)复合数据类型

3.类型提示(Type Hints)


5.3 转换算子(Transformation)
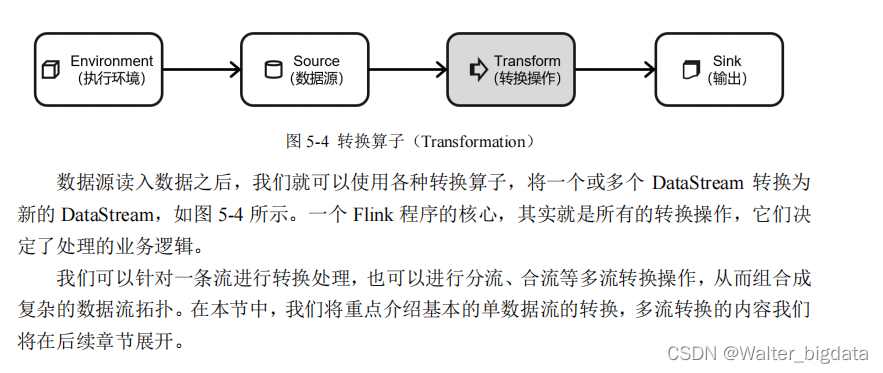
5.3.1 基本转换算子
1. 映射(map)
package com.scy.chapter01;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransformMapTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//从元素读取数据(仅用于测试将数据读取内存作为数据源)
DataStreamSource<Event> stream = env.fromElements(
new Event("mary", "./home", 1000L),
new Event("bob", "./cart", 2000L)
);
//进行转化计算,提取user字段
//1.使用自定义类,实现MapFunction接口
SingleOutputStreamOperator<String> result1 = stream.map(new MyMapper());
//2.使用匿名类,实现MapFunction接口
SingleOutputStreamOperator<String> result2 = stream.map(new MapFunction<Event, String>() {
@Override
public String map(Event value) throws Exception {
return value.user;
}
});
//3.传入Lambda表达式
SingleOutputStreamOperator<String> result3 = stream.map(data -> data.user);
result1.print();
result2.print();
result3.print();
env.execute();
}
//自定义MapFunction
public static class MyMapper implements MapFunction<Event,String>{
@Override
public String map(Event value) throws Exception {
return value.user;
}
}
}
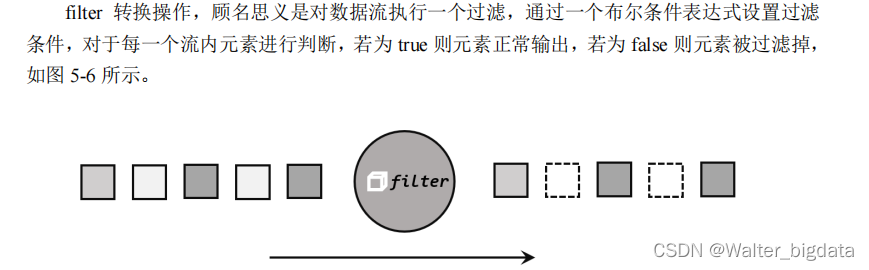
2. 过滤(filter)
package com.scy.chapter01;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransformFilterTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("mary", "./home", 1000L),
new Event("bob", "./cart", 2000L),
new Event("alice", "./prod", 3000L)
);
//1.传入一个实现FilterFunction类的对象
SingleOutputStreamOperator<Event> result1 = stream.filter(new MyFilter());
//2.传入一个匿名类实现FilterFunction接口
SingleOutputStreamOperator<Event> result2 = stream.filter(new FilterFunction<Event>() {
@Override
public boolean filter(Event event) throws Exception {
return event.user.equals("alice");
}
});
//3.传入lambda表示式
stream.filter(data -> data.user.equals("bob")).print("lambda:Alice click");
result1.print();
result2.print();
env.execute();
}
private static class MyFilter implements FilterFunction<Event> {
@Override
public boolean filter(Event event) throws Exception {
return event.user.equals("bob");
}
}
}

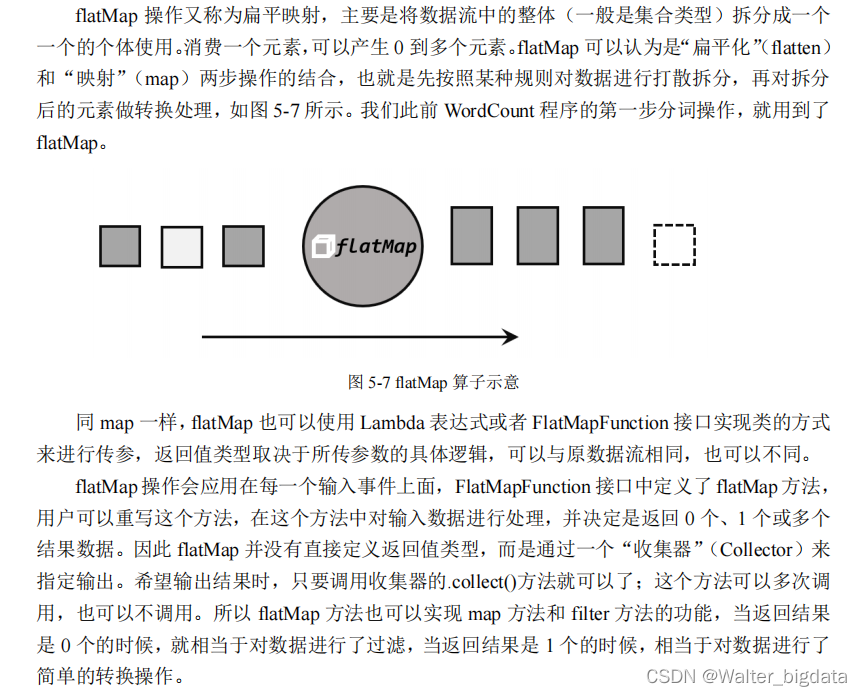
3. 扁平映射(flatMap)
package com.scy.chapter01;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class TransformFlatMapTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("mary", "./home", 1000L),
new Event("bob", "./cart", 2000L),
new Event("scy", "./first", 5000L),
new Event("alice", "./prod", 3000L)
);
//1.实现自定义FlatMapFunction
stream.flatMap(new MyFlatMap()).print("1");
//2.传入匿名表达式
//3.传入lambda表达式
stream.flatMap((Event event,Collector<String> collector) -> {
if (event.user.equals("mary")){ //map操作
collector.collect(event.url);
}
else if (event.user.equals("bob")){ //flat操作
collector.collect(event.user);
collector.collect(event.url);
collector.collect(event.timestamp.toString());
} //filter操作
}).returns(new TypeHint<String>() {}).print("2");
env.execute();
}
private static class MyFlatMap implements FlatMapFunction<Event,String> {
@Override
public void flatMap(Event event, Collector<String> collector) throws Exception {
collector.collect(event.user);
collector.collect(event.url);
collector.collect(event.timestamp.toString());
}
}
}
5.3.2 聚合算子(Aggregation)
直观上看,基本转换算子确实是在“转换”
——因为它们都是基于当前数据,去做了处理和输出。而在实际应用中,我们往往需要对大量的数据进行统计或整合,从而提炼出更有用的信息。
比如之前 word count 程序中,要对每个词出现的频次进行叠加统计。这种操作,计算的结果不仅依赖当前数据,还跟之前的数据有关,相当于要把所有数据聚在一起进行汇总合并
——这就是所谓的“聚合”(Aggregation),也对应着 MapReduce 中的 reduce 操作。
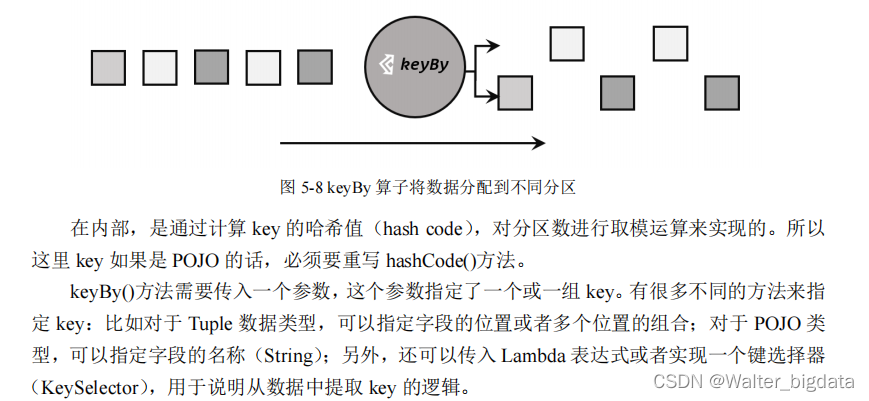
1.按键分区(keyBy)
对于 Flink 而言,DataStream 是没有直接进行聚合的 API 的。因为我们对海量数据做聚合
肯定要进行分区并行处理,这样才能提高效率。所以在 Flink 中,要做聚合,需要先进行分区;
这个操作就是通过 keyBy 来完成的。
keyBy 是聚合前必须要用到的一个算子。keyBy 通过指定键(key),可以将一条流从逻辑
上划分成不同的分区(partitions)。这里所说的分区,其实就是并行处理的子任务,也就对应
着任务槽(task slot)。
基于不同的 key,流中的数据将被分配到不同的分区中去,如图 5-8 所示;这样一来,所
有具有相同的 key 的数据,都将被发往同一个分区,那么下一步算子操作就将会在同一个 slot
中进行处理了。
2.简单聚合
package com.scy.chapter01;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransformSimpleAggTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("mary", "./home", 1000L),
new Event("bob", "./cart", 2000L),
new Event("scy", "./first", 5000L),
new Event("bob", "./prod?id=1", 2500L),
new Event("bob", "./prod?id=2", 3000L),
new Event("bob", "./prod?id=3", 3500L),
new Event("bob", "./home", 4000L),
new Event("scy", "./home", 6000L),
new Event("scy", "./cart", 8000L),
new Event("alice", "./prod", 3000L)
);
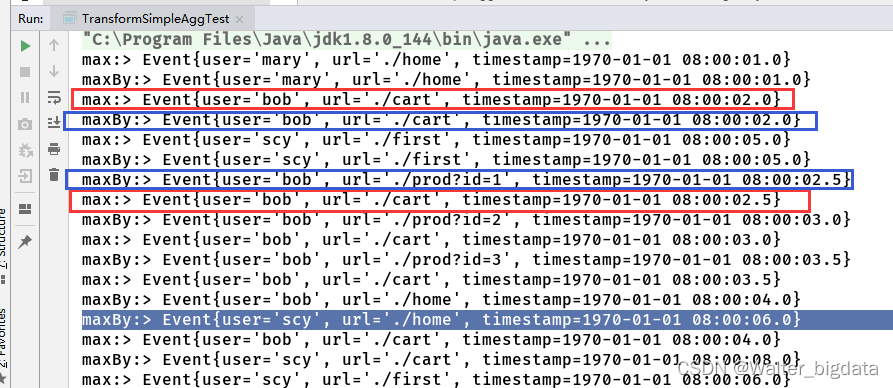
//按键分组后进行聚合,提取当前用户最近一次访问
//1.匿名函数方式
stream.keyBy(new KeySelector<Event, String>() {
@Override
public String getKey(Event event) throws Exception {
return event.user;
}
}).max("timestamp").print("max:"); //max只更新timestamp,url数据不变
//2.lambda表达式
stream.keyBy(data -> data.user)
.maxBy("timestamp") //max更新最新的那一整条数据
.print("maxBy:");
env.execute();
}
}
3.归约聚合(reduce)
package com.scy.chapter01;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransformReduceTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("alice", "./home", 1000L),
new Event("mary", "./home", 1000L),
new Event("bob", "./cart", 2000L),
new Event("scy", "./first", 5000L),
new Event("bob", "./prod?id=1", 2500L),
new Event("bob", "./prod?id=2", 3000L),
new Event("mary", "./cart", 2000L),
new Event("bob", "./prod?id=3", 3500L),
new Event("bob", "./home", 4000L),
new Event("scy", "./home", 6000L),
new Event("alice", "./prod", 3000L)
);
//1.统计每个用户的访问频次
SingleOutputStreamOperator<Tuple2<String, Long>> clicksByUser = stream.map(new MapFunction<Event, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(Event event) throws Exception {
return Tuple2.of(event.user, 1L);
}
}).keyBy(data -> data.f0)
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
});
//2.选取当前最活跃的用户
SingleOutputStreamOperator<Tuple2<String, Long>> result = clicksByUser.keyBy(data -> "key")
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {
return value1.f1 > value2.f1 ? value1 : value2;
}
});
result.print();
env.execute();
}
}

5.3.3 用户自定义函数(UDF)

1. 函数类(Function Classes)
对于大部分操作而言,都需要传入一个用户自定义函数(UDF),实现相关操作的接口,
来完成处理逻辑的定义。Flink 暴露了所有 UDF 函数的接口,具体实现方式为接口或者抽象类,
例如 MapFunction、FilterFunction、ReduceFunction 等。
所以最简单直接的方式,就是自定义一个函数类,实现对应的接口。之前我们对于 API
的练习,主要就是基于这种方式。
下面例子实现了 FilterFunction 接口,用来筛选 url 中包含“home”的事件:
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransFunctionUDFTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> clicks = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L)
);
DataStream<Event> stream = clicks.filter(new FlinkFilter());
stream.print();
env.execute();
}
public static class FlinkFilter implements FilterFunction<Event> {
@Override
public boolean filter(Event value) throws Exception {
return value.url.contains("home");
}
} }
当然还可以通过匿名类来实现 FilterFunction 接口:
DataStream<String> stream = clicks.filter(new FilterFunction<Event>() {
@Override
public boolean filter(Event value) throws Exception {
return value.url.contains("home");
}
});
为了类可以更加通用,我们还可以将用于过滤的关键字"home"抽象出来作为类的属性,
调用构造方法时传进去。
DataStream<Event> stream = clicks.filter(new KeyWordFilter("home"));
public static class KeyWordFilter implements FilterFunction<Event> {
private String keyWord;
KeyWordFilter(String keyWord) { this.keyWord = keyWord; }
@Override
public boolean filter(Event value) throws Exception {
return value.url.contains(this.keyWord);
} }
2. 匿名函数(Lambda)
匿名函数(Lambda 表达式)是 Java 8 引入的新特性,方便我们更加快速清晰地写代码。
Lambda 表达式允许以简洁的方式实现函数,以及将函数作为参数来进行传递,而不必声明额外的(匿名)类。
Flink 的所有算子都可以使用 Lambda 表达式的方式来进行编码,但是,当 Lambda 表
达式使用 Java 的泛型时,我们需要显式的声明类型信息。
下例演示了如何使用 Lambda 表达式来实现一个简单的 map() 函数,我们使用 Lambda
表达式来计算输入的平方。在这里,我们不需要声明 map() 函数的输入 i 和输出参数的数据
类型,因为 Java 编译器会对它们做出类型推断。
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransFunctionLambdaTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> clicks = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L)
);
//map 函数使用 Lambda 表达式,返回简单类型,不需要进行类型声明
DataStream<String> stream1 = clicks.map(event -> event.url);
stream1.print();
env.execute();
} }
由于 OUT 是 String 类型而不是泛型,所以 Flink 可以从函数签名 OUT map(IN value) 的实现中自动提取出结果的类型信息。
但是对于像 flatMap() 这样的函数,它的函数签名 void flatMap(IN value, Collector out) 被 Java 编译器编译成了 void flatMap(IN value, Collector out),也就是说将 Collector 的泛
型信息擦除掉了。这样 Flink 就无法自动推断输出的类型信息了。
在这种情况下,我们需要显式地指定类型信息,否则输出将被视为 Object 类型,这会导
致低效的序列化。
// flatMap 使用 Lambda 表达式,必须通过 returns 明确声明返回类型
DataStream<String> stream2 = clicks.flatMap((Event event, Collector<String> out) -> {
out.collect(event.url);
}).returns(Types.STRING); //或者returns(new TypeHint<String>() {});
stream2.print();
3. 富函数类(Rich Function Classes)


package com.scy.chapter01;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransformRichFunctionTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("alice", "./home", 1000L),
new Event("mary", "./home", 1000L),
new Event("bob", "./cart", 2000L),
new Event("scy", "./first", 5000L),
new Event("bob", "./prod?id=1", 2500L),
new Event("bob", "./prod?id=2", 3000L),
new Event("mary", "./cart", 2000L),
new Event("bob", "./prod?id=3", 3500L),
new Event("scy", "./home", 6000L),
new Event("alice", "./prod", 3000L)
);
stream.map(new MyRichMapper()).setParallelism(2)
.print();
env.execute();
}
//实现一个自定义富含数据类
private static class MyRichMapper extends RichMapFunction<Event,Integer> {
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
System.out.println("open生命周期被调用"+getRuntimeContext().getIndexOfThisSubtask()+"号任务启动");
}
@Override
public Integer map(Event event) throws Exception {
return event.url.length();
}
@Override
public void close() throws Exception {
super.close();
System.out.println("close生命周期被调用"+getRuntimeContext().getIndexOfThisSubtask()+"号任务启动");
}
}
}

5.3.4 物理分区(Physical Partitioning)

1.随机分区(shuffle)
最简单的重分区方式就是直接“洗牌”。通过调用 DataStream 的.shuffle()方法,将数据随
机地分配到下游算子的并行任务中去。
package com.scy.chapter01;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TransformPartitionTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("alice", "./home", 1000L),
new Event("mary", "./home", 1000L),
new Event("bob", "./cart", 2000L),
new Event("scy", "./first", 5000L),
new Event("bob", "./prod?id=1", 2500L),
new Event("bob", "./prod?id=2", 3000L),
new Event("mary", "./cart", 2000L),
new Event("bob", "./prod?id=3", 3500L),
new Event("scy", "./home", 6000L),
new Event("bob", "./prod?id=2", 5000L),
new Event("alice", "./prod", 3000L)
);
//1.随机分区
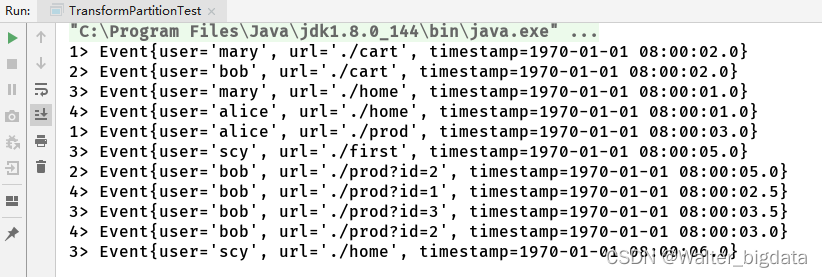
stream.shuffle().print().setParallelism(4);
env.execute();
}
}
2.轮询分区(Round-Robin)
//2.轮询分区
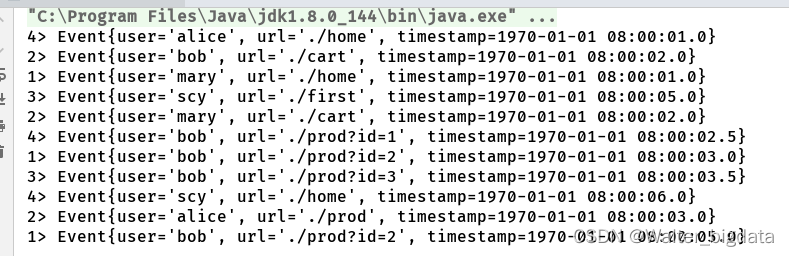
stream.rebalance().print().setParallelism(4);
stream.print().setParallelism(4); //默认分区方式就是轮询分区
3.重缩放分区(rescale)
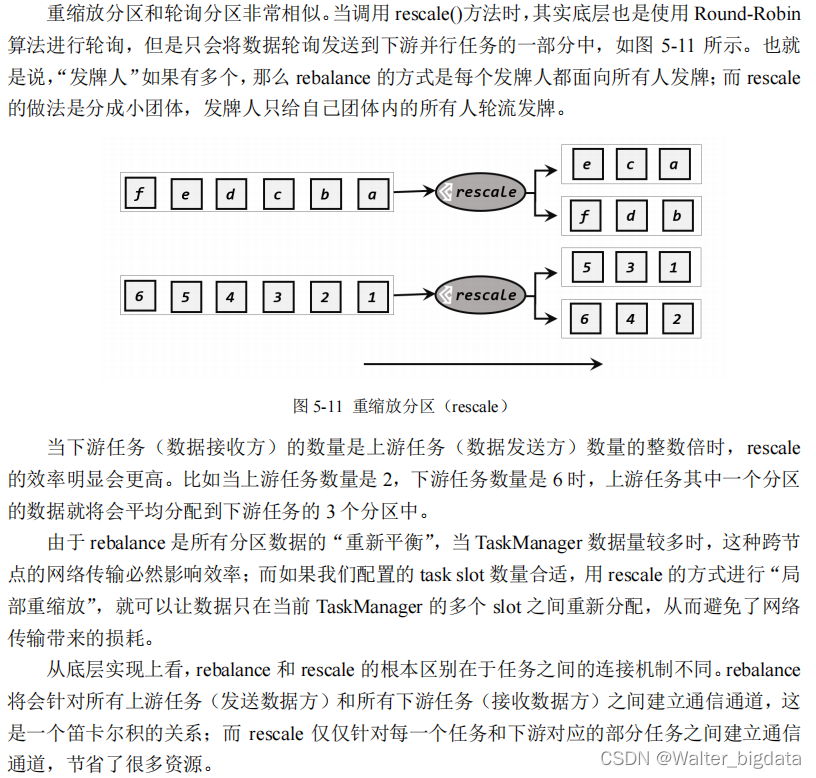
package com.scy.chapter01;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
public class TransformPartitionTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 3. rescale重缩放分区
env.addSource(new RichParallelSourceFunction<Integer>() {
public void run(SourceContext<Integer> sourceContext) throws Exception {
for (int i = 1; i <= 8; i++) {
// 将奇数发送到索引为1的并行子任务
// 将偶数发送到索引为0的并行子任务
if ( i % 2 == getRuntimeContext().getIndexOfThisSubtask()) {
sourceContext.collect(i);
}
}
}
public void cancel() {
}
}).setParallelism(2)
.rescale()
.print()
.setParallelism(4);
env.execute();
}
}
4.广播(broadcast)
这种方式其实不应该叫做“重分区”,因为经过广播之后,数据会在不同的分区都保留一
份,可能进行重复处理。可以通过调用 DataStream 的 broadcast()方法,将输入数据复制并发送到下游算子的所有并行任务中去。
//4.广播
stream.broadcast().print().setParallelism(4);
5.全局分区(global)
全局分区也是一种特殊的分区方式。这种做法非常极端,通过调用.global()方法,会将所有的输入流数据都发送到下游算子的第一个并行子任务中去。这就相当于强行让下游任务并行
度变成了 1,所以使用这个操作需要非常谨慎,可能对程序造成很大的压力。
//5.全局分区
stream.global().print().setParallelism(4);
6.自定义分区(Custom)
当Flink提供的所有分区策略都不能满足用户的需求时, 我们可以通过使用partitionCustom()方法来自定义分区策略。
在调用时,方法需要传入两个参数,第一个是自定义分区器(Partitioner)对象,第二个
是应用分区器的字段,它的指定方式与 keyBy 指定 key 基本一样:可以通过字段名称指定,
也可以通过字段位置索引来指定,还可以实现一个 KeySelector。
//6.自定义分区
env.fromElements(1,2,3,4,5,6,7,8)
.partitionCustom(new Partitioner<Integer>() {
@Override
public int partition(Integer integer, int i) {
return integer % 2;
}
}, new KeySelector<Integer, Integer>() {
@Override
public Integer getKey(Integer integer) throws Exception {
return integer;
}
}).print().setParallelism(4);

5.4 输出算子(Sink)
5.4.1 连接到外部系统



5.4.2 输出到文件

package com.scy.chapter01;
import org.apache.flink.api.common.serialization.BulkWriter;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.core.fs.FSDataOutputStream;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.io.IOException;
import java.util.concurrent.TimeUnit;
public class SinkToFileTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
DataStreamSource<Event> stream = env.fromElements(
new Event("alice", "./home", 1000L),
new Event("mary", "./home", 1000L),
new Event("bob", "./cart", 2000L),
new Event("scy", "./first", 5000L),
new Event("bob", "./prod?id=1", 2500L),
new Event("bob", "./prod?id=2", 3000L),
new Event("mary", "./cart", 2000L),
new Event("bob", "./prod?id=3", 3500L),
new Event("bob", "./prod?id=2", 5000L),
new Event("alice", "./prod", 3000L)
);
StreamingFileSink<String> streamingFileSink = StreamingFileSink.<String>forRowFormat(new Path("./output"),
new SimpleStringEncoder<>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withMaxPartSize(1024*1024*1024) //文件大小达到1G时换文件写入
.withRolloverInterval(TimeUnit.MINUTES.toMillis(15)) //多长时间滚动一次,写入新文件
.withInactivityInterval(TimeUnit.MINUTES.toMillis(5)) //当前任务不活跃时间
.build()
)
.build();
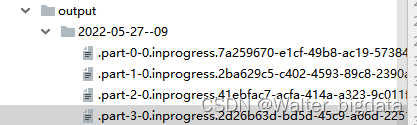
stream.map(data -> data.toString())
.addSink(streamingFileSink);
env.execute();
}
}
5.4.3 输出到 Kafka (重点)
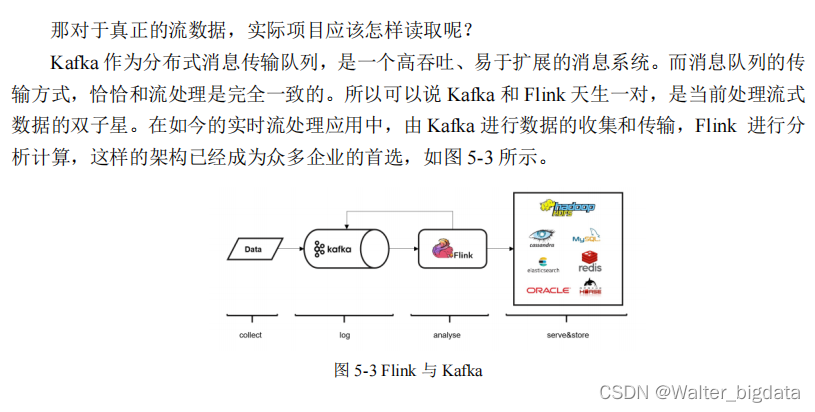
Kafka 是一个分布式的基于发布/订阅的消息系统,本身处理的也是流式数据,所以跟Flink“天生一对”,经常会作为 Flink 的输入数据源和输出系统。Flink 官方为 Kafka 提供了 Source
和 Sink 的连接器,我们可以用它方便地从 Kafka 读写数据。如果仅仅是支持读写,那还说明
不了 Kafka 和 Flink 关系的亲密;真正让它们密不可分的是,Flink 与 Kafka 的连接器提供了端
到端的精确一次(exactly once)语义保证,这在实际项目中是最高级别的一致性保证。关于
这部分内容,我们会在后续章节做更详细的讲解。
现在我们要将数据输出到 Kafka,整个数据处理的闭环已经形成,所以可以完整测试如下:
(1)添加 Kafka 连接器依赖
由于我们已经测试过从 Kafka 数据源读取数据,连接器相关依赖已经引入,这里就不重复
介绍了。
(2)启动 Kafka 集群
(3)编写输出到 Kafka 的示例代码
我们可以直接将用户行为数据保存为文件 clicks.csv,读取后不做转换直接写入 Kafka,主
题(topic)命名为“clicks”
生产者
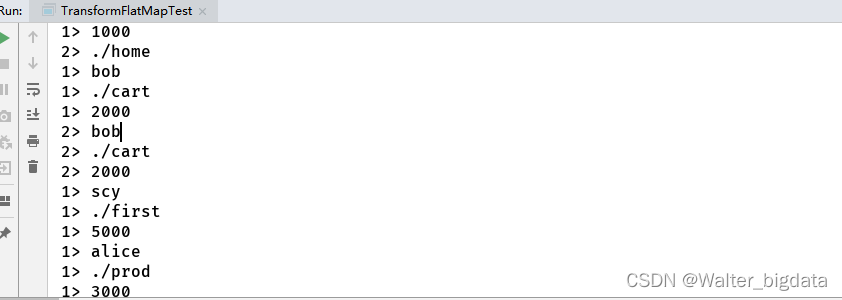
在flink中实现从Kafka读取数据并ETL结果写入Kafka
package com.scy.chapter01;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import java.util.Properties;
public class SinkToKafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.从kafka中读取数据
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","node1:9092");
DataStreamSource<String> kafkaStream = env.addSource(new FlinkKafkaConsumer<String>("clicks", new SimpleStringSchema(), properties));
//2.用flink进行转换处理
SingleOutputStreamOperator<String> result = kafkaStream.map(new MapFunction<String, String>() {
@Override
public String map(String s) throws Exception {
String[] fields = s.split(",");
return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim())).toString();
}
});
//3.结果数据写入Kafka
result.addSink(new FlinkKafkaProducer<String>("node1:9092","events",new SimpleStringSchema()));
env.execute();
}
}
消费者

结果
5.4.4 输出到 Redis

(1)导入的 Redis 连接器依赖
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
</dependency>
package com.scy.chapter01;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.redis.RedisSink;
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper;
public class SinkToRedis {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.addSource(new ClickSource());
//创建jedis连接配置
FlinkJedisPoolConfig config = new FlinkJedisPoolConfig.Builder()
.setHost("node8")
.build();
//写入redis
stream.addSink(new RedisSink<Event>(config, new MyRedisMapper()));
env.execute();
}
private static class MyRedisMapper implements RedisMapper<Event> {
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.HSET,"clicks");
}
public String getKeyFromData(Event event) {
return event.user;
}
public String getValueFromData(Event event) {
return event.url;
}
}
}
这里 RedisSink 的构造方法需要传入两个参数:
⚫ JFlinkJedisConfigBase:Jedis 的连接配置
⚫ RedisMapper:Redis 映射类接口,说明怎样将数据转换成可以写入 Redis 的类型
接下来主要就是定义一个 Redis 的映射类,实现 RedisMapper 接口。
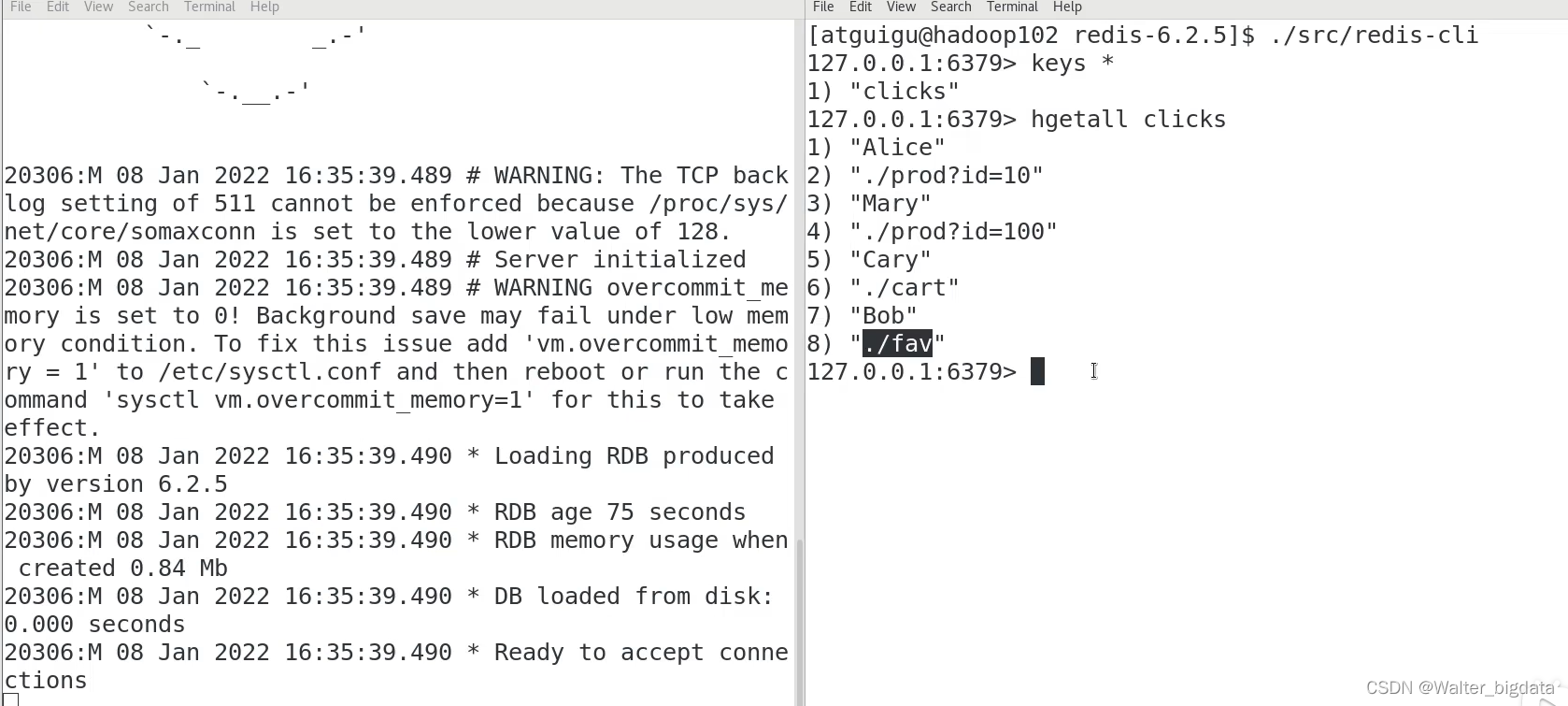
5.4.5 输出到 Elasticsearch

(1)添加 Elasticsearch 连接器依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch7_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
(2)启动 Elasticsearch 集群
(3)编写输出到 Elasticsearch 的示例代码
package com.scy.chapter01;
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction;
import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
import org.apache.flink.streaming.connectors.elasticsearch6.ElasticsearchSink;
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.Requests;
import java.util.ArrayList;
import java.util.HashMap;
public class SinkToEsTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=200", 3500L),
new Event("Bob", "./prod?id=2", 2500L),
new Event("Alice", "./prod?id=300", 3600L),
new Event("Bob", "./home", 3000L),
new Event("Bob", "./prod?id=1", 2300L),
new Event("Bob", "./prod?id=3", 3300L));
ArrayList<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("hadoop102", 9200, "http"));
// 创建一个ElasticsearchSinkFunction
ElasticsearchSinkFunction<Event> elasticsearchSinkFunction = new ElasticsearchSinkFunction<Event>() {
@Override
public void process(Event element, RuntimeContext ctx, RequestIndexer indexer) {
HashMap<String, String> data = new HashMap<>();
data.put(element.user, element.url);
IndexRequest request = Requests.indexRequest()
.index("clicks")
.type("type") // Es 6 必须定义 type
.source(data);
indexer.add(request);
}
};
//写入Es
stream.addSink(new ElasticsearchSink.Builder<Event>(httpHosts, elasticsearchSinkFunction).build());
env.execute();
}
}
5.4.6 输出到 MySQL(JDBC)

(1)添加依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
(2)启动 MySQL,在 database 库下建表 clicks
mysql> create table clicks(
-> user varchar(20) not null,
-> url varchar(100) not null);
(3)编写输出到 MySQL 的示例代码
package com.scy.chapter01;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SinkToMySQLTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=200", 3500L),
new Event("Bob", "./prod?id=2", 2500L),
new Event("Alice", "./prod?id=300", 3600L),
new Event("Bob", "./home", 3000L),
new Event("Bob", "./prod?id=1", 2300L),
new Event("Bob", "./prod?id=3", 3300L));
stream.addSink(
JdbcSink.sink(
"INSERT INTO clicks (user, url) VALUES (?, ?)",
(statement, r) -> {
statement.setString(1, r.user);
statement.setString(2, r.url);
},
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3306/test")
.withDriverName("com.mysql.jdbc.Driver")
.withUsername("root")
.withPassword("root")
.build()
)
);
env.execute();
}
}
5.4.7 自定义 Sink 输出 (不能保证状态一致性)
如果我们想将数据存储到我们自己的存储设备中,而 Flink 并没有提供可以直接使用的连接器,又该怎么办呢?
与 Source 类似,Flink 为我们提供了通用的 SinkFunction 接口和对应的 RichSinkDunction
抽象类,只要实现它,通过简单地调用 DataStream 的.addSink()方法就可以自定义写入任何外
部存储。之前与外部系统的连接,其实都是连接器帮我们实现了 SinkFunction,现在既然没有
现成的,我们就只好自力更生了。例如,Flink 并没有提供 HBase 的连接器,所以需要我们自
己写。
在实现 SinkFunction 的时候,需要重写的一个关键方法 invoke(),在这个方法中我们就可
以实现将流里的数据发送出去的逻辑。
我们这里使用了 SinkFunction 的富函数版本,因为这里我们又使用到了生命周期的概念,
创建 HBase 的连接以及关闭 HBase 的连接需要分别放在 open()方法和 close()方法中。
(1)导入依赖
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
(2)编写输出到 HBase 的示例代码
package com.scy.chapter01;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import java.nio.charset.StandardCharsets;
public class SinkCustomtoHBase {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env
.fromElements("hello", "world")
.addSink(
new RichSinkFunction<String>() {
public org.apache.hadoop.conf.Configuration
configuration; // 管理 Hbase 的配置信息,这里因为 Configuration 的重名问题,将类以完整路径导入
public Connection connection; // 管理 Hbase 连接@Override
public void open(Configuration parameters) throws
Exception {
super.open(parameters);
configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum",
"hadoop102:2181");
connection =
ConnectionFactory.createConnection(configuration);
}
@Override
public void invoke(String value, Context context) throws
Exception {
Table table =
connection.getTable(TableName.valueOf("test")); // 表名为 test
Put put = new
Put("rowkey".getBytes(StandardCharsets.UTF_8)); // 指定 rowkey
put.addColumn("info".getBytes(StandardCharsets.UTF_8) // 指定列名
, value.getBytes(StandardCharsets.UTF_8) // 写入的数据
, "1".getBytes(StandardCharsets.UTF_8)); // 写入的数据
table.put(put); // 执行 put 操作
table.close(); // 将表关闭
}
@Override
public void close() throws Exception {
super.close();
connection.close(); // 关闭连接
}
}
);
env.execute();
} }
5.5 本章总结

第六章 Flink中的时间和窗口

6.1 时间语义
“时间”,从理论物理和哲学的角度解释,可能有些玄妙;但对于我们来说,它其实是生活
中再熟悉不过的一个概念。一年 365 天,每天 24 小时,时间就像缓缓流淌的河,不疾不徐、
无休无止地前进着,它是我们衡量事件发生和进展的标准尺度。如果想写抒情散文或是科幻小
说,时间无疑是个绝好的题材。但这跟数据处理有什么关系呢?
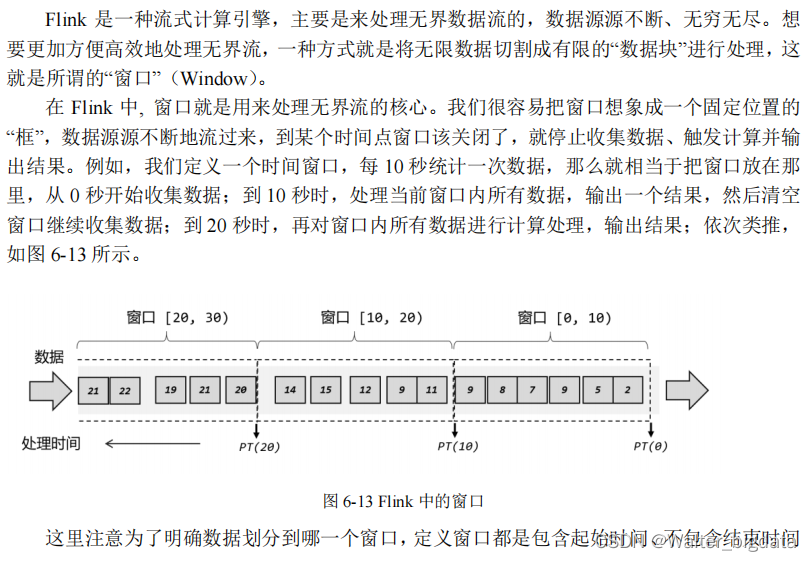
其实从上面的描述中已经可以发现,时间本身就有着“流”的特性,它可以用来判断事件
发生的先后以及间隔;所以如果我们想要划定窗口来收集数据,一般就需要基于时间。对于批
处理来说,这似乎没什么讨论的必要,因为数据都收集好了,想怎么划分窗口都可以;而对于
流处理来说,如果想处理更加实时,就必须对时间有更加精细的控制。
那怎样对时间进行“精细的控制”呢?在我们的认知里,时间的流逝是一个客观的事实,只要有一个足够精确的表就可以告诉我们准确的时间了。在计算机系统里,这不就是系统时间
吗?那所谓的“时间语义”又是什么意思呢?
6.1.1 Flink 中的时间语义
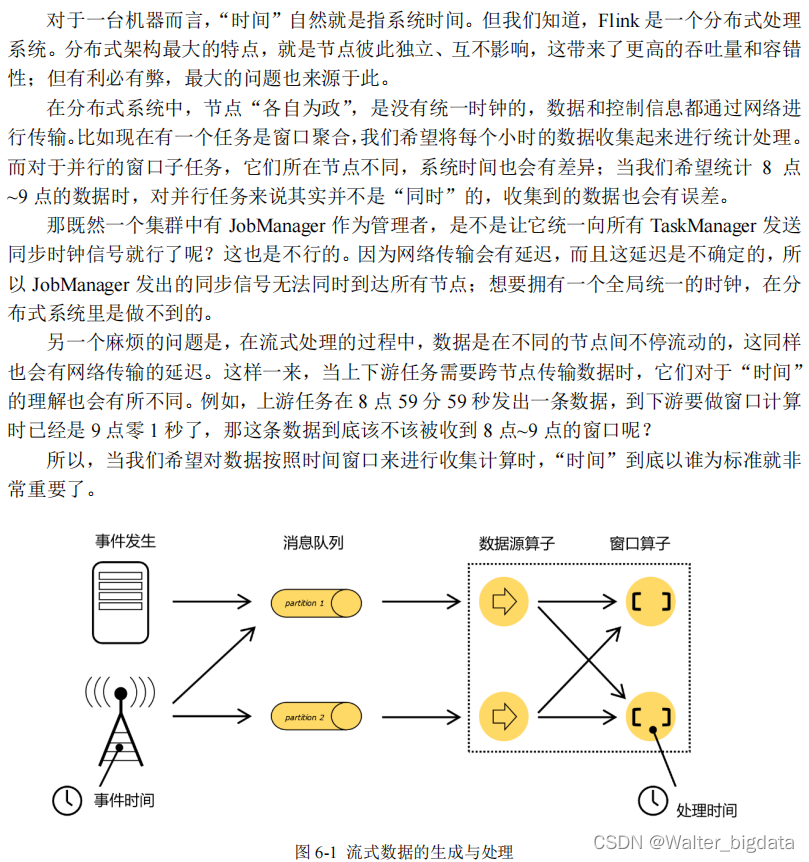
我们重新梳理一下流式数据处理的过程。如图 6-1 所示,在事件发生之后,生成的数据被
收集起来,首先进入分布式消息队列,然后被 Flink 系统中的 Source 算子读取消费,进而向下
游的转换算子(窗口算子)传递,最终由窗口算子进行计算处理。
很明显,这里有两个非常重要的时间点:一个是数据产生的时间,我们把它叫作“事件时间”(Event Time);另一个是数据真正被处理的时刻,叫作“处理时间”(Processing Time)。
我们所定义的窗口操作,到底是以那种时间作为衡量标准,就是所谓的“时间语义”(Notions
of Time)。由于分布式系统中网络传输的延迟和时钟漂移,处理时间相对事件发生的时间会有
所滞后。
1.处理时间(Processing Time)

2.事件时间(Event Time)

6.1.2 哪种时间语义更重要
我们已经了解了 Flink 中两种不同的时间语义,那实际应用的时候,到底应该用哪个呢?
1.从《星球大战》说起
为了更加清晰地说明两种语义的区别,我们来举一个非常经典的例子:电影《星球大战》。

2.数据处理系统中的时间语义

3.两种时间语义的对比

6.2 水位线(Watermark)
在介绍事件时间语义时,我们提到了“水位线”的概念,已经知道了它其实就是用来度量
事件时间的。那么水位线具体有什么含义,又跟数据的时间戳有什么关系呢?接下来我们就来
深入探讨一下这个流处理中的核心概念。
6.2.1 事件时间和窗口
在实际应用中,一般会采用事件时间语义。而水位线,就是基于事件时间提出的概念。所
以在介绍水位线之前,我们首先来梳理一下事件时间和窗口的关系。
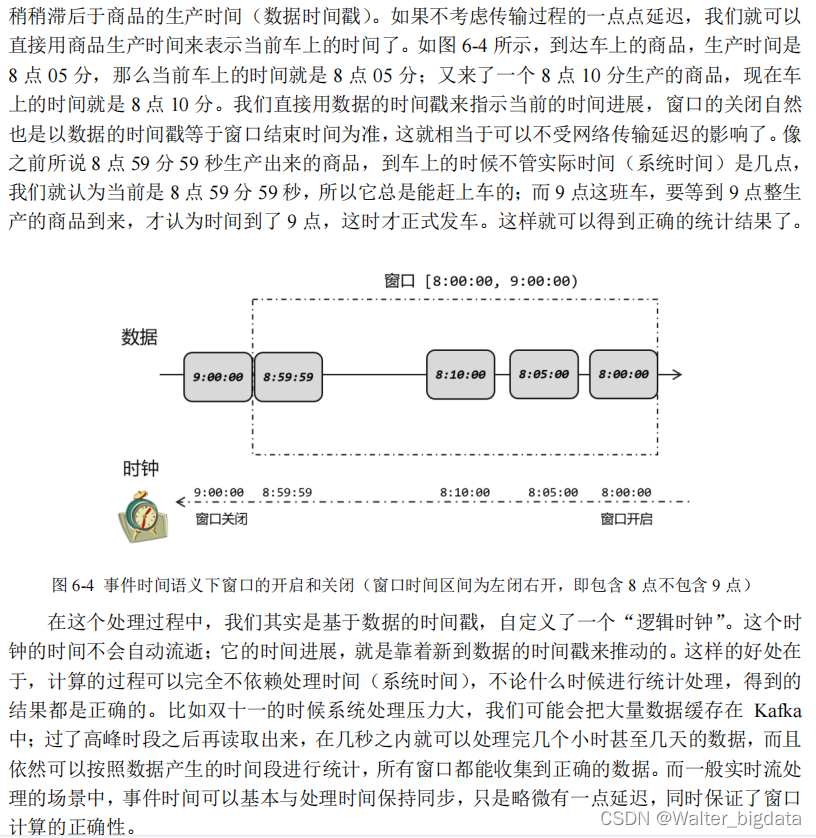
一个数据产生的时刻,就是流处理中事件触发的时间点,这就是“事件时间”,一般都会以时间戳的形式作为一个字段记录在数据里。这个时间就像商品的“生产日期”一样,一旦产
生就是固定的,印在包装袋上,不会因为运输辗转而变化。如果我们想要统计一段时间内的数
据,需要划分时间窗口,这时只要判断一下时间戳就可以知道数据属于哪个窗口了。
明确了一个数据的所属窗口,还不能直接进行计算。因为窗口处理的是有界数据,我们需
要等窗口的数据都到齐了,才能计算出最终的统计结果。那什么时候数据就都到齐了呢?对于
时间窗口来说这很明显:到了窗口的结束时间,自然就应该收集到了所有数据,就可以触发计
算输出结果了。比如我们想统计 8 点~9 点的用户点击量,那就是从 8 点开始收集数据,到 9
点截止,将收集的数据做处理计算。这有点类似于班车,如图 6-3 所示,每小时发一班,那么
8 点之后来的人都会上同一班车,到 9 点钟准时发车;9 点之后来的人,就只好等下一班 10
点发的车了。

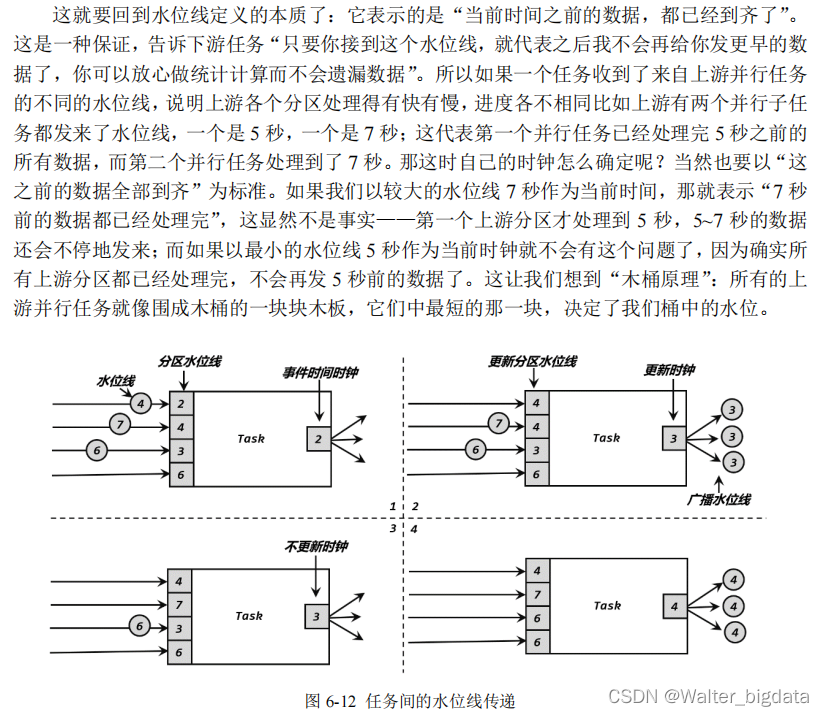
6.2.2 什么是水位线
在事件时间语义下,我们不依赖系统时间,而是基于数据自带的时间戳去定义了一个时钟,用来表示当前时间的进展。于是每个并行子任务都会有一个自己的逻辑时钟,它的前进是靠数
据的时间戳来驱动的。
但在分布式系统中,这种驱动方式又会有一些问题。因为数据本身在处理转换的过程中会
变化,如果遇到窗口聚合这样的操作,其实是要攒一批数据才会输出一个结果,那么下游的数
据就会变少,时间进度的控制就不够精细了。另外,数据向下游任务传递时,一般只能传输给
一个子任务(除广播外),这样其他的并行子任务的时钟就无法推进了。例如一个时间戳为 9

1.有序流中的水位线

2.乱序流中的水位线





3.水位线的特性
现在我们可以知道,水位线就代表了当前的事件时间时钟,而且可以在数据的时间戳基础
上加一些延迟来保证不丢数据,这一点对于乱序流的正确处理非常重要。
我们可以总结一下水位线的特性:
1.水位线是插入到数据流中的一个标记,可以认为是一个特殊的数据
2.水位线主要的内容是一个时间戳,用来表示当前事件时间的进展
3.水位线是基于数据的时间戳生成的
4.水位线的时间戳必须单调递增,以确保任务的事件时间时钟一直向前推进
5.水位线可以通过设置延迟,来保证正确处理乱序数据
6.一个水位线 Watermark(t),表示在当前流中事件时间已经达到了时间戳 t, 这代表 t 之
7.前的所有数据都到齐了,之后流中不会出现时间戳 t’ ≤ t 的数据水位线是Flink流处理中保证结果
正确性的核心机制,它往往会跟窗口一起配合,完成对乱序数据的正确处理。关于这部分内容,
我们会稍后进一步展开讲解。
6.2.3 如何生成水位线
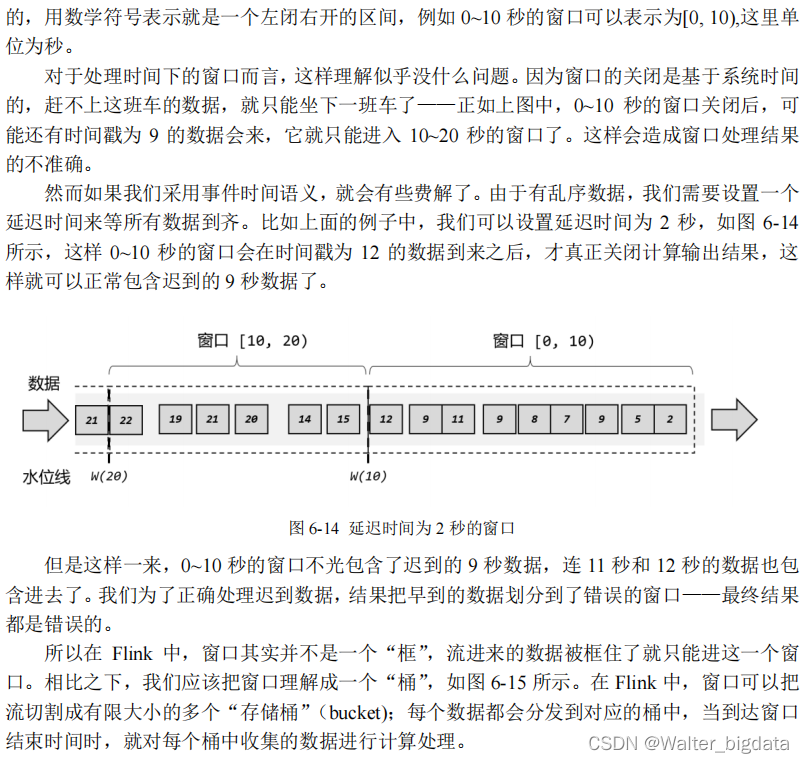
水位线是用来保证窗口处理结果的正确性的,如果不能正确处理所有乱序数据,可以尝试调大延迟的时间。那在实际应用中,到底应该怎样生成水位线呢?
1.生成水位线的总体原则


2.水位线生成策略(Watermark Strategies)


3.Flink 内置水位线生成器(重点)

(1)有序流
对于有序流,主要特点就是时间戳单调增长(Monotonously Increasing Timestamps),所以
永远不会出现迟到数据的问题。这是周期性生成水位线的最简单的场景,直接调用
WatermarkStrategy.forMonotonousTimestamps()方法就可以实现。简单来说,就是直接拿当前最大的时间戳作为水位线就可以了。
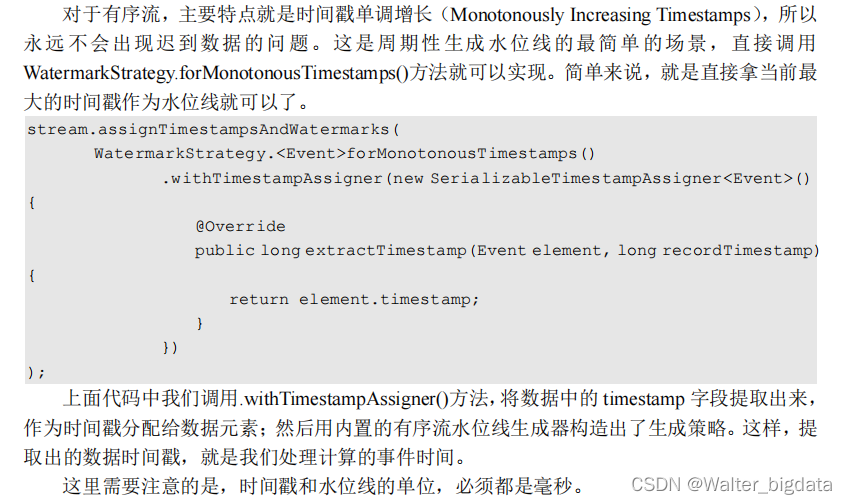
package com.scy.chapter01;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.time.Duration;
public class WatermarkTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100); //生成水位线的时间间隔
DataStream<Event> stream = env.fromElements(
new Event("alice", "./home", 1000L),
new Event("mary", "./home", 1000L),
new Event("bob", "./cart", 2000L),
new Event("scy", "./first", 5000L),
new Event("bob", "./prod?id=1", 2500L),
new Event("bob", "./prod?id=2", 3000L),
new Event("mary", "./cart", 2000L),
new Event("bob", "./prod?id=3", 3500L),
new Event("alice", "./prod", 3000L))
//有序流的watermark生成
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp; //默认毫秒。如果是秒则乘以1000
}
})
)
env.execute();
(2)乱序流 --处理流式数据迟到方式三重保证之一-watermark延迟
由于乱序流中需要等待迟到数据到齐,所以必须设置一个固定量的延迟时间(Fixed
Amount of Lateness)。这时生成水位线的时间戳,就是当前数据流中最大的时间戳减去延迟的
结果,相当于把表调慢,当前时钟会滞后于数据的最大时间戳。调用 WatermarkStrategy.
forBoundedOutOfOrderness()方法就可以实现。这个方法需要传入一个 maxOutOfOrderness 参
数,表示“最大乱序程度”,它表示数据流中乱序数据时间戳的最大差值;如果我们能确定乱序
程度,那么设置对应时间长度的延迟,就可以等到所有的乱序数据了。
package com.scy.chapter01;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.time.Duration;
public class WatermarkTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100); //生成水位线的时间间隔
DataStream<Event> stream = env.fromElements(
new Event("alice", "./home", 1000L),
new Event("mary", "./home", 1000L),
new Event("bob", "./cart", 2000L),
new Event("scy", "./first", 5000L),
new Event("bob", "./prod?id=1", 2500L),
new Event("bob", "./prod?id=2", 3000L),
new Event("mary", "./cart", 2000L),
new Event("bob", "./prod?id=3", 3500L),
new Event("alice", "./prod", 3000L))
//乱序流的watermark生成
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
})
);
env.execute();
}
}
设置水位线实现这两个方法
assignTimestampsAndWatermarks 水位线生成器
withTimestampAssigner 水位线提取器
4.自定义水位线策略





5.在自定义数据源中发送水位线


6.2.4 水位线的传递



6.2.5 水位线的总结

6.3 窗口(Window)

6.3.1 窗口的概念
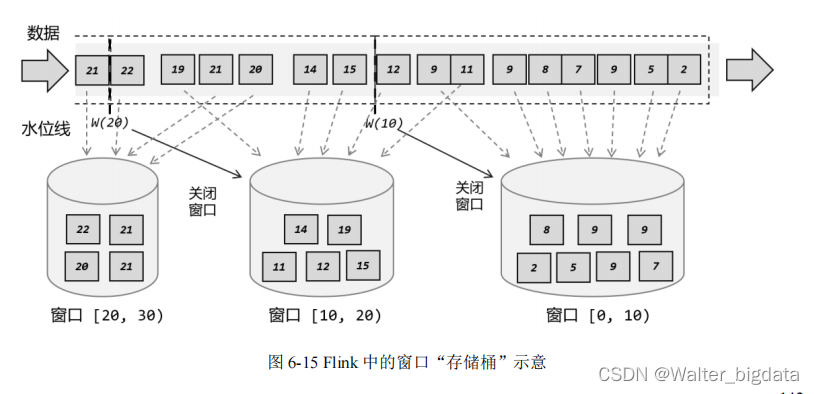

6.3.2 窗口的分类
1. 按照驱动类型分类
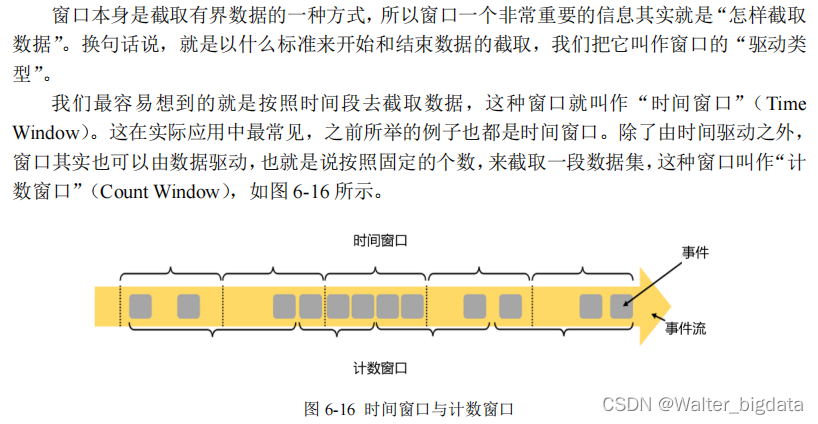
(1)时间窗口(Time Window)

(2)计数窗口(Count Window)

2. 按照窗口分配数据的规则分类
时间窗口和计数窗口,只是对窗口的一个大致划分;在具体应用时,还需要定义更加精细
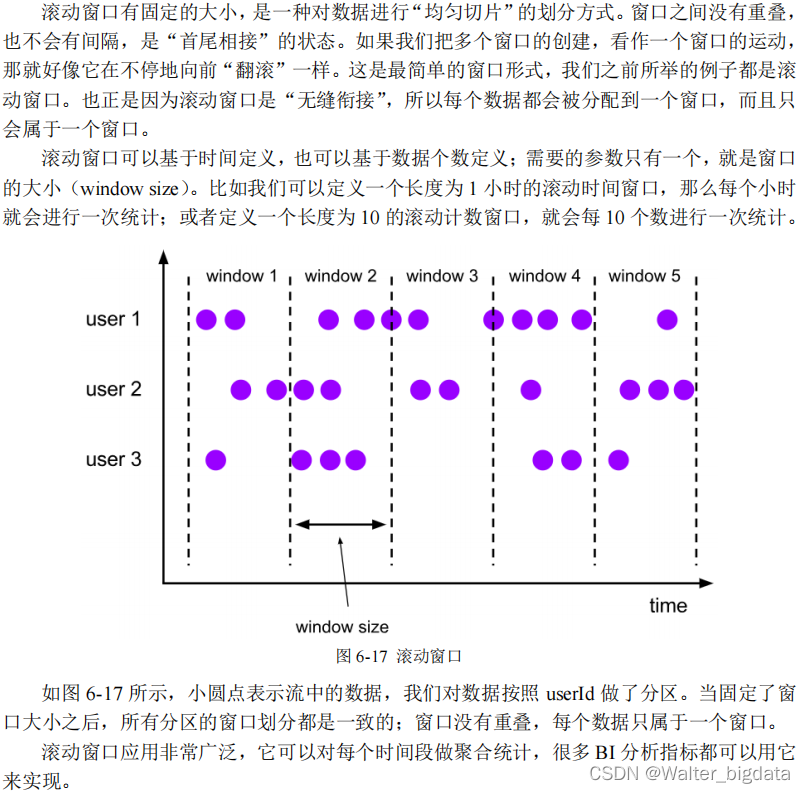
的规则,来控制数据应该划分到哪个窗口中去。不同的分配数据的方式,就可以有不同的功能应用。根据分配数据的规则,窗口的具体实现可以分为 4 类:滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)、会话窗口(Session Window),以及全局窗口(Global Window)。
下面我们来做具体介绍。
(1)滚动窗口(Tumbling Windows)
(2)滑动窗口(Sliding Windows)


在一些场景中,可能需要统计最近一段时间内的指标,而结果的输出频率要求又很高,甚
至要求实时更新,比如股票价格的 24 小时涨跌幅统计,或者基于一段时间内行为检测的异常
报警。这时滑动窗口无疑就是很好的实现方式。
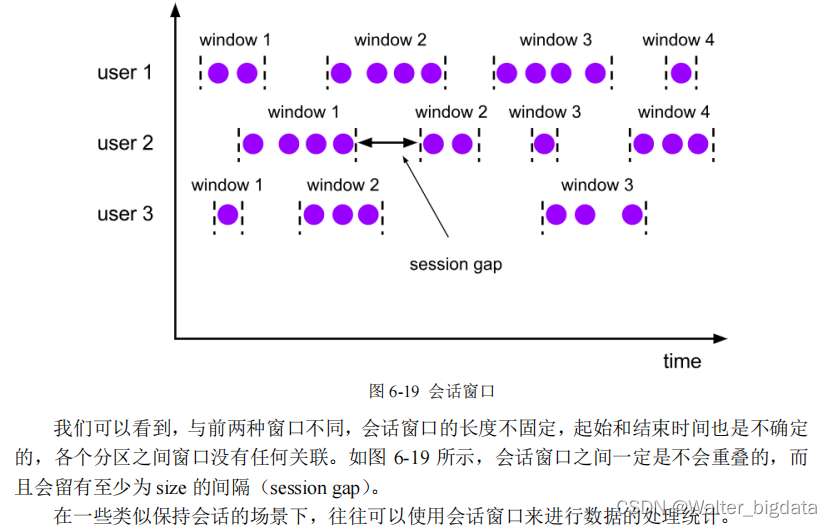
(3)会话窗口(Session Windows)


(4)全局窗口(Global Windows)
还有一类比较通用的窗口,就是“全局窗口”。这种窗口全局有效,会把相同 key 的所有
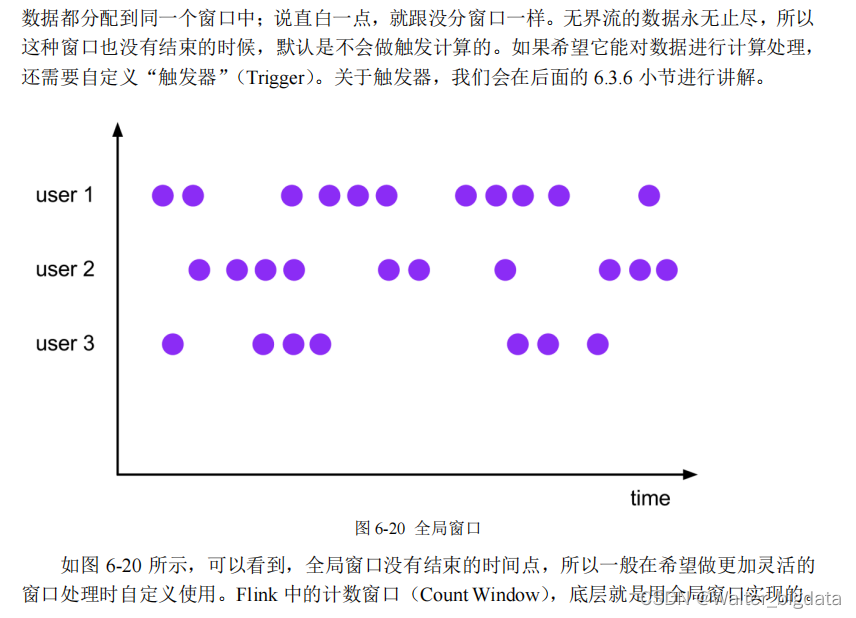
6.3.3 窗口 API 概览
1. 按键分区(Keyed)和非按键分区(Non-Keyed)
在定义窗口操作之前,首先需要确定,到底是基于按键分区(Keyed)的数据流 KeyedStream
来开窗,还是直接在没有按键分区的 DataStream 上开窗。也就是说,在调用窗口算子之前,
是否有 keyBy 操作。
(1)按键分区窗口(Keyed Windows)

(2)非按键分区(Non-Keyed Windows)不建议使用并行度是1

2. 代码中窗口 API 的调用

6.3.4 窗口算子实现组成之一窗口分配器(Window Assigners)

1. 时间窗口
时间窗口是最常用的窗口类型,又可以细分为滚动、滑动和会话三种。
在较早的版本中,可以直接调用.timeWindow()来定义时间窗口;这种方式非常简洁,但
使用事件时间语义时需要另外声明,程序员往往因为忘记这点而导致运行结果错误。所以在
1.12 版本之后,这种方式已经被弃用了,标准的声明方式就是直接调用.window(),在里面传
入对应时间语义下的窗口分配器。这样一来,我们不需要专门定义时间语义,默认就是事件时
间;如果想用处理时间,那么在这里传入处理时间的窗口分配器就可以了。
(1)滚动处理时间窗口
(2)滑动处理时间窗口

(3)处理时间会话窗口
(4)滚动事件时间窗口

2. 计数窗口

(1)滚动计数窗口

(2)滑动计数窗口

3. 全局窗口

6.3.5 窗口算子实现组成之二窗口函数(Window Functions)
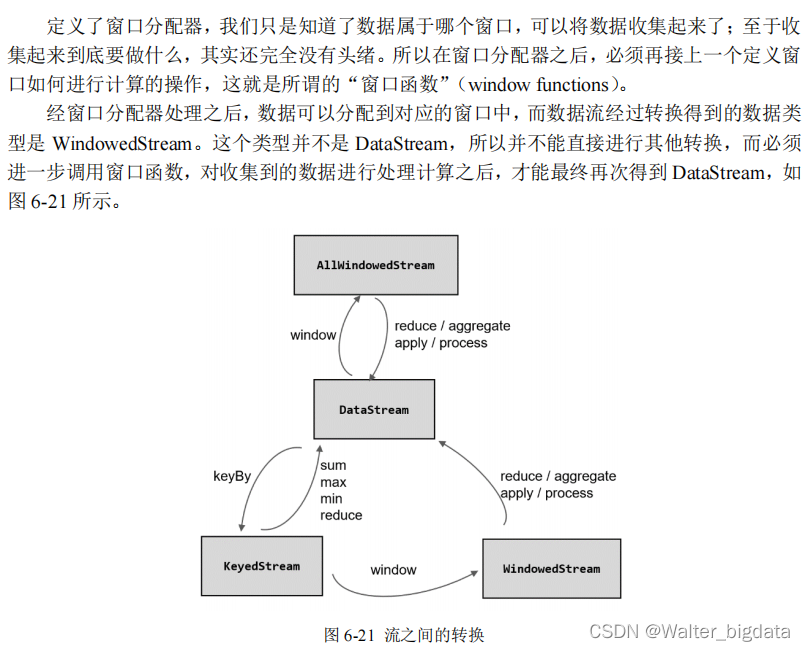
1. 增量聚合函数(incremental aggregation functions)

(1)归约函数(ReduceFunction)

package com.scy.chapter06;
import com.scy.chapter01.ClickSource;
import com.scy.chapter01.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.time.Duration;
public class WindowTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100); //生成水位线的时间间隔
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
//乱序流的watermark生成
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
})
);
stream.map(new MapFunction<Event, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(Event event) throws Exception {
return Tuple2.of(event.user,1L);
}
})
.keyBy(data -> data.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(10))) //滚动事件时间窗口
// .window(SlidingEventTimeWindows.of(Time.hours(1),Time.minutes(5))) //滑动事件时间窗口,第三个参数可以是偏移量,通常用于时区北京时间-8
// .window(EventTimeSessionWindows.withGap(Time.seconds(2))) //事件时间会话窗口
// .countWindow(10,2) //滑动计数窗口
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {
return Tuple2.of(value1.f0,value1.f1+value2.f1);
}
}).print();
env.execute();
}
}
(2)聚合函数(AggregateFunction)

public interface AggregateFunction<IN, ACC, OUT> extends Function, Serializable
{
ACC createAccumulator();
ACC add(IN value, ACC accumulator);
OUT getResult(ACC accumulator);
ACC merge(ACC a, ACC b);
}

计算每个用户时间戳的平均值
package com.scy.chapter06;
import com.scy.chapter01.ClickSource;
import com.scy.chapter01.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.sql.Timestamp;
import java.time.Duration;
public class WindowAggregateTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100); //生成水位线的时间间隔
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
//乱序流的watermark生成
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
})
);
stream.keyBy(data ->data.user)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.aggregate(new AggregateFunction<Event, Tuple2<Long,Integer>, String>() {
@Override
public Tuple2<Long, Integer> createAccumulator() { //创建初始ACC累加器
return Tuple2.of(0L,0);
}
@Override
public Tuple2<Long, Integer> add(Event value, Tuple2<Long, Integer> accumulator) { //增量叠加
return Tuple2.of(accumulator.f0 + value.timestamp,accumulator.f1 + 1);
}
@Override
public String getResult(Tuple2<Long, Integer> accumulator) { //输出最终结果
Timestamp timestamp = new Timestamp(accumulator.f0 / accumulator.f1);
return timestamp.toString() ;
}
@Override
public Tuple2<Long, Integer> merge(Tuple2<Long, Integer> a, Tuple2<Long, Integer> b) {
return Tuple2.of(a.f0+b.f0,a.f1+b.f1); //会话窗口会使用
}
}).print();
env.execute();
}
}
package com.scy.chapter06;
import com.scy.chapter01.ClickSource;
import com.scy.chapter01.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.sql.Timestamp;
import java.time.Duration;
import java.util.HashSet;
//开窗统计pv和uv,两者相除得到平均每个用户的访问次数(反应用户的粘性,活跃度)
public class WindowAggregateTest_PvUv {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100); //生成水位线的时间间隔
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
//乱序流的watermark生成
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event value, long l) {
return value.timestamp;
}
})
);
stream.print("data");
//所以数据放在一起统计pv和uv
stream.keyBy(data -> true)
.window(SlidingEventTimeWindows.of(Time.seconds(10),Time.seconds(2)))
.aggregate(new AvgPv())
.print();
env.execute();
}
//自定义一个AggregateFunction,用长整型Long保持pv个数,用hashset做uv去重
private static class AvgPv implements AggregateFunction<Event,Tuple2<Long, HashSet<String>>,Double>{
@Override
public Tuple2<Long, HashSet<String>> createAccumulator() {
return Tuple2.of(0L,new HashSet<String>());
}
@Override
public Tuple2<Long, HashSet<String>> add(Event event, Tuple2<Long, HashSet<String>> accumulator) {
//每来一条数据,pv个数加1,将user放入hashset中去重
accumulator.f1.add(event.user);
return Tuple2.of(accumulator.f0+1,accumulator.f1);
}
@Override
public Double getResult(Tuple2<Long, HashSet<String>> accumulator) {
//窗口触发时,输出pv和uv的比值
return (double)accumulator.f0/accumulator.f1.size();
}
@Override
public Tuple2<Long, HashSet<String>> merge(Tuple2<Long, HashSet<String>> longHashSetTuple2, Tuple2<Long, HashSet<String>> acc1) {
return null;
}
}
}
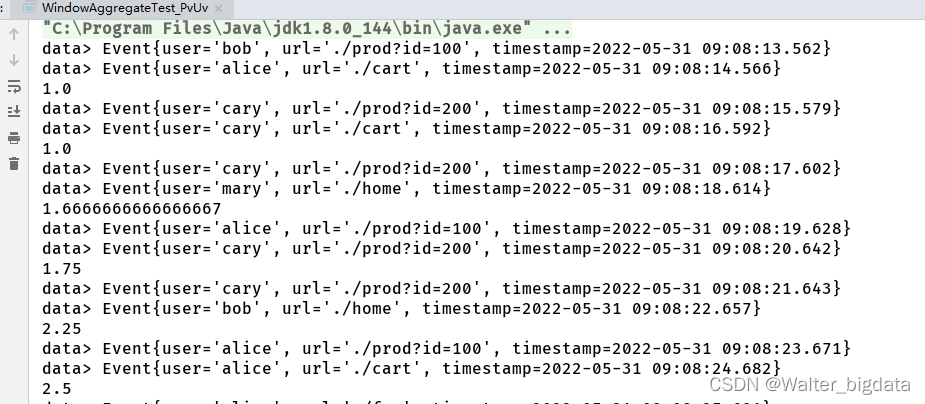
代码中我们创建了事件时间滑动窗口,统计 10 秒钟的“人均 PV”,每 2 秒统计一次。由于聚合的状态还需要做处理计算,因此窗口聚合时使用了更加灵活的 AggregateFunction。为了统计 UV,我们用一个 HashSet 保存所有出现过的用户 id,实现自动去重;而 PV 的统计则类似一个计数器,每来一个数据加一就可以了。所以这里的状态,定义为包含一个 HashSet 和一个count 值的二元组(Tuple2<HashSet, Long>),每来一条数据,就将 user 存入 HashSet,同时 count 加 1。这里的 count 就是 PV,而 HashSet 中元素的个数(size)就是 UV;所以最终
窗口的输出结果,就是它们的比值。
这里没有涉及会话窗口,所以 merge()方法可以不做任何操作。
另外,Flink 也为窗口的聚合提供了一系列预定义的简单聚合方法,可以直接基于WindowedStream 调用。主要包括.sum()/max()/maxBy()/min()/minBy(),与 KeyedStream 的简单聚合非常相似。它们的底层,其实都是通过 AggregateFunction 来实现的。
通过 ReduceFunction 和 AggregateFunction 我们可以发现,增量聚合函数其实就是在用流
处理的思路来处理有界数据集,核心是保持一个聚合状态,当数据到来时不停地更新状态。这就是 Flink 所谓的“有状态的流处理”,通过这种方式可以极大地提高程序运行的效率,所以
在实际应用中最为常见。
2. 全窗口函数(full window functions)

场景如计算中位数,需要上下文的需求
(1)窗口函数(WindowFunction)不推荐使用

(2)处理窗口函数(ProcessWindowFunction)推荐使用
ProcessWindowFunction 是 Window API 中最底层的通用窗口函数接口。之所以说它“最底
层”,是因为除了可以拿到窗口中的所有数据之外,ProcessWindowFunction 还可以获取到一个
“上下文对象”(Context)。这个上下文对象非常强大,不仅能够获取窗口信息,还可以访问当
前的时间和状态信息。这里的时间就包括了处理时间(processing time)和事件时间水位线(event time watermark)。这就使得 ProcessWindowFunction 更加灵活、功能更加丰富。事实上,ProcessWindowFunction 是 Flink 底层 API——处理函数(process function)中的一员,关于处理函数我们会在后续章节展开讲解。
当 然 , 这些好处是以牺牲性能和资源为代价的 。作为一个全窗口函数 ,ProcessWindowFunction 同样需要将所有数据缓存下来、等到窗口触发计算时才使用。它其实
就是一个增强版的 WindowFunction。
具体使用跟 WindowFunction 非常类似,我们可以基于 WindowedStream 调用.process()方
法,传入一个 ProcessWindowFunction 的实现类。
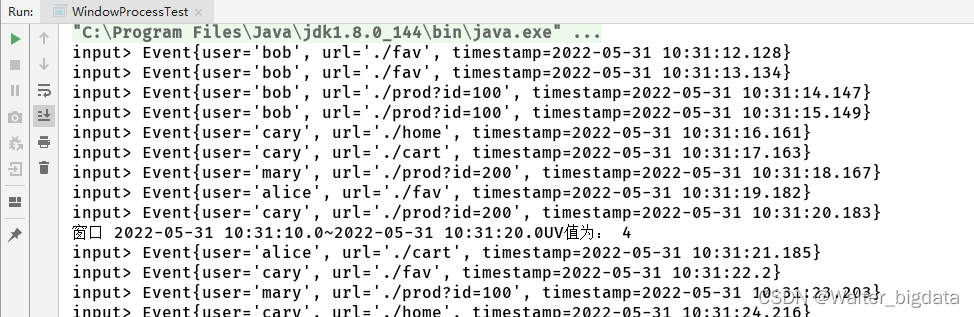
下面是一个电商网站统计每小时 UV 的例子:
package com.scy.chapter06;
import com.scy.chapter01.ClickSource;
import com.scy.chapter01.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.sql.Timestamp;
import java.time.Duration;
import java.util.HashSet;
public class WindowProcessTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100); //生成水位线的时间间隔
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
//乱序流的watermark生成
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event value, long l) {
return value.timestamp;
}
})
);
stream.print("input");
//使用ProcessWindowFunction计算UV
stream.keyBy(data -> true)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new UvCountByWindow())
.print();
env.execute();
}
//实现自定义的ProcessWindowFunction,输出一条统计信息
private static class UvCountByWindow extends ProcessWindowFunction<Event,String,Boolean, TimeWindow> {
@Override
public void process(Boolean aBoolean, Context context, Iterable<Event> elements, Collector<String> out) throws Exception {
//用一个hashset保持user
HashSet<String> userSet = new HashSet<>();
//从elements遍历数据放入hashset去重
for (Event event: elements){
userSet.add(event.user);
}
Integer uv = userSet.size();
//结合窗口信息
Long start = context.window().getStart();
Long end = context.window().getEnd();
out.collect("窗口 " + new Timestamp(start) + "~" + new Timestamp(end) + "UV值为: " + uv);
}
}
}
3. 增量聚合和全窗口函数的结合使用

这样调用的处理机制是:基于第一个参数(增量聚合函数)来处理窗口数据,每来一个数据就做一次聚合;等到窗口需要触发计算时,则调用第二个参数(全窗口函数)的处理逻辑输出结果。需要注意的是,这里的全窗口函数就不再缓存所有数据了,而是直接将增量聚合函数的结果拿来当作了 Iterable 类型的输入。一般情况下,这时的可迭代集合中就只有一个元素了。
package com.scy.chapter06;
import com.scy.chapter01.ClickSource;
import com.scy.chapter01.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.sql.Timestamp;
import java.time.Duration;
import java.util.HashSet;
public class UvCountExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100); //生成水位线的时间间隔
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
//乱序流的watermark生成
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event value, long l) {
return value.timestamp;
}
})
);
stream.print("input");
//使用AggregateFunction和ProcessWindowFunction结合计算uv
stream.keyBy(data -> true)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.aggregate(new UvAgg(),new UvCountResult())
.print();
env.execute();
}
//自定义实现AggregateFunction,增量聚合计算uv值
private static class UvAgg implements AggregateFunction<Event, HashSet<String>, Long> {
@Override
public HashSet<String> createAccumulator() {
return new HashSet<String>();
}
@Override
public HashSet<String> add(Event event, HashSet<String> accumulator) {
accumulator.add(event.user);
return accumulator;
}
@Override
public Long getResult(HashSet<String> accumulator) {
return (long) accumulator.size();
}
@Override
public HashSet<String> merge(HashSet<String> strings, HashSet<String> acc1) {
return null;
}
}
//自定义实现ProcessWindowFunction包装窗口信息输出
private static class UvCountResult extends ProcessWindowFunction<Long,String,Boolean, TimeWindow> {
@Override
public void process(Boolean aBoolean, Context context, Iterable<Long> elements, Collector<String> out) throws Exception {
Long start = context.window().getStart();
Long end = context.window().getEnd();
Long uv = elements.iterator().next();
out.collect("窗口 " + new Timestamp(start) + "~" + new Timestamp(end) + "UV值为: " + uv);
}
}
}
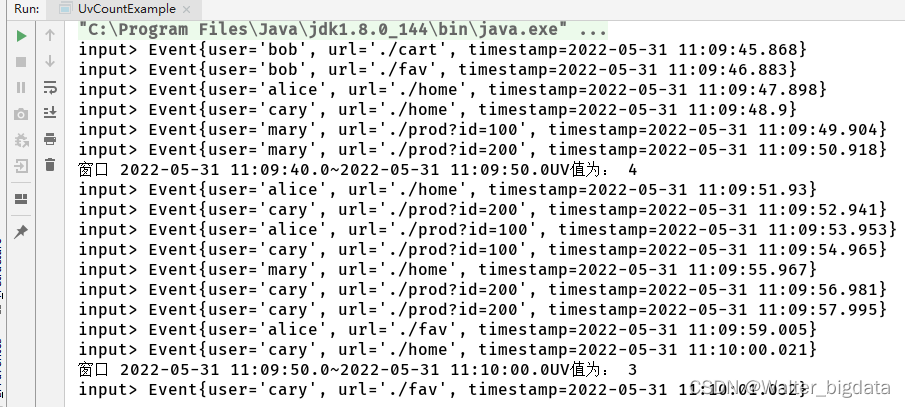
窗口函数综合应用示例

输出POJO类构造
package com.scy.chapter06;
import java.sql.Timestamp;
public class UrlViewCount {
public String url;
public Long count;
public Long windowStart;
public Long windowend;
public UrlViewCount() {
}
public UrlViewCount(String url, Long count, Long windowStart, Long windowend) {
this.url = url;
this.count = count;
this.windowStart = windowStart;
this.windowend = windowend;
}
@Override
public String toString() {
return "UrlViewCount{" +
"url='" + url + '\'' +
", count=" + count +
", windowStart=" + new Timestamp(windowStart) +
", windowend=" + new Timestamp(windowend) +
'}';
}
}
package com.scy.chapter06;
import com.scy.chapter01.ClickSource;
import com.scy.chapter01.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.sql.Timestamp;
import java.time.Duration;
public class UrlCountViewExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100); //生成水位线的时间间隔
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
//乱序流的watermark生成
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event value, long l) {
return value.timestamp;
}
})
);
stream.print("input");
//统计每个url的访问量
stream.keyBy(data -> data.url)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.aggregate(new UrlViewCountAgg(), new UrlViewCountResult())
.print();
env.execute();
}
//增量聚合,来一条数据就+1
private static class UrlViewCountAgg implements AggregateFunction<Event,Long,Long> {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(Event event, Long accumulator) {
return accumulator + 1;
}
@Override
public Long getResult(Long accumulator) {
return accumulator;
}
@Override
public Long merge(Long aLong, Long acc1) {
return null;
}
}
//包装窗口信息,输出UrlViewCount
private static class UrlViewCountResult extends ProcessWindowFunction<Long,UrlViewCount,String, TimeWindow> {
@Override
public void process(String url, Context context, Iterable<Long> elements, Collector<UrlViewCount> out) throws Exception {
Long start = context.window().getStart();
Long end = context.window().getEnd();
Long count = elements.iterator().next();
out.collect(new UrlViewCount(url,count,start,end));
}
}
}
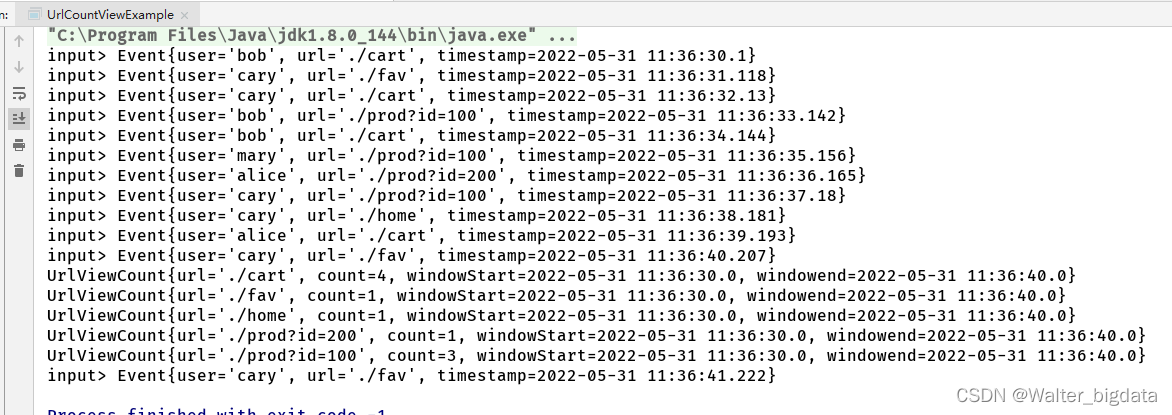
6.3.6 测试水位线和窗口的使用
6.3.7 其他 API
对于一个窗口算子而言,窗口分配器和窗口函数是必不可少的。除此之外,Flink 还提供
了其他一些可选的 API,让我们可以更加灵活地控制窗口行为。
1. 触发器(Trigger)
触发器主要是用来控制窗口什么时候触发计算。所谓的“触发计算”,本质上就是执行窗
口函数,所以可以认为是计算得到结果并输出的过程。相当于ProcessWindowFunction中的process与AggregateFunction中的getResult

- onElement():窗口中每到来一个元素,都会调用这个方法。
- onEventTime():当注册的事件时间定时器触发时,将调用这个方法。
- onProcessingTime ():当注册的处理时间定时器触发时,将调用这个方法。
- clear():当窗口关闭销毁时,调用这个方法。一般用来清除自定义的状态。可以看到,除了 clear()比较像生命周期方法,其他三个方法其实都是对某种事件的响应。onElement()是对流中数据元素到来的响应;而另两个则是对时间的响应。这几个方法的参数中都有一个“触发器上下文”(TriggerContext)对象,可以用来注册定时器回调(callback)。这里提到的“定时器”(Timer),其实就是我们设定的一个“闹钟”,代表未来某个时间点会执行的事件;当时间进展到设定的值时,就会执行定义好的操作。很明显,对于时间窗口(TimeWindow)而言,就应该是在窗口的结束时间设定了一个定时器,这样到时间就可以触发窗口的计算输出了。关于定时器的内容,我们在后面讲解处理函数(process function)时还会提到。

下面我们举一个例子。在日常业务场景中,我们经常会开比较大的窗口来计算每个窗口的
pv 或者 uv 等数据。但窗口开的太大,会使我们看到计算结果的时间间隔变长。所以我们可以
使用触发器,来隔一段时间触发一次窗口计算。我们在代码中计算了每个 url 在 10 秒滚动窗
口的 pv 指标,然后设置了触发器,每隔 1 秒钟触发一次窗口的计算。
2. 移除器(Evictor)

3. 允许延迟(Allowed Lateness)–处理数据迟到方式2


4. 将迟到的数据放入侧输出流 --处理数据迟到方式3

5.处理流式数据迟到方式三重保证示例
package com.scy.chapter06;
import com.scy.chapter01.ClickSource;
import com.scy.chapter01.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.OutputTag;
import java.io.OutputStream;
import java.time.Duration;
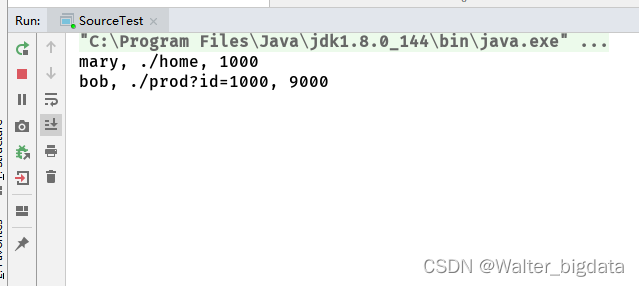
public class LateDataTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100); //生成水位线的时间间隔
SingleOutputStreamOperator<Event> stream = env.socketTextStream("node7", 7777)
.map(new MapFunction<String, Event>() {
@Override
public Event map(String s) throws Exception {
String[] fields = s.split(",");
return new Event(fields[0].trim(),fields[1].trim(),Long.valueOf(fields[2].trim()));
}
})
//乱序流的watermark生成
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(2)) //处理流式数据迟到方式三重保证之一-watermark延迟
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event value, long l) {
return value.timestamp;
}
})
);
stream.print("input");
//定义一个输出标签
OutputTag<Event> late = new OutputTag<Event>("late"){};
//统计每个url的访问量
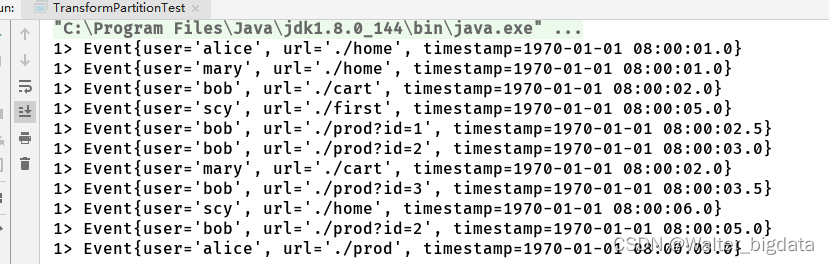
SingleOutputStreamOperator<UrlViewCount> result = stream.keyBy(data -> data.url)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.allowedLateness(Time.minutes(1)) //处理流式数据迟到方式三重保证之二-每个窗口允许延迟1分钟
.sideOutputLateData(late)//处理流式数据迟到方式三重保证之三-迟到数据放入侧输出流
.aggregate(new UrlCountViewExample.UrlViewCountAgg(), new UrlCountViewExample.UrlViewCountResult());
result.print("result");
//获取侧输出流
result.getSideOutput(late).print("late");
env.execute();
}
}
数据输入与输出展示
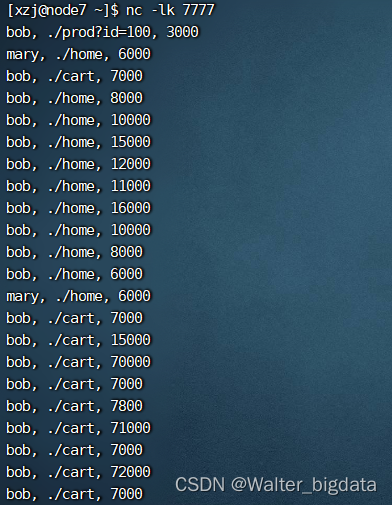

6.3.8 窗口的生命周期
6.4 迟到数据的处理

6.4.1 设置水位线延迟时间

6.4.2 允许窗口处理迟到数据

6.4.3 将迟到数据放入窗口侧输出流

6.5 本章总结


















 840
840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









