






一、Transformer
论文题目:Attention Is All You Need(NIPS2017)
Attention Is All You Need
参考视频讲解
参考笔记
Transformer的输入和输出都是序列,它使用了编码器解码器的架构,将self-attention和point-wise和全连接层堆叠起来。模型结构如下图所示,N=6。

Attention: 注意力函数是将一个query和一些key-value对映射成一个输出的函数。 输出是输入value的加权和,输出的维度和value的维度一致。每个value的权重是将value对应的key和query计算相似度得来的。自注意力的key,value和query完全相同。
Scaled Dot-Product Attention
query和key是等长的维度均为
d
k
d_k
dk,value的维度为
d
v
d_v
dv,query的个数和key-value对的个数可能不同。将query和每个key做内积作为相似度(内积越大表示相似度越高),再用一个softmax函数将所有单词的权重归一化得到的权重都是正数且和为1。

针对本模型:编码器输入n个word,经过input embedding之后生成n个
d
m
o
d
e
l
d_{model}
dmodel维的向量,故query,value和k均为
d
m
o
d
e
l
d_{model}
dmodel维的向量,共有n个key,n个value,n个query。
Multi-Head Attention


Position-wise Feed-Forward Networks
全连接Feed-Forward Networks(MLP),position-wise是把MLP对每个词都独立作用一次,完成语义的转换。

最后的Liner和Softmax层
Liner和Softmax层将解码器最终输出的实数向量变成一个word,线性变换层是全连接神经网络,将解码器产生的向量投影到一个比它大得多的、被称作对数几率(logits)的向量里。
假设模型从训练集中学习一万个不同的word,则对数几率向量为一万个单元格长度的向量,每个单元格对应某一个单词的分数。
softmax层将分数变成概率,概率最高的单元格对应的单词被作为该时间的输出。
二、Vision Transformer(ViT)
论文题目:AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(ICLR2021)
Vision Transformer
参考视频讲解
在大规模的数据集上进行预训练的情况下,不需要神经网络,利用标准transformer可解决视觉问题,进行有监督的图像分类任务。
为什么要在大规模数据集进行预训练?因为Transformer缺乏cnn所固有的一些归纳偏置,如平移不变性和局部性,在数据量不足的情况下训练时不能很好地泛化。大规模数据集可以克服归纳偏置,当ViT在足够规模的数据集上进行预先训练并迁移到具有较少数据量的任务上时,可以获得很好的效果。
将图片分割成很多个 patch,每个patch大小为16×16 ,把每个patch当作一个元素,通过全连接层得到嵌入表示作为输人传给transformer。

混合结构:
Anothor way:输入的序列可由CNN的feature map组成,代替原始图像patch。在混合结构中,将从CNN的feature map中提取的patches输入Liner Projection of Flattened Patches中。一种特殊情况是将整个feature map作为一个patch,输入序列是通过简单的平坦特征图的空间维度并投影到Transformer维度来获得的。
ViT缺陷:全局self-attention,不适应于密集预测和高分辨率图像的视觉问题。
三、Swin Transformer
论文题目:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows(ICCV2021)
原文链接
参考详解
目的: 扩大transformer的适用性,Swin transformer可被广泛用于图像分类、目标检测、语义分割等视觉任务。
将Transformer从语言领域适应到视觉领域的巨大挑战是:视觉元素在规模上有很大差异,图像的像素分辨率比段落中文字的分辨率高得多。为了解决上述差异,基于ViT的思想,提出了一个层次化的Transformer,引入移动窗口机制,将注意力的计算限制在不重叠的局部窗口,同时能让模型能够学习到跨窗口的信息。
1.总体架构:

第一层patch merging层将每组2×2的相邻patch的特征进行拼接,拼接后patch token的数量变为原来的
1
4
\frac{1}{4}
41,维度扩大四倍变为4C,然后应用线性层将输出维度降为2C,再输入到Swin Transformer中。stage2,stage3,stage4和处理与stage1类似,这些stage共同产生层次表示,具有与典型卷积网络相同的特征图分辨率。
2.W-MAS和SW-MAS
Swin Transformer中用的不是标准的多头注意力模块(MSA),而是使用的W-MAS或SW-MAS。

非重叠局部窗口中的自注意力
在非重叠局部窗口中计算self-attention,每个非重叠局部窗口都包含 M
×
\times
× M 个 patch tokens,划分方式如下图所示,红色区域表示一个窗口。

MSA和W-MSA的计算复杂度:(MSA具有h
×
\times
×w个patch tokens)
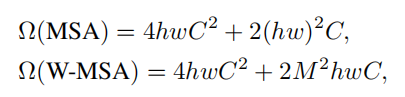
可以看出当M固定时,W-MSA具有线性复杂度。
移位窗口划分:
基于窗口的自我注意模块(W-MSA)虽将计算复杂度降为线性复杂度,但缺乏跨窗口的连接,限制了建模能力。为了更好的与其他窗口中进行信息交互,提出了一种移位窗口划分方法(SW-MSA)。 在连续的Swin Transformer中,规则窗口划分和移动窗口划分是交替进行的。
下图中左边是规则的窗口划分,从左上角像素开始,将 8
×
\times
× 8 特征图均匀划分为 2
×
\times
× 2 个大小为 4
×
\times
× 4 的窗口,窗口尺寸M=4。右边是移动窗口划分,把规则划分窗口向左上循环移位(
⌊
M
2
⌋
\left \lfloor \frac{M}{2} \right \rfloor
⌊2M⌋,
⌊
M
2
⌋
\left \lfloor \frac{M}{2} \right \rfloor
⌊2M⌋)个像素。

采用移位窗口划分方法,两个连续的Swin Transformer模块可表示为:
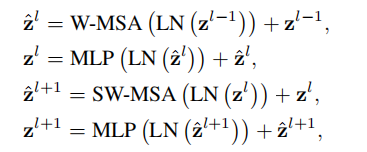
移位窗口划分会产生更多的窗口,且有的窗口的尺寸小于
M
M
M
×
\times
×
M
M
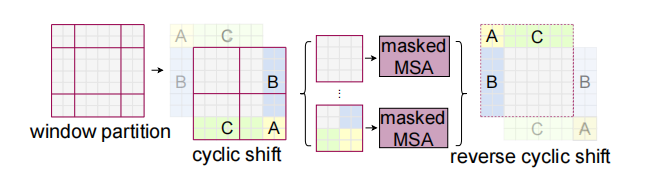
M,对此提出了一个有效的批量计算方法:循环左上方移位方法(如下图所示),在上述移位后,一个批窗口由几个特征不相邻的子窗口组成,因此使用掩码机制将自注意计算限制在每个子窗口内。
cyclic-shifting实际上就是将移动造成的非
M
M
M
×
\times
×
M
M
M像素块合并为
M
M
M
×
\times
×
M
M
M像素块。或者你可以理解为之前是窗口在移动,而现在是特征图在移动,超过左上角window的部分在右下脚进行填充!经过cyclic-shifting的调整,实际上每个像素块的大小又一致了,同时我们还实现了不同的patch之间的信息融合,且patches的个数没有发生变化。参考
相对位置偏置:

B
B
B是如何确定的?
相对位置索引=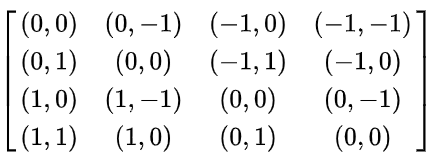
然后对相对位置索引进行了一些线性变换,使得能通过一维的位置坐标唯一映射到一个二维的位置坐标。具体参考















 989
989











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









