




亿级分布式系统架构演进实战(一)- 总体概要
亿级分布式系统架构演进实战(二)- 横向扩展(服务无状态化)
亿级分布式系统架构演进实战(三)- 横向扩展(数据库读写分离)
核心目标
智能分发流量,动态调配全栈资源
1. 负载均衡策略优化
1.1 故障转移与节点恢复流程
故障转移与节点恢复流程
Nginx开启健康检查
http {
upstream backend {
zone backend_zone 64k;
# 节点管理策略
server 10.0.0.1:8080 max_fails=3 fail_timeout=300s;
server 10.0.0.2:8080 max_fails=3 fail_timeout=300s;
# 主动健康检查
health_check
uri=/health
interval=5s
fails=3
passes=2
match=service_ready
persistent=on; # 保持状态避免抖动
}
# 健康检查匹配规则
match service_ready {
status 200;
header "X-Status" ~ "^OK$";
body ~ "ready";
response_time < 2s;
}
}
关键参数说明:
max_fails=3:允许连续失败3次
fail_timeout=300s:节点移除后300秒内不重试
persistent=on:状态持久化防止网络抖动误判
Nginx暴露指标配置
server {
listen 9145;
# Prometheus指标端点
location /metrics {
allow 10.0.0.0/8;
deny all;
nginx_status_dump; # Nginx Plus专属模块
}
}
如果对费用敏感,选择nginx开源版本也可以实现。
Prometheus告警规则配置
# alert_rules.yml
groups:
- name: nginx-alerts
rules:
- alert: NodeDown
expr: nginxplus_upstream_peer_state == 0
for: 2m
labels:
severity: critical
annotations:
summary: "节点离线: {{ $labels.peer }}"
description: "服务节点已连续3次健康检查失败"
- alert: NodeRecovered
expr: nginxplus_upstream_peer_state == 1
for: 1m
labels:
severity: info
annotations:
summary: "节点恢复: {{ $labels.peer }}"
2. 多维度弹性伸缩规则
对于弹性伸缩方案选择方向有两个,一个是根据运行指标自动伸缩,一个是根据运行指标预警运维人员手动进行资源伸缩。我们选择了第二个方案,后续会加以说明为什么这么选择。(注:目前专注于扩容方案)
2.1 扩缩容对象分类
| 资源类型 | 监控指标 | 预警阈值 | 检测频率 |
|---|---|---|---|
| 应用节点 | CPU/Mem | >75% 持续10分钟 | 1分钟 |
| 数据库 | 连接池利用率/Query延迟 | >80% 或 >500ms | 30秒 |
| 消息队列 | 积压消息数/消费延迟 | >50,000条 | 2分钟 |
| 带宽 | 出入流量峰值/丢包率 | >85% 或 >3% | 5分钟 |
2.2 综合瓶颈分析决策树
2.3 基于监控预警的手动伸缩方案
此方案优势:
风险可控:规避全自动系统的级联故障风险
成本可见:防止意外资源膨胀导致费用失控
精准调整:结合业务场景选择最佳扩容策略
Prometheus告警规则配置
# alert_rules.yml
groups:
- name: scaling-alerts
rules:
- alert: AppNodeHighCPU
expr: 100 * (1 - avg(rate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance)) > 75
for: 10m
annotations:
severity: warning
action: "检查应用性能或扩容节点"
- alert: DBHighConnections
expr: pg_stat_activity_count{datname!~"template.*"} > (pg_settings_max_connections * 0.8)
for: 5m
annotations:
severity: critical
action: "增加只读副本或优化SQL"
2.4 基于监控预警的手动伸缩方案优势
自动扩缩容风险分析
| 资源类型 | 技术复杂度 | 潜在风险 |
|---|---|---|
| 应用节点 | Pod启动时间依赖镜像大小 | 快速扩容导致新节点过载,产生级联故障 |
| 数据库 | 主从同步延迟影响数据一致性 | 自动增加只读副本可能造成业务逻辑错乱 |
| 消息队列 | 分区重平衡影响消费顺序 | 自动扩分区导致消费者组重组,关键业务消息顺序错乱 |
| 带宽 | 云服务商计费周期限制 | 突发扩容产生高额账单,降级操作有最低限制 |
手动扩缩容优势
业务感知调整
• 区分促销活动流量与异常流量
• 选择纵向扩容(提升配置)或横向扩容(增加实例)
规避数据风险
成本精细控制
| 操作类型 | 自动系统耗时 | 人工操作耗时 | 成本差异 |
|---|---|---|---|
| 应用节点扩容 | 2分钟 | 5分钟 | ±$0 |
| 数据库升配 | 1分钟 | 8分钟 | 节省$200+ |
| 带宽突发扩容 | 即时生效 | 15分钟 | 节省$1500+ |
3. 智能预扩容机制
3.1 基于时序预测的扩容
Prophet算法预测流量
from prophet import Prophet
import pandas as pd
# 加载历史QPS数据
df = pd.read_csv('qps_history.csv')
df['ds'] = pd.to_datetime(df['timestamp'])
df['y'] = df['qps']
# 训练预测模型
model = Prophet(seasonality_mode='multiplicative')
model.fit(df)
# 生成未来6小时预测
future = model.make_future_dataframe(periods=6, freq='H')
forecast = model.predict(future)
# 触发预扩容条件
if forecast['yhat'].max() > current_capacity * 1.3:
pre_warm_resources()
利用Prophet算法预测流量,发出预警,运维人员判断是否需要提前扩容。
4. 服务降级与流量治理
4.1 多级熔断策略
Sentinel多维熔断规则
// 应用层熔断
DegradeRule appRule = new DegradeRule("appService")
.setGrade(GRADE_EXCEPTION_RATIO)
.setCount(0.6) // 异常率>60%
.setTimeWindow(60);
// 数据库层熔断
DegradeRule dbRule = new DegradeRule("mysqlService")
.setGrade(GRADE_RT)
.setCount(500) // 响应时间>500ms
.setTimeWindow(30);
4.2 全局流量调度
基于地域的权重分配
upstream backend {
server 10.0.0.1:8080 weight=5; # 主区域
server 10.0.0.2:8080 weight=3; # 备区域1
server 10.0.0.3:8080 weight=2; # 备区域2
server 10.0.0.4:8080 backup; # 灾难恢复区域
}
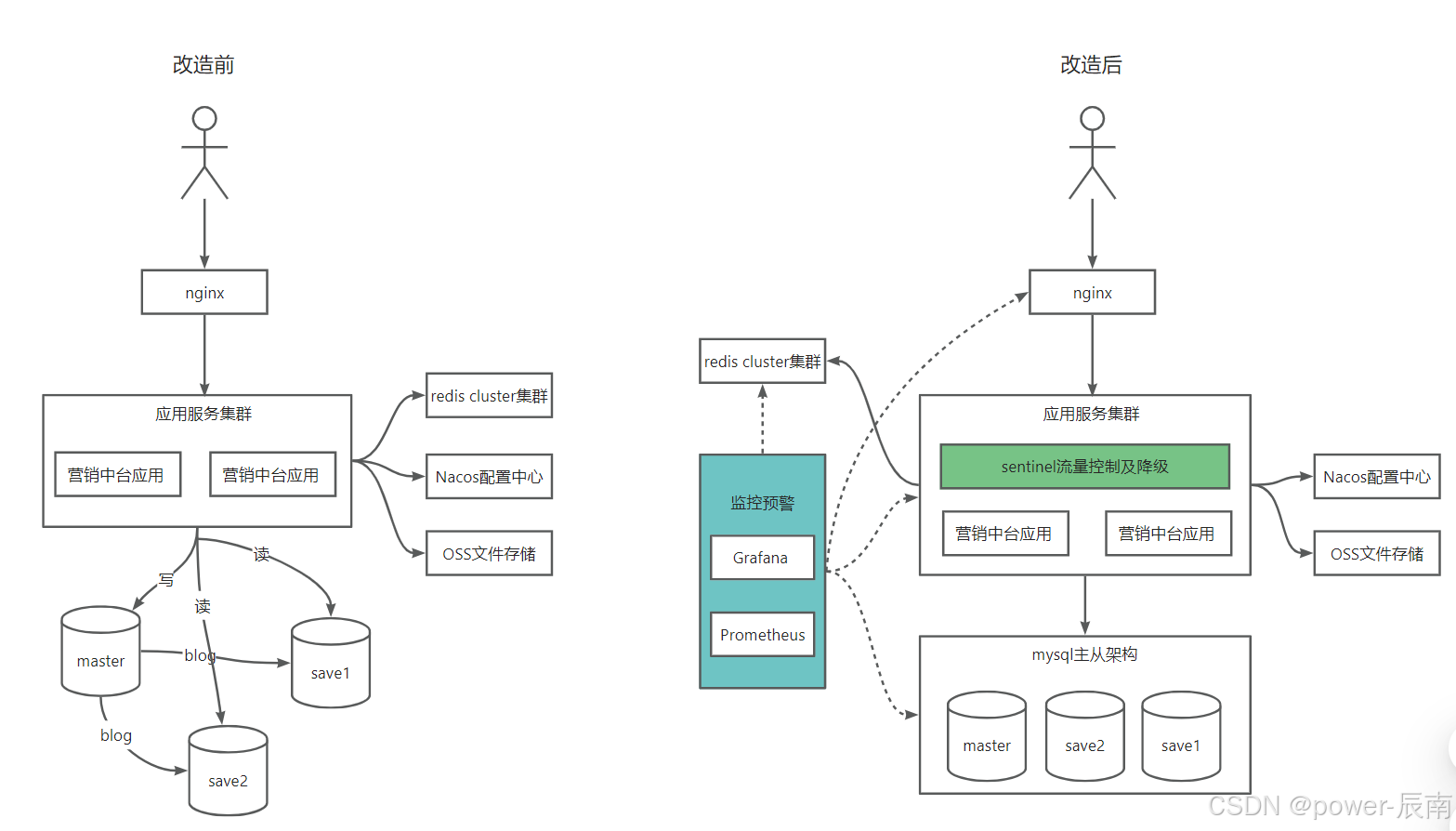
5. 升级效果
总结:
1、利用Prometheus+nginx实现节点下线及恢复。
2、利用Prometheus指标预警,及时对应用服务资源、数据库服务资源、消息服务资源、带宽资源等资源及时进行伸缩处理。
3、利用sentinel对系统流量进行限流及对服务实现降级、熔断处理。
通过以上改造,营销中台系统能够及时感知服务是否健康,资源是否吃紧,以便快速响应及处理。并通过对流量限流、服务降级/熔断等处理,很好的提升系统整体稳定性。



















 909
909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











