






今年Intel的线程挑战赛已经开始了,以下是我的解决方案。如果您觉得文章对您有用,请投我一票,谢谢!
投票地址:http://intel.csdn.net/multicoreblog/show.aspx
问题描述
给出一组含有关键字的未排序字符串,这些关键字可视为整数的二进制表示,关键字内的各个位可以用来对这组字符串进行排序。这种排序方法被称为基数排序。
请编写一个用多线程实现基数排序算法的程序:对从输入文件读取的关键字进行排序,然后将排序后的关键字输出到另一个文件。输入文件名和输出文件名应为执行程序命令行的第一和第二个参数。
输入文件中的第一行是要排序的关键字总个数 (N);后面紧跟 N 个关键字,每行一个;关键字是由 7 个可打印字符组成的字符串,不含空格 (ASCII 0x20)。文件中关键字的个数小于 2^31 – 1。排序后的输出结果必须保存在文本文件中,每行一个关键字;
计时:如果您在程序中加入计时代码来计算排序过程所用的时间并报告已用的时间,将用这个时间来计分;如果不加入计时代码,将使用整个执行时间(包括输入时间和输出时间)来计分。
输入文件样例:
8
H@skell
surVEYs
sysTEMS
HASKELL
Surveys
1234567
SURveys
systEMS
输出文件样例:
1234567
H@skell
HASKELL
SURveys
Surveys
surVEYs
sysTEMS
systEMS
串行算法
“基数排序法”(radix sort)则是属于“分配式排序”(distribution sort),基数排序法又称“桶子法”(bucket sort)或bin sort,顾名思义,它是透过键值的部份资讯,将要排序的元素分配至某些“桶”中,藉以达到排序的作用,基数排序法是属于稳定性的排序,其时间复杂度为O (nlog(r)m),其中r为所采取的基数,而m为堆数,在某些时候,基数排序法的效率高于其它的比较性排序法。
基数排序的方式可以采用LSD(Least significant digital)或MSD(Most significant digital),LSD的排序方式由键值的最右边开始,而MSD则相反,由键值的最左边开始。
显然MSD更适合并行处理,我们只需要像快速排序那样按照指定的bit位为1的和为0的分开,让为0的在前面,为1的在后面就可以了,然后递归由高到低的处理每个bit位。
本问题需要排序的为7个字符,共7 * 8 = 56 bit,加上换行符共64bit刚好可以放入一个int64变量中。
下面给出不使用小数据排序展开优化的源码,使用展开的代码较长,就不放入文档中了。
//基数排序,返回分割点不使用展开优化
__inline uint64* XPartition64(uint64* pBeg, uint64* pEnd, uint64 nBitMask)
{
//判断如果少于一个数据无需排序
if(pBeg + 1 < pEnd)
{
uint64 *i = pBeg - 1, *j = pEnd;
while ((++i) < pEnd && (*i & nBitMask) == 0);
while ((--j) > pBeg && (*j & nBitMask));
while (i < j)
{
const uint64 t = *i; *i = *j; *j = t;
do ++i; while ((*i & nBitMask) == 0);
do --j; while ((*j & nBitMask));
}
return i;
}
else
{
return NULL;
}
};
//基数排序_串行版本
void XRadixSort64Serial(uint64* pBeg, uint64* pEnd, uint64 nBitMask)
{
uint64* pSplit = XPartition64(pBeg, pEnd, nBitMask);
if(pSplit != NULL && nBitMask != XRADIX_MASK_END)
{
XRadixSort64Serial(pBeg, pSplit, XRADIX_MASK_SHIFT_64(nBitMask));
XRadixSort64Serial(pSplit, pEnd, XRADIX_MASK_SHIFT_64(nBitMask));
}
}
代码跟快速排序的代码几乎一致,只是对比较方法及分割位置的处理有些不同,用红色字体标出。
并行算法
分裂式的算法,采用TBB的Task做并行优化是个不错的选择。一次分裂出两个Task,分裂出的Task可以并行处理,彼此之间没有共享数据,可以完全并行。
// 基数排序Task
class CXRadixSort64Task: public tbb::task
{
uint64 *m_pBeg,*m_pEnd,m_nBitMask;
BOOL m_bIsContinuation;
static uint32 ms_nCutOff32;
public:
CXRadixSort64Task( uint64* pBeg, uint64* pEnd, uint64 nBitMask) :
m_pBeg(pBeg), m_pEnd(pEnd), m_nBitMask(nBitMask), m_bIsContinuation(FALSE) { }
tbb::task* execute()
{
tbb::task *pNextA = NULL, *pNextB = NULL;
if(m_pEnd - m_pBeg < ms_nCutOff32)
{ // 基数排序_串行版本
XRadixSort64Serial(m_pBeg, m_pEnd, m_nBitMask);
}
else
{
if( !m_bIsContinuation )
{ // 移动数据并得到分割点
uint64* pSplit = XPartition64(m_pBeg, m_pEnd, m_nBitMask);
if(pSplit != NULL)
{ // 分裂新的Task
pNextA = new( allocate_child() ) CXRadixSort64Task(m_pBeg, pSplit,
XRADIX_MASK_SHIFT_64(m_nBitMask));
pNextB = new( allocate_child() ) CXRadixSort64Task(pSplit, m_pEnd,
XRADIX_MASK_SHIFT_64(m_nBitMask));
m_bIsContinuation = TRUE;
recycle_as_continuation();
set_ref_count(2);
spawn(*pNextB);
}
}
}
return pNextA;
}
static void SetCutOff(uint32 nCutOff)
{
if(nCutOff < 1024)
ms_nCutOff32 = 1024;
else if(nCutOff > XRADIXSORT_CUTOFF)
ms_nCutOff32 = XRADIXSORT_CUTOFF;
else
ms_nCutOff32 = nCutOff >> 10 << 10;
}
};
// 基数排序_并行版本
void XRadixSort64Parallel(uint64* pBeg, uint64* pEnd, uint64 nBitMask)
{
// 计算CUTOFF值
uint32 nSize = (uint32)(pEnd - pBeg) / task_scheduler_init::default_num_threads() / 4;
CXRadixSort64Task::SetCutOff(nSize);
CXRadixSort64Task& xtask = *new(tbb::task::allocate_root())
CXRadixSort64Task(pBeg, pEnd, nBitMask);
tbb::task::spawn_root_and_wait(xtask);
}
在Task处理前先判断数据量的大小,如果小于ms_nCutOff32个数据可直接调用串行算法,减少Task的数量,降低TBB维护Task的开销。ms_nCutOff32的大小根据待排序数组的大小进行动态调整,最大为64k。
优化工具
Hotspots检测
![]()
使用Intel Amplifier的Hotspots检测功能查找热点函数,结果如下:
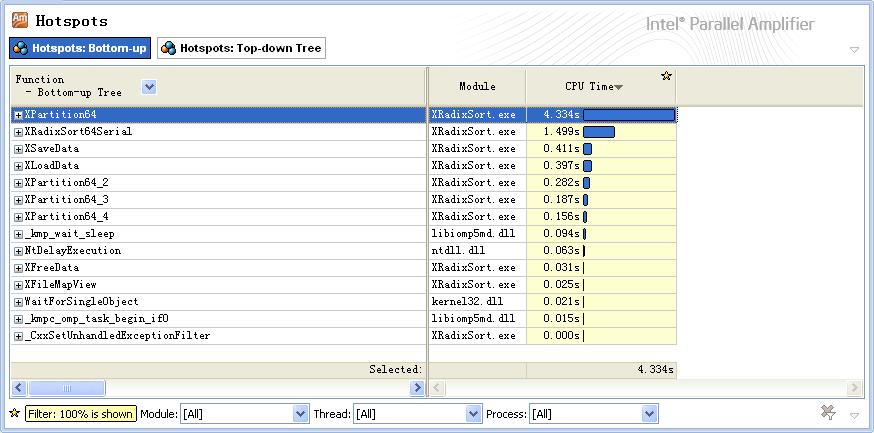
主要的时间开销都在函数XPartition64内,优化该函数能得到最大的性能提升。
Concurrency检测
![]()
使用Intel Amplifier的Concurrency检测功能查找可进行并行优化的代码,结果如下:
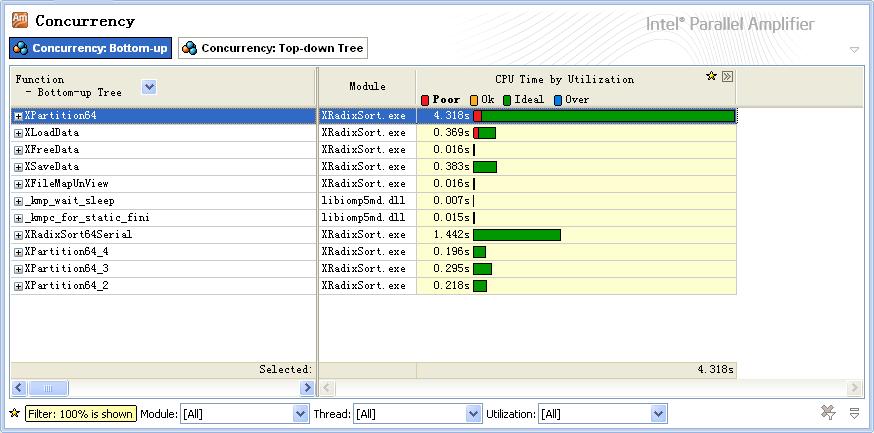
XLoadData和XSaveData使用了内存映射,同时使用OpenMp做了并行优化,由于比赛不统计输入输出的时间所以这部分代码没有做太多优化。
另外在排序刚开始的时候,XPartition64存在串行执行的部分,原因在于第1层调用只有1个Task可以执行,第2层调用只有2个Task可以执行,第3层调用只有4个Task可以执行,第n层调用只有2 ^ n个Task可以执行.测试平台为16核系统,至少要到第5层调用16个核才能开始完全并行,所以这部分串行执行的时间与核的数量成正比,这部分串行执行时间,任然是需要进行优化的。这样就需要在前期执行时使用并行版本的XPartition64函数。由于时间有限就不再做这部分优化了。
Locks and Waits检测
![]()
使用Intel Amplifier的Locks and Waits检测功能查找锁和同步等待消耗,结果如下
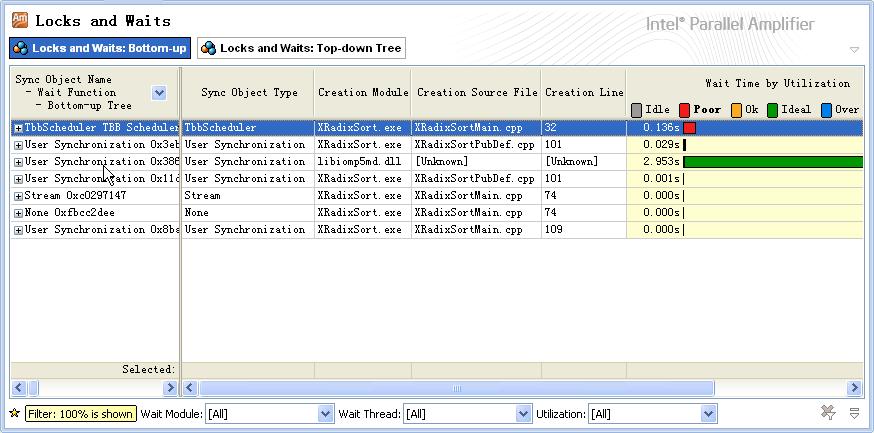
结果显示存在136ms的同步消耗,不存在较严重的同步和锁消耗。
其他优化
1. 在32位平台下int64的运算的开销较大,在32位平台上可以分别处理高32bit和低32bit提高效率。见函数XPartition32H和XPartition32L。
2. 可见字符的高bit位均为零,可以利用这个规律对数据进行压缩,在数据加载的时候将数据压缩到49个比特位,后来看到haojn的提问及Clay Breshears的解答,否定了压缩方案,因为数据压缩的开销比较大。但是可以采取另外一种方案来加速,在右移动BitMask的时候,直接跳过每个字节的高位,具体见XRADIX_MASK_SHIFT_32和XRADIX_MASK_SHIFT_64宏函数。
3. 对较少的数据(2个,3个,4个)的排序展开。分别为XPartition64_2,XPartition64_3,XPartition64_4减少比较和内存搬运的次数,提高效率。
4. 在数据加载和保存的时候利用OpenMp进行并行优化。
性能测试
小数据量测试:
操作系统: 32bit的测试在32位XP下完成。
64bit的测试在64位XP下完成。
CPU: Intel(R) Core(TM)2 CPU 5270 @ 1.40GHz
内存: 1G
时间单位: 秒
| 测试数据 | 32bit串行 | 32bit并行 | 加速比 | 64bit串行 | 64bit并行 | 加速比 |
| 100k | 0.021771 | 0.011811 | 1.84 | 0.016750 | 0.009149 | 1.83 |
| 1M | 0.232440 | 0.120195 | 1.93 | 0.195054 | 0.105122 | 1.86 |
| 10M | 2.446142 | 1.355823 | 1.80 | 2.124676 | 1.203946 | 1.76 |
大数据测试:
操作系统: Red Hat Enterprise Linux AS release 4 (Nahant Update 2)
CPU: Intel(R) Core(TM)2 CPU 6320 @ 1.86GHz
内存: 4G
测试数据: 250M条数据
测试结果: 36.790519 seconds!
编译说明
Windows平台:
使用VS2008和Intel Parallel Studio
1. 用VS2008打开本项目.
2. 选择X64平台Relase编译.
3. 进入Bin目录执行文件为XRadixSort.exe.
Linux平台:
使用ICC和TBB
1. 上传压缩包种的Src和Linux两个目录到服务器上.
2. 进入XRadixSort/Linux目录 执行make
3. 进入XRadixSort/Bin目录 执行文件为XRadixSort.
其他:
如果不允许在加载数据时改变字节序,请注释XRadixSortPubDef.h第53行的
X_SWAP_ON_READ宏定义。
优化结论
通过使用Intel Parallel Studio集成了编译器,TBB,IPP,OpenMp以及Amplifier和Inspector,通过使用这些工具我完成了基数排序的并行优化,虽然这个并行优化还没有做到极限,但是已经达到了我预期的效果。
Amplifier能够简单快速的检测到多线程程序的并行性能缺陷,找出需要优化的代码,是并行优化不可或缺的优化工具。
Inspecto也能对程序的内存错误及线程错误进行检测,能很方便的检测多线程程序的常见错误,特别同步方面的错误。是多线程程序调试的极佳选择。
致谢
感谢Clay Breshears所做的解答,感谢Mu,Pryce和Xia, JeffX P友好的通知我参加比赛,感谢haojn在论坛上的讨论的回复,让我修改了原来的bit压缩处理方案否则我的解决方案可能不被认可。















 579
579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









