






2009 英特尔® 线程挑战赛—线段求交
问题描述
问题:编写一段多线程代码,使用 Strassen 算法将两个随机矩阵相乘。应用程序将生成两个矩阵:A(M,P) 和 B(P,N),您需要使用 (1) 串行算法和 (2) Strassen 算法将它们相乘,得到乘积 C(M,N)。然后比较这两种算法的计算结果,确保使用 Strassen 算法得到的结果与使用串行算法得到的结果一致。
通过命令行输入应用程序参数值。输入的值将是 3 个整数(M、N 和 P),用来描述要使用的矩阵的大小。
代码限制:我们会预先提供一个用 C 语言编写的非常简单的串行计算应用程序。您应该在此源文件的基础上添加多线程代码,保留原来 main 函数、矩阵生成函数、串行乘法代码以及矩阵乘积结果比较函数的主体部分。如果要用其他语言实现,可以对这些代码做相应的更改。另外还可以更改内存分配和其他代码,以便实现 Strassen 计算的线程化。(建议您在编写代码时记下所做的更改以及进行这些更改的理由。)完成更改后,您提交的解决方案必须使用某种形式的 Strassen 算法计算出第二个矩阵乘积。
串行算法
原始的矩阵乘法为复杂度均为O(n^3),当矩阵足够大时,计算效率会非常低下,1969年提出的Strassen 矩阵乘法采用分治法,将A和B各分为四个子矩阵进行运算,降低了矩阵乘法的复杂度,算法如下:
S1 = A00 + A11 M1 = S1 x S6 C00 = M1 + M4 – M5 + M7
S2 = A10 + A11 M2 = S2 x B11 C01 = M3 + M5
S3 = A00 + A01 M3 = A00 x S7 C10 = M2 + M4
S4 = A10 – A00 M4 = A11 x S8 C11 = M1 + M3 – M2 + M6
S5 = A01 – A11 M5 = S3 x B11
S6 = B00 + B11 M6 = S4 x S9
S7 = B01 – B11 M7 = S5 x S10
S8 = B10 – B00
S9 = B00 + B01
S10 = B10 +B11
共采用7次乘法和18次加减法运算。
Winograd Strassen是一种变形的矩阵乘法,其原理相同,算法如下:
S1 = A10 + A11 M1 = S2 x S6 T1 = M1 + M2 C00 = M2 + M3
S2 = S1 - A00 M2 = A00 x B00 T2 = T1 + M4 C01 = T1 + M5 + M6
S3 = A00 - A10 M3 = A01 x B10 C10 = T2 - M7
S4 = A01 - S2 M4 = S3 x S7 C11 = T2 + M5
S5 = B01 - B00 M5 = S1 x S5
S6 = B11 - S5 M6 = S4 x B11
S7 = B11 - B01 M7 = A11 x S8
S8 = S6 - B10
共采用7次乘法和15次加减法运算。
由于少3次加减法运算,所以Winograd效率会高于标准的Strassen 矩阵算法,但这两种算法的复杂度均为O(n^2.81)。
为提高效率,采用SSE2指令优化小块矩阵乘法运算C = A x B及C += A x B,见函数XSM_Mul_Small和XSM_MulAdd_Small,数据要求:矩阵的数据指针pA,pB,pC均为16字节对齐,n必须为16的倍数,p必须为2的倍数.
由于矩阵运算的数据量较大,cache命中率显得非常重要,所以对于中等尺寸的矩阵乘法采用先计算A00 x B00,A00 x B01,A10 x B01,A10 x B00再计算A01 x B10,A01 x B11,A11 x B11,A11 x B10的方法提高cache命中率。
Winograd Strassen矩阵乘法是一个递归算法,而且需要在递归函数内部使用内存保存中间结果S1—S8,M1—M7,T1,T2。如果在递归函数内存动态分配的方式,时间开销会比较大,所以采用在外部根据M,N,P的值计算整个递归需要的临时数据空间,动态分配后,传入递归函数内使用,降低时间开销。
并行算法
通过使用TBB的Task,可以很方便的将递归算法并行化,在tbb::task* execute()中分裂7个子Task分别计算M1—M7即可实现Strassen矩阵乘法的并行优化。主要代码如下:
tbb::task* execute()
{
if (m_nDepth == m_stUseOneMemoryDepth)
{ // 进入串行算法内,降低内存分配和多线程调度开销
XSM_Mul_Serial(m_nM, m_nN, m_nP, m_pA, m_nWidthA, m_pB, m_nWidthB, m_pC, m_nWidthC);
}
else
{
tbb::task_list list;
……
// M1 = S2 x S6
list.push_back( *new( allocate_child() ) CXSMMulTask(…));
// M2 = A00 x B00
list.push_back( *new( allocate_child() ) CXSMMulTask(…));
// M3 = A01 x B10
list.push_back( *new( allocate_child() ) CXSMMulTask(…));
// M4 = S3 x S7
list.push_back( *new( allocate_child() ) CXSMMulTask(…));
// M5 = S1 x S5
list.push_back( *new( allocate_child() ) CXSMMulTask(…));
// M6 = S4 x B11
list.push_back( *new( allocate_child() ) CXSMMulTask(…));
// M7 = A11 * S8
list.push_back( *new( allocate_child() ) CXSMMulTask(…));
set_ref_count(8);
spawn_and_wait_for_all(list);
……
}
return NULL;
}
// Strassen矩阵乘法,并行版本
void XSM_Mul_Parallel(int m, int n, int p, XMType* pA, int nWidthA,
XMType* pB, int nWidthB, XMType* pC, int nWidthC)
{
tbb::task_scheduler_init init;
// 获取深度
int nDepth = XSM_Mul_GetDepth(m, n, p);
// 控制Task数量应为7 * 7 = 49 次调用串行算法
CXSMMulTask::SetUseOneMemoryDepth(max(0, nDepth - 2));
CXSMMulTask& xtask = *new(tbb::task::allocate_root()) CXSMMulTask(m, n, p, pA, nWidthA, pB, nWidthB, pC, nWidthC, nDepth);
tbb::task::spawn_root_and_wait(xtask);
}
在Task处理前先判断递归深度是否小于m_stUseOneMemoryDepth,如果是可直接进入串行计算,减少Task的数量,降低TBB维护Task的开销,同时减少动态内存分配的时间消耗。由于测试机位16核,所以的m_stUseOneMemoryDepth是根据为nDepth – 2,最低层的Task数量为7 * 7 = 49个。
优化工具
Hotspots检测
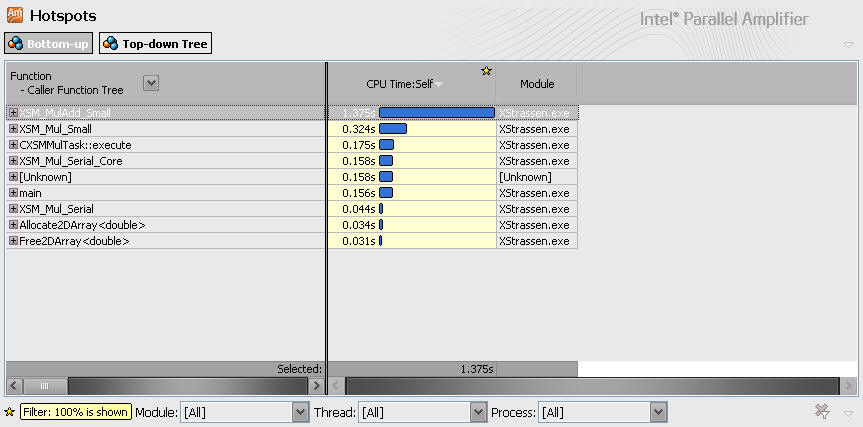
使用Intel Amplifier的Hotspots检测功能查找二分查找算法的热点函数,结果如下:
检测结果显示热点函数在XSM_MulAdd_Small中,该函数已经采用SSE2指令优化。
Concurrency检测
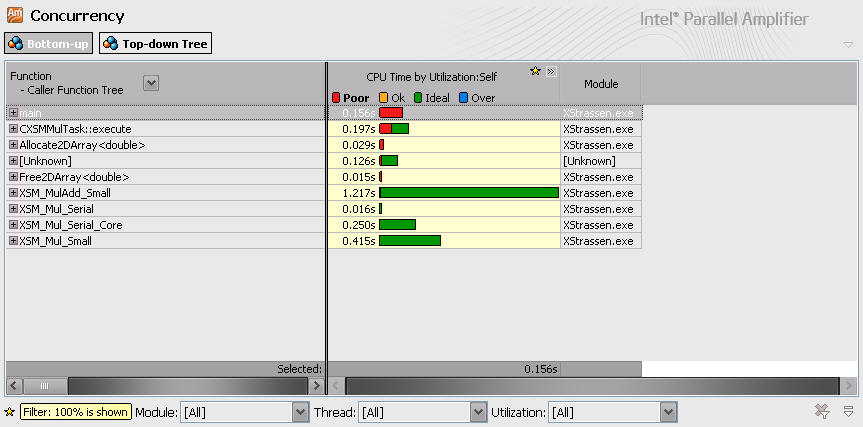 使用Intel Amplifier的Concurrency检测功能查找可进行并行优化的代码,结果如下:
使用Intel Amplifier的Concurrency检测功能查找可进行并行优化的代码,结果如下:
检测结果显示,main函数是完全串行的,占整个运行时间的比例较小,XSM_MulAdd_Small函数并行度较好,执行时间也比较长。
Locks and Waits检测
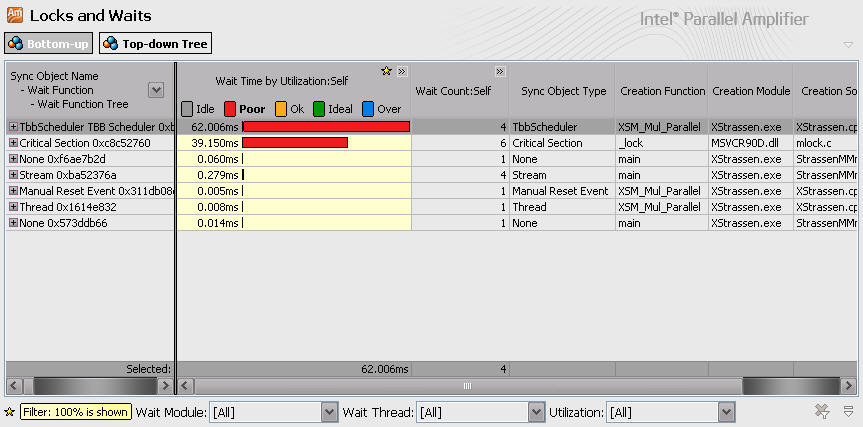 使用Intel Amplifier的Locks and Waits检测功能查找两种算法的锁和同步等待消耗,结果如下:
使用Intel Amplifier的Locks and Waits检测功能查找两种算法的锁和同步等待消耗,结果如下:
检测结果显示使用Task有不到100ms的锁和等待消耗。
其他优化
通过XSM_Mul_AdjustSize函数扩展M,N,P的值为MM,NN,PP以支持任意尺寸的矩阵乘法。调整后的MM,NN,PP在满足XSM_MulAdd_Small的数据要求的同时保证MM-M,NN-N,PP-P最小。
性能测试
操作系统: 32bit的测试在32位XP
CPU: Intel(R) Core(TM)2 5670 @ 1.80GHz
内存: 1G
时间单位: 秒
| M,N,P | 原始串行乘法 | 串行Strassen | 并行Strassen |
| 512,512,512 | 1.88 | 0.09 | 0.08 |
| 1024,1024,1024 | 39.16 | 0.63 | 0.47 |
| 2048,2048,2048 | 324.44 | 4.45 | 3.27 |
| 4096,2048,2048 | N | 8.70 | 6.33 |
编译说明
Windows平台:
使用VS2008和Intel Parallel Studio
1. 用VS2008打开本项目.
2. 选择Relase编译.
3. 进入Bin目录执行文件为XStrassen.exe.
Linux平台:
使用ICC和TBB
1. 上传压缩包种的Src和Linux两个目录到服务器上.
2. 进入XStrassen/Linux目录 执行make
3. 进入XStrassen/Bin目录 执行文件为XStrassen.
其他:
主办方请使用Win32平台Release版本测试,谢谢!
优化结论
通过Intel Parallel Studio和TBB,实现了Strassen矩阵乘法的并行优化,由于串行算法采用了单一内存分配,效率较高,而并行算法依然存在动态内存分配部分,导致效率降低,所以在双核PC上加速比较低,希望在16核的测试机上能有更好的结果。
致谢
感谢Clay Breshears所做的解答,感谢Mu,Pryce为本文章发表到ISN所做的工作,感谢Xia, JeffX P为我的解决方案进行了认真细致的翻译。















 820
820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









