






深度学习需要EBM的基础(EBM读书笔记),了解EBM后,需要学习大牛Yoshua Bengio的文章“Learning Deep Architectures for AI”,本文翻译部分内容,并加入自己理解。可能有错误,希望批判的参考。
1.引言
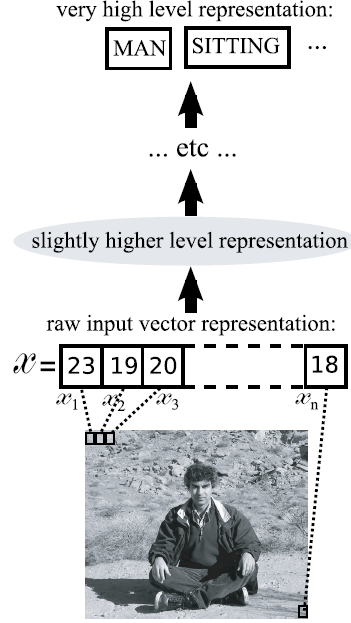
人的神经实际上就是一层层传递的过程。一个典型的图像如下图所示:
4.深层架构的神经网络
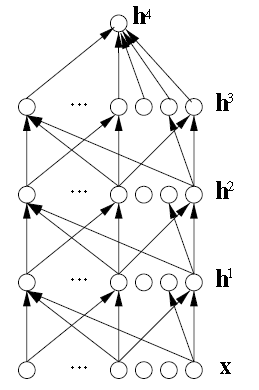
图:sigmoid信念网络
规定\(x=h^0\),则上图中层之间的一个典型的传递公式是:
\(h^k=tanh(b^k+W^kh^k-1)\)
其中,\(b\)是偏置,而\(W\)是权重,\(tanh\)是一个应用元素智能,能被替代为\(sigm(u)=1/(1+e^{-u}=\frac{1}{2}(tanh(u)+1)\).顶层\(h^l\)被用来做预测和被监督的目标y联合在一起用在损失函数:\(L(h^l,y)\),典型的如\(b^l+W^lh^{l-1}\),输出层有可能是非线性的:
\(h_i^l=\frac{e^{b_i^l+W_i^lh^{l-1}}}{\sum_je^{b_j^l+W_j^lh^{l-1}}}\)
其中,\(W_i^l\)是\(W^l\)的第\(i\)行,\(h_i^l\)是一个正数,并且\(\sum_ih_i^l=1\).softmax函数的输出\(h_i^l\)可以用作估计概率\(P(Y=i|X)\),在这种情况下热门经常用负条件对数似然\(L(h^l,y)=-logP(Y=y|x)=-logh_y^l\)作为损失,最小化就可以得到期望值。
4.4深层繁殖架构
在一个sigmoid信念网络中,当给定上一层的单元值时,本层的单元之间是相互独立的,典型的分布类似于下面的神经激活等式:
\(P(h_i^k=1|h^{k+1}=sigm(b_i^k+\sum_jW_{i,j}^{k+1}h_j^{k+1})\).
其中,规定\(x=h^0\)。
如果考虑多层的话,模型可以用下式表示:
\(P(x,h^1,\cdots,h^l)=P(h^l)(\coprod_{k=1}^{l-1}P(h^k|h^{k+1})P(x|h^1)\)
然后边缘化\(P(x)\)即可。这个操作只有在小模型里才具有可行性。在sigmod信念网络中,非常简单:\(P(h^l)=\coprod_iP(h_i^l)\)。
深度信念网络和sigmoid信念网络非常相似,只是最上面两层有一个轻微不同的参数化:
\(P(x,h^1,\cdots,h^l)=P(h^{l-1}h^l)(\coprod_{k=1}^{l-1}P(h^k|h^{k+1})P(x|h^1)\)
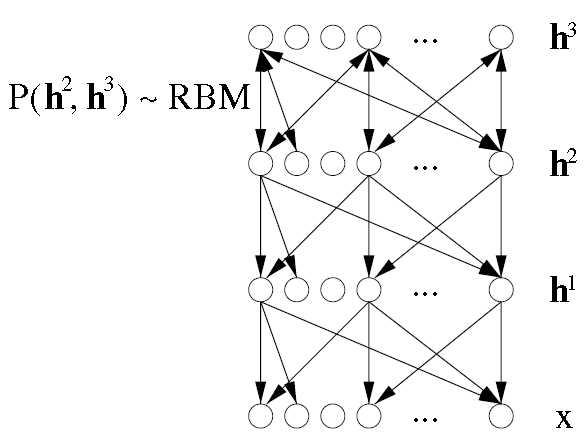
图:多层神经网络。
最上面的联合概率分布是受限玻尔兹曼机(RBM),由于它是无向图,因此画了双箭头。
\(P(h^{l-1},h^l) \propto e^{b'h^{l-1}+c'h^l+h^l'Wh^{l-1}}\)
4.5卷积神经网络
如果不使用无监督的预训练,训练深层的受监督神经网络非常困难。但也有一个例外:卷积神经网络。
4.6自动编码机
5基于能量的模型和玻尔兹曼机
5.1基于能量
5.1.1引入隐藏变量
有时我们需要引入隐藏变量来增加系统表达能力:
\(P(x,h)=\frac{e^{-Energy(x,h)}}{Z}\)由于只有x是可见,我们只关心边缘概率:
\(P(x)=\sum_h\frac{e^{-Energy(x,h)}}{Z}\)
为了和一般能量模型形式对应,我们引入自由能量:
\(P(x)=\frac{e^{-FreeEnergy(x)}}{Z}\)
其中,\(Z=\sum_xe^{-FreeEnergy(x)}\) 并且 \(FreeEnergy(x)=-log\sum_he^{-Energy(x,h)}\)
引入\(\theta\)表示参数模型:
\(logP(x)=-FreeEnergy(x)-log(Z)\)
\( \begin{matrix}\begin{aligned} \frac{\partial logP(x)}{\partial \theta}&=-\frac{\partial FreeEnergy(x)}{\partial \theta}+\frac{1}{Z}\sum_{\tilde{x}}e^{-FreeEnergy(\tilde{x})}\frac{\partial FreeEnergy(\tilde{x})}{\partial \theta}\\&=-\frac{\partial FreeEnergy(x)}{\partial \theta}+\sum_{\tilde{x}}P(\tilde{x})\frac{\partial FreeEnergy(\tilde{x})}{\partial \theta} \end{aligned}\end{matrix} .\)
因此,平均对数似然梯度为:
\(E_{\hat{P}}[\frac{\partial logP(x)}{\partial \theta}]=-E_{\hat{P}}[\frac{\partial FreeEnergy(x)}{\partial \theta}]+E_P[\frac{\partial FreeEnergy(x)}{\partial \theta}]\)
其中,\(\hat{P}\)是训练集的经验分布,\(E_P\)是模型的分布P下的期望。
因此,如果我们能够从P中采样,并且顺利的计算自由能量的话,我们可以利用Monte-Carlo方法去获得一个对数似然梯度的随机估计量。
如果能量能被写成隐藏变量项的和的形式:
\(Energy(x,h)=-\beta(x)+\sum_i \gamma_i (x,h_i),\)
这种形式是满足RBM的,自由能量和似然就能被顺利的求出来(即使里面有指数和的形式):
\( \begin{matrix}\begin{aligned} P(x)&=\frac{1}{Z}e^{-FreeEnergy(x,h)}=\frac{1}{Z}\sum_he^{-Energy(x,h)}\\&=\frac{1}{Z}\sum_{h_1}\sum_{h_2}\cdots\sum_{h_k}e^{\beta(x)-\sum_i \gamma_i (x,h_i)} \\& =\frac{1}{Z}\sum_{h_1}\sum_{h_2}\cdots\sum_{h_k}e^{\beta(x)}\prod_i e^{-\gamma_i(x,h_i)}\\&=\frac{e^{\beta(x)}}{Z}\sum_{h_1}e^{-\gamma_1(x,h_1)} \sum_{h_2}e^{-\gamma_2(x,h_2)} \cdots\sum_{h_k}e^{-\gamma_k(x,h_k)} \\&=\frac{e^{\beta(x)}}{Z}\prod_i \sum_{h_i}e^{-\gamma_k(x,h_i)}\end{aligned}\end{matrix}\)
其中,\(\sum_h_i\)是对\(h_i\)所有可能的取值进行求和。比起对h的所有可能求和的\(\sum_h\),这个求和要容易很多。如果h是连续的话,那所有的求和都可以用积分来替代。在很多情况下,求和或者积分(对一个隐藏单元的取值来说)是容易计算的。
5.1.2条件EBM
5.2玻尔兹曼机
玻尔兹曼机(BM)是一个带隐藏变量的特殊EBM,而受限玻尔兹曼机(RBM)则是一个\(P(h|x)\)和\(P(x|h)\)都可求的玻尔兹曼机。在一个BM中,能量函数是一个二阶多项式:
\(Energy(x,h)=-b'x-c'h-h'Wx-x'Ux-h'Vh\)
由于包含h的二次项,因此上面的计算自由能量的方法在这里是不可行的。然而,为了获得梯度的随机估计量,可以用MCMC(Monte Carlo Markov Chain)取样的方法。对数似然的梯度可以写成下面的形式。
\(\begin{matrix}\begin{aligned}\frac{\partial logP(x)}{\partial \theta}&=\frac{\partial log\sum_he^{-Energy(x,h)}}{\partial \theta}-\frac{\partial log \sum_{\tilde{x},h} e^{-Energy(\tilde{x},h)}} {\partial \theta}\\&=-\frac{1}{\sum_he^{-Energy(x,h)}}\sum_he^{-Energy(x,h)}\frac{\partial Energy(x,h)}{\partial \theta}\\& +\frac{1}{\sum_(tilde{x},h)e^{-Energy(\tilde{x},h)}}\sum_{\tilde{x},h}e^{-Energy(\tilde{x},h)}\frac{\partial Energy(\tilde{x},h)}{\partial \theta} \\&=-\sum_hP(h|x)\frac{\partial Energy(x,h)}{\partial \theta} + \sum_{\tilde{x},h}P(\tilde{x},h)\frac{\partial Energy(\tilde{x},h)}{\partial \theta}\end{aligned}\end{matrix}\)
MCMC采样是基于Gibbs采样的。而N个随机变量\(S=S_1,\cdots,S_N)\)的Gibbs采样通过N个子步骤完成的:
\(S_i\sim P(S_i|S_{-i}=s_{-i})\)
其中\(S_{-i}\)表示除了\(S_i\)之外的所有变量集合。在N个样品全部采集完之后,我们也就完成了链条的一步。在某些条件下,随着步骤的进行,S的分布趋近于P(S)。收敛的一个充分条件是非周期和非回归的。
那么如何在BM上实施Gibbs采样呢,让我们用\(s={x,h}\)来表示所有的BM单元,那么通过把所有的参数放进一个向量d和一个对阵矩阵A中,BM能量函数可以写成下面的形式:
\(Energy(s)=-d's-s'As.\)
让\(d_{-i}\)表示去除元素\(d_i\)的向量d,\(A_{-i}\)表示去除第i行和第i列的矩阵A.\(a_{-i}\)表示去除第i个元素的A的第i行(或者说列)那么我们可以从BM里容易的得到\(P(s_i|s_{-i})\).例如,如果\(s_i \in \{0,1\}\)并且A的对角线为空:
\(Energy(s)=-d_is_i-d_{-i}'s_{-i}'-(s_{-i}A_{-i}+s_ia_i)s_{-i} \\=-d_is_i-d_{-i}'s_{-i}'-(s_{-i}'A_{-irow}+s_iA_{irow})s \\=-d_is_i-d_{-i}'s_{-i}'-s_{-i}'A_{-i}s_{-i}-s_{-i}'a_{-i}s_i-s_ia_{-i}s_{-i}-s_ia_is_i\\=-d_is_i-d_{-i}'s_{-i}'-s_{-i}'A_{-i}s_{-i}-2s_{-i}'a_{-i}s_i\)
\(\begin{matrix}\begin{aligned} P(s_i=1|s_{-i})=sigm(d_i+2a_{-i}'s_{-i})\)
例如,
5.3受限玻尔兹曼机
受限玻尔兹曼机同层之间是没有连接的,因此:
/(Energy(x,h)=-b'x-c'h-h'Wx\)
在二元化的情况下有\(P(h_i=1|x)=sigm(c_i+W_ix)\)和\(P(x_i=1|h)=sigm(b_i+W_j'h)\)
5.3.1Gibbs采样
采样是指我们知道一个样本x(大多数情况下是多维的)的概率分布函数,要通过这个函数来产生多个样本点集合。
Gibss采用是需要知道样本中一个属性在其它所有属性下的条件概率,然后利用这个条件概率来分布产生各个属性的样本值。其过程如下所示:
Gibbs采样,可用下式表示:
\(x_1\sim\hat{P}(x)-->h_1\sim\P(h|x_1)-->x_2\sim\P(x|h_1)-->h_2\sim\P(h|x_2)-->...-->x_{k+1}\sim{x|h_k}\)
5.4对比分歧(contrastive divergence,CD)
CD是对数似然梯度的近似,证实对训练RBM是有效的。
5.4.1证明
为了获得算法,我们需要用一个样本来近似所有可能输入的平均值。














 923
923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









