







索引类型
正排索引
一个简单版的B+树索引大概是:叶子节点存放完整的数据,非叶子节点存放建立对应聚簇索引对应的字段(主键),一条可以使用聚簇索引的SQL,会依次从上往下进行B+树的查找。
create table user_info(
id int,
name varchar(16),
hobby varchar(256)
);
索引查询
对应非聚簇索引只是叶子节点的内容存放的是该表的主键信息,查询的顺序则是先通过非聚簇索引的字段找到叶子节点中一致的单个或者多个主键id,再使用这些主键id进行回表,最终获得对应的完整实体数据。
全表扫描
如果根据用户爱好查询,对应用户列表,只能写like的sql,全表扫描逻辑
select * from user_info where hobby like '%足球%';
# 即使对hobby字段加了普通索引,使用innodb引擎,在查询中使用字符串中的索引也只能走最左前缀索引,即 like '足球%'倒排索引
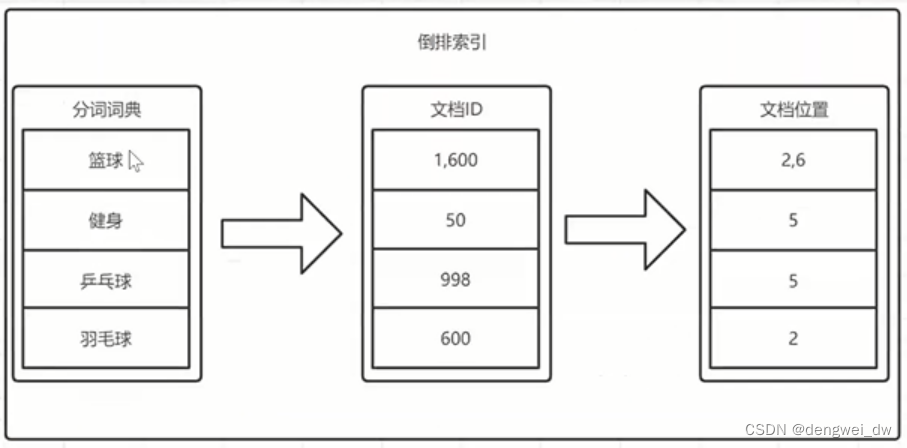

1. 使用“手机”作为关键字查询
生成的倒排索引中,词条会排序,形成一颗树形结构,提升词条的查询速度
2. 使用“华为手机”作为关键字查询
华为:1,3
手机:1,2,3
逻辑概念
索引(index)
ElasticSearch存储数据的地方,可以理解成关系型数据库中的数据库概念。
映射(mapping)
mapping定义了每个字段的类型、字段所使用的分词器等。相当于关系型数据库中的表结构。
文档(document)
Elasticsearch中的最小数据单元,常以json格式显示。一个document相当于关系型数据库中的一行数
据。
倒排索引
一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,对应一个包含它的文档id列表。
类型(type)
一种type就像一类表。如用户表、角色表等。在Elasticsearch7.X默认type为_doc
\- ES 5.x中一个index可以有多种type。
\- ES 6.x中一个index只能有一种type。
\- ES 7.x以后,将逐步移除type这个概念,现在的操作已经不再使用,默认_doc
物理概念
•集群(cluster):一组拥有共同的 cluster name 的 节点。
•节点(node) :集群中的一个 Elasticearch 实例

•索引(index) :es存储数据的地方。相当于关系数据库中的database概念
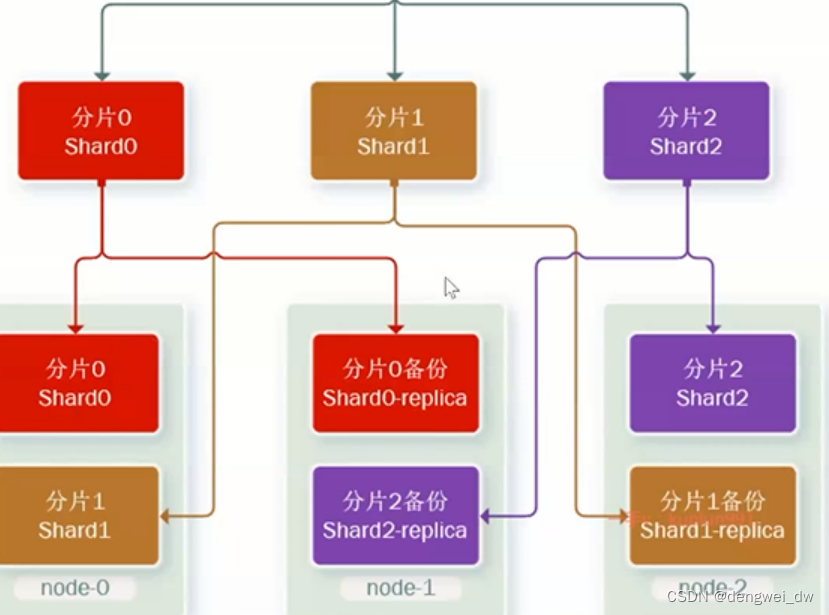
•分片(shard):索引可以被拆分为不同的部分进行存储,称为分片。在集群环境下,一个索引的不同

分片可以拆分到不同的节点中
•主分片(Primary shard):相对于副本分片的定义。
•副本分片(Replica shard)每个主分片可以有一个或者多个副本,数据和主分片一样。
集群角色
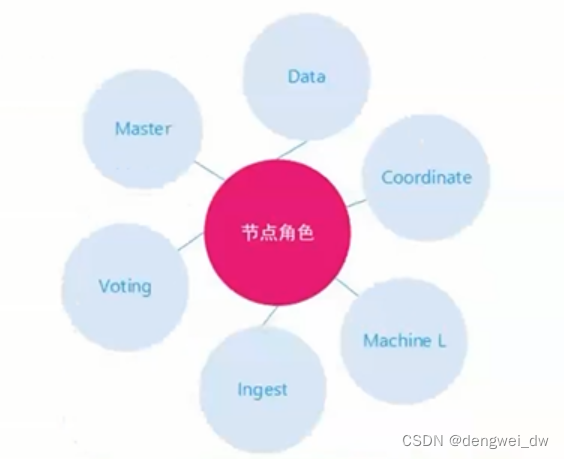
一个es实例代表了一个es节点,如果不通过node.roles设置节点的角色,一个es节点默认的节点角色有很多不同的角色。每个节点既可以是候选主节点,也可以是数据节点,可以通过elasticsearch.yml进行设置,默认为true。ES节点有以下角色:
master节点
master节点准确说是具有成为master节点资格的节点,即master-eligible node。
主要职责:master主要负责集群层面的相关操作,管理集群变更,如创建或删除索引,跟踪哪些节点是集群的一部分,并决定哪些分片分配给相关的节点。
一个稳定的主节点对集群很重要,候选主节点可以通过节点选举过程被选举为主节点,主节点最好是专用的,不和其他角色共用,以免其他操作对master节点的负载造成影响,导致集群不可用。主节点负责轻量级集群范围的操作,任何不是仅投票节点的合格节点都可以选举成为主节点。
主节点必须有个path.data目录,其内容在重启后依然存在,就像数据节点一样,这是存储集群元数据的地方,集群元数据描述了如何读取存储在数据节点上的数据,因此如果丢失,则无法读取存储在数据节点上的数据。
仅投票节点
只能参与主节点的投票选举环节,自己不能被选举为master节点。
主要职责:用来凑数。如果只部署了2个候选主节点,当一个节点挂掉后集群将会不可用,加入了仅协调节点则不一样,有了仅投票节点可以帮助快速选择一个主节点出来,并且仅投票节点不会选为主节点。它的资源消耗很小。
一个HA(高可用)集群至少三个符合主节点的节点,至少2个不是仅投票节点,即使集群故障也能选举出主节点。
数据节点
负责数据的存储和相关的操作,对数据进行增删改查和聚合等操作。
数据节点对CPU,内存,IO要求较高,在优化的时候需要监控数据节点的状态,当资源不够的时候,需要在集群中添加新的节点。
数据节点保存包含已编入索引的文档分配,CRUD、搜索、聚合这些操作是IO密集型,内存密集型,CPU密集型,监控这些资源对数据节点非常重要。
预处理节点
这是从5.0版本开始引入的概念,预处理节点可以执行由一个或多个摄取处理器组成的预处理管道
主要职责:预处理操作运行在索引文档之前,即写入数据之前,通过事先定义好的一系列processors(处理器)和pipeline(管道),对数据进行某种转换、富化
角色介绍:能执行预处理管道,有自己独立的任务要执行,在索引数据之前可以先对数据做预处理操作,不负责数据存储也不负责集群相关的事务,类似于logstash 中 fiter 的作用,功能相当强大。
在实际文档索引发生之前,使用Ingest节点预处理文档,Ingest节点拦截批量和索引请求,它应用转换,然后将文档传递回索引,在数据被索引之前,通过预定义好的处理管道对数据进行预处理。
仅协调节点
如果您取消了候选主节点的职责、保存数据和预处理文档的能力,那么您就剩下一个只能路由请求、处理搜索减少阶段和分发批量索引的协调节点
主要职责:协调节点将请求转发给保存数据的数据节点,每个数据节点在本地执行请求,并将结果返回给协调节点。
协调节点收集完数据合,将每个数据节点的结果合并为单个全局结果,对结果收集和排序的过程可能需要很多CPU和内存资源。
角色介绍:本质上,仅协调节点的行为就像智能负载均衡器,通过从数据和符合主节点的节点卸载协调节点角色,仅协调节点可以使大型集群受益,他们加入集群并接收完整的集群状态,就像其他每个节点一样,他们使用集群状态将请求直接路由到适当的地方。
节点配置方式:
以下是一个节点的配置方式

整个集群搭建及详解在后续章节进行更新














 1113
1113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









