







针对于https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=,进行爬虫操作。
1. 使用urlopen函数
from urllib import request
url = 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput='
resp = request.urlopen(url)
print(resp.read())
运行之后,在输出的时候,输出的页面源码信息很少。
原因:使用urlopen,网页会识别出该操作是一个python的爬虫操作。那么由于拉勾网做了反爬虫机制,所以返回的信息并不是网页真实的信息。
2. 使用request.Request类
from urllib import request
url = 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
}
req = request.Request(url, headers=headers)
resp = request.urlopen(req)
print(resp.read())
与urlopen函数不同的是,request.Request是一个类。它有如下的一些参数:
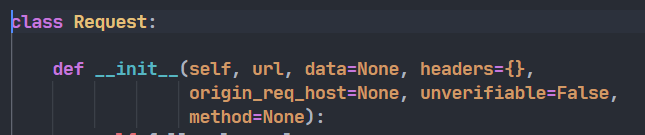
我们可以通过设置headers(请求头)参数,来伪装我们的爬虫操作,从而可以避开反爬虫机制,爬取到我们想要的信息。headers中通常会有:User-Agent和Referer两个属性。
3. 获取职位信息
在上述URL中,虽然在页面中可以看到一些职位信息:

但实际上,该URL的源代码并没有这些信息。因为这些职位信息是另一个URL的,而这两个URL通过.js文件被放到了一起。真正的职位信息实际上在https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false里面。
from urllib import request, parse
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
referer = 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput='
# 请求头的信息足够多时,可以成功爬取信息
headers = {
'User-Agent': user_agent,
'Referer': referer
}
# data数据需要通过urlencode,才能传入Request
data = {
'first': 'true',
'pn': '1',
'kd': 'python'
}
# urlencode可以将data字典变为字符串,同时对其中特殊字符进行编码
# 在python3中,字符串是unicode编码,而Request中的data必须为bytes类型,所以利用encode('utf-8')将unicode编码为bytes
req = request.Request(url, headers=headers, data=parse.urlencode(data).encode('utf-8'), method='POST')
resp = request.urlopen(req)
print(resp.read().decode())
这个代码依然不能成功获取页面信息,会有{"status":false,"msg":"您操作太频繁,请稍后再访问","clientIp":"117.151.83.211","state":2402}的信息输出。可能是请求头的信息不够多吧,目前不太懂。。。
4. 小结
在做爬虫的时候,要经常对网页进行“检查”。具体做法是:在网页空白处邮件–>检查–>Network。这里面会将该页面的所有信息的文件全部罗列出来。同时也会列出获取这些文件时对应的请求报文和响应报文。

而在上述写代码的过程中,需要对以下一些信息进行查看:
General中的Request URLRequest Headers中的user-agent和refererForm Data中的所有信息















 1156
1156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









