







Redis5个常用对象
来源于小林coding (xiaolincoding.com)
文章目录
redis对象(一) String
1.什么是String
String就是字符串,是Redis中的一种基本类型,最大为512MB(可以通过proto-max-bulk-len来修改它,一般不修改)。
2.适用场景
一般用来存字节数据、文本数据、序列化后的数据。
- 缓存场景
Value存Json字符串等信息。
- 计数场景
由于Redis是单线程处理命令的,执行命令过程是原子的。因此String数据类型适合计数场景,比如计算访问次数、抖音的点赞、转发量等等。
3.常用操作
创建、查询、更新、删除
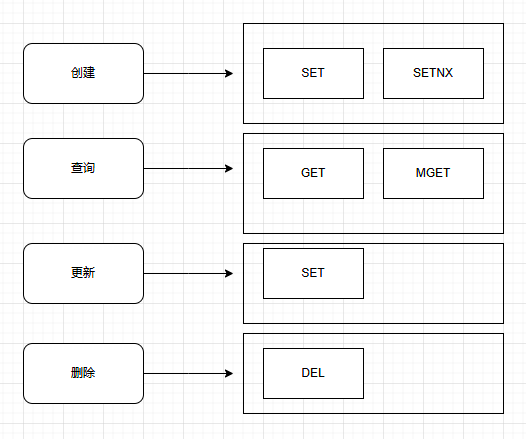
3.1 创建
3.1.1 SET
格式:SET key value
功能:设置一个key的值为value,成功就返回OK
演示:
> SET STRTEST cat
"OK"
扩展参数:
- EX + seconds:设置键的过期时间为多少秒。
- PX + milliseconds:设置键的过期时间为多少毫秒。
> SET str dog EX 10
"OK"
> ttl str
(integer) 8
> ttl str
(integer) 4
> ttl str
(integer) 3
> ttl str
(integer) 1
> ttl str
(integer) -2
- NX :只在键不存在时,才对键进行设置操作。如:
SET key value NX效果等于SETNX key value。 - XX :只在键已经存在时,才对键进行设置操作。
> SET STRTEST fish NX
(nil)
> SET STRTEST fish
"OK"
3.1.2 SETNX
格式:SETNX key value
功能:指定不存在时,为key设置指定的value,成功返回1,失败返回0
> SETNX str dog
(integer) 1
> SETNX str dog
(integer) 0
3.2 查询
3.2.1 GET
格式:GET key
功能:查询某个key,存在返回对应value,不存在返回nil
> SET str cat
"OK"
> SET STRTEST fish
"OK"
> GET str
"cat"
> GET STRTEST
"fish"
3.2.2 MGET
格式:MGET [key ...]
功能:查询多个key,存在返回对应value,不存在返回nil
> MGET str STRTEST abc efg
1) "null"
2) "fish"
3) "null"
4) "null"
3.3 更新
格式:SET key value
功能:对某个key的value进行更新
> SET str cat
"OK"
> GET str
"cat"
> SET str fish
"OK"
> GET str
"fish"
3.4 删除
格式:DEL key
功能:删除某个key,成功返回1,失败返回0
> DEL str
(integer) 1
> DEL str
(integer) 0
4.底层实现
4.1 三种编码方式
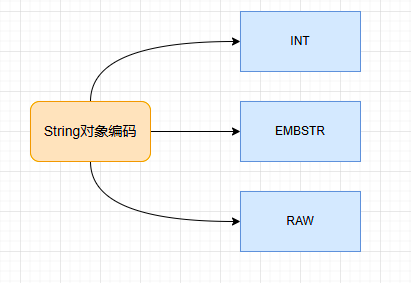
INT编码:存储一个整型,能够用long表示的整数以这种编码存储。
EMBSTR编码:如果字符串小于等于阈值(44)字节,使用EMBSTR编码。
RAW编码:字符串大于阈值字节,使用RAW编码。
其中,EMBSTR编码和RAW编码都由redisObject和SDS两个结构组成。它们的差别在于EMBSTR下,redisObject和SDS是连续的;RAW编码下redisObject和SDS是分开的。
EMBSTR:

RAW:
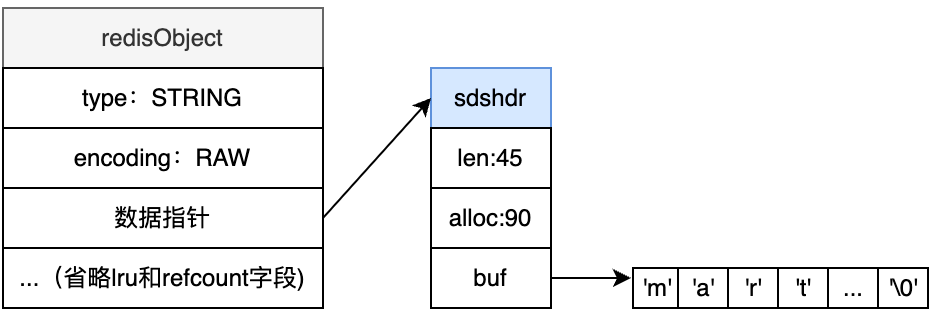
EMBSTR的优点:redisObject和SDS两个结构可以一次分配空间;缺点:如果重新分配内存,整体都需要重新分配。
所以EMBSTR设计为只读,任何写操作之后,EMBSTR结构都会变为RAW结构。原因是任何发生过修改的字符串通常被认为是易变的。
这种结构间的变化通常为:
INT -> RAW:当存储的内容不再是整数,或者大小超过了long时;
EMBSTR -> RAW:任何写操作之后,EMBSTR都会变为RAW
redis对象(二) List
1.List是什么
Redis List是一组连接起来的字符串集合。
1.1 限制
List最大元素个数是2^32 - 1(4,294,967,295),新版本已经是2^64 - 1了。
2.适用场景
List作为一个列表存储,属于比较底层的数据结构,可以使用的场景很多,比如存储一批任务数据,存储一批消息等等。
3.常用操作
常用操作还是创建、查询、更新、删除
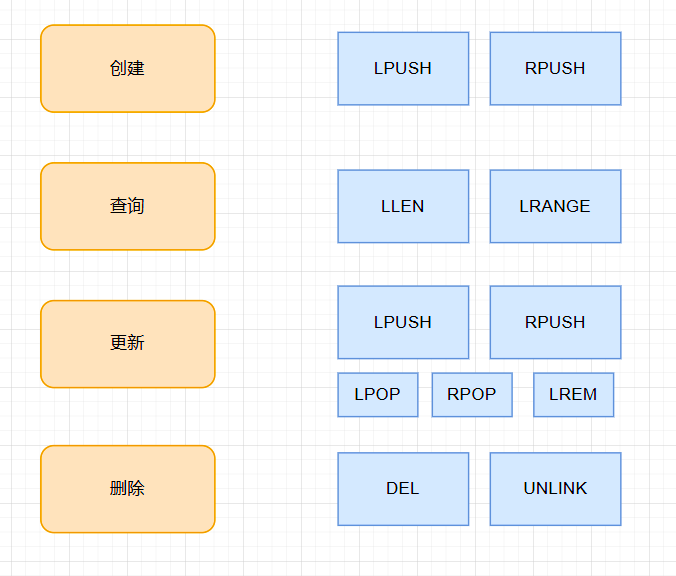
3.1 写操作
3.1.1 LPUSH
格式:LPUSH key value [value …]
功能:从头部添加元素,返回值为List中的元素总数。
> LPUSH list1 s1 s2 s3
(integer) 3
> LPUSH list1 s4
(integer) 4
s4是第二个命令插入的,所以它在头部,此时List结构如下:

3.1.2 RPUSH
格式:RPUSH key value [value …]
功能:从尾部添加元素,返回值为List中的元素总数。
> RPUSH list1 s5
(integer) 5
s5是第RPUSH命令插入的,所以它在尾部,此时List结构如下

3.1.3 LPOP
格式:LPOP key
功能:移除并获取列表的第一个元素。
> LPOP list1
"s4"
s4被移除,此时List结构如下

3.1.4 RPOP
格式:RPOP key
功能:移除并获取列表的最后一个元素。
> RPOP list1
"s5"
s5被移除,此时List结构如下

3.1.5 LREM
格式:LREMkey count value
功能:移除值等于value的元素。当count=0,则移除所有值等于value的元素。当count > 0,则从左到右开始移除count个。当count < 0,则从右向左移除count个。返回值为被移除元素的数量。
> LREM list1 0 s2
(integer) 1
3.1.5 DEL
格式:DEL key [key …]
功能:删除对象,返回值为删除成功了几个键。
> DEL list1
(integer) 1
3.1.6 UNLINK
格式:UNLINK key [key …]
功能:删除对象,返回值为删除成功了几个键。
和DEL有以下不同:
DEL命令删除时,会阻塞客户端,直到删除完成。UNLINK命令是异步删除命令,只取消key在键空间的关联,让其不能再查到,删除是异步进行,所以不会阻塞客户端。
> LPUSH list s1 s2 s3 s4
(integer) 4
> UNLINK list
(integer) 1
3.2 读操作
先构造一个列表:
> LPUSH list s1 s2 s3
(integer) 3

3.2.1 LLEN
格式:LLEN key
功能:查看List的长度,即List中的元素总数。
> LLEN list
(integer) 3
3.2.2 LRANGE
格式:LRANGE key start stop
功能:查看start到stop为角标的元素。
> LRANGE list 0 1
1) "s3"
2) "s2"
4.底层实现
4.1 编码方式
3.2版本之前,List对象有两种编码模式,一种是ZIPLIST,另一种是LINKEDLIST。
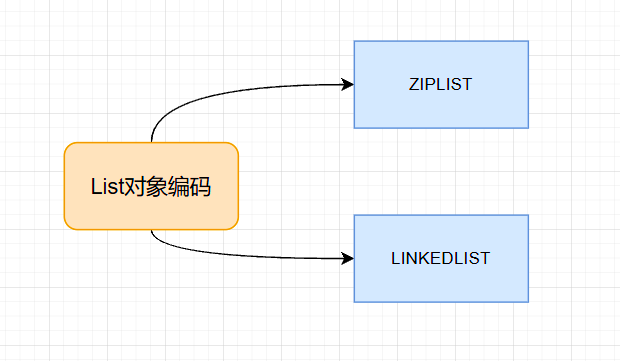
当满足如下条件时,使用ZIPLIST编码:
1.列表对象保存的所有字符串对象长度小于64字节;
2.列表对象元素个数少于512个,注意,这是LIST的限制,并不是ZIPLIST的限制;
ZIPLIST底层由压缩列表实现,ZIPLIST内存排列很紧凑,可以有效节约空间。
不满足ZIPLIST编码条件,就使用LINKEDLIST编码条件,还是用之前的例子:
数据以链表形式连接起来,删除更灵活,但是内存不如ZIPLIST紧凑,所以只有在列表个数或节点数据长度比较大时,才会使用LINKEDLIST编码,以加快处理性能,牺牲了内存。
redis对象(三) Set
1.Set是什么
Redis的Set是一个不重复、无序的字符串集合,这里额外说明一下,如果是INTSET编码的时候其实是有排序的,一般不应该依赖这个,整体还是看出无序来比较好。
2.适用场景
适用于无序集合场景,比如某个用户关注了哪些公众号,这些信息就可以放进一个集合,Set还提供了查交集、并集的功能,可以很方便地实现共同关心的能力。
3.常用操作
常用操作还是创建、查询、更新、删除。
3.1 写操作
3.1.1 SADD
格式:SADD key member [member …]
功能:添加元素,返回值为成功添加了几个元素。
> SADD set1 aa bb cc
(integer) 3
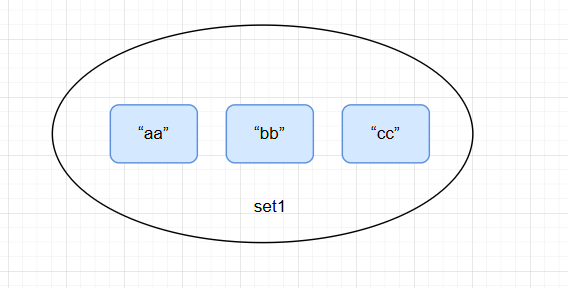
为set1添加元素:
> SADD set1 11 22 33
(integer) 3
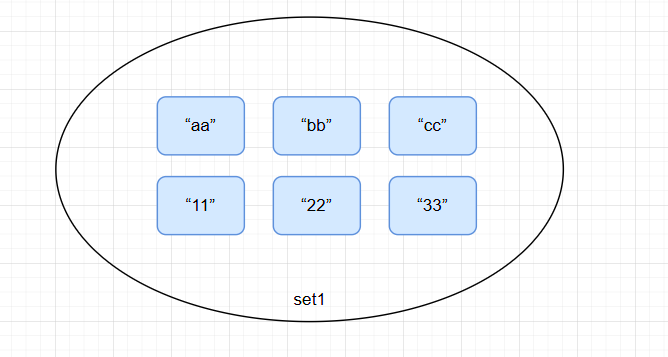
3.1.2 SREM
格式:SREM key member [member …]
功能:删除元素,返回值为成功删除了几个元素。
> SREM set1 33
(integer) 1
3.2 读操作
以set1、set2进行演示
3.2.1 SISMEMBER
格式:SISMEMBER key member
功能:查询元素是否存在。
> SISMEMBER set1 bb
(integer) 1
> SISMEMBER set1 ff
(integer) 0
3.2.2 SCARD
格式:SCARD key
功能:查询元素是否存在。
> SCARD set1
(integer) 6
3.2.3 SMEMBERS
格式:SMEMBERSkey
功能:查询集合的所有元素。
> SMEMBERS set1
1) "aa"
2) "bb"
3) "22"
4) "33"
5) "cc"
6) "11"
3.2.4 SSCAN
语法:SSCAN key cursor [MATCH pattern] [COUNT count]
功能:查看集合元素,可以理解为指定游标进行查询,可以指定个数,默认为10。
例1:从0号位置开始查询,默认10个
> SSCAN set1 0
1) "0"
2) 1) "22"
2) "aa"
3) "bb"
4) "cc"
5) "11"
6) "33"
例2:使用MATCH模糊查询
> SSCAN set1 0 MATCH 1*
1) "0"
2) 1) "11"
> SSCAN set1 0 MATCH a*
1) "0"
2) 1) "aa"
3.2.5 SINTER
语法:SINTER key [key …]
功能:返回在第一个集合里,同时在后面所有集合都存在的元素。求交集
> SINTER set1 set2
1) "11"
3.2.6 SUNION
语法:SUNION key [key …]
功能:返回所有集合的并集,集合个数大于等于2。
> SUNION set1 set2
1) "aa"
2) "bb"
3) "gg"
4) "22"
5) "33"
6) "ff"
7) "11"
8) "cc"
3.2.7 SDIFF
语法:SDIFF key [key …]
功能:返回在第一个集合里,且在后续集合中不存在的元素,集合个数大于等于2,注意,是以第一个集合和后面比,看第一个集合多了哪些元素。
> SDIFF set1 set2
1) "22"
2) "33"
3) "bb"
4) "aa"
5) "cc"
4.底层实现
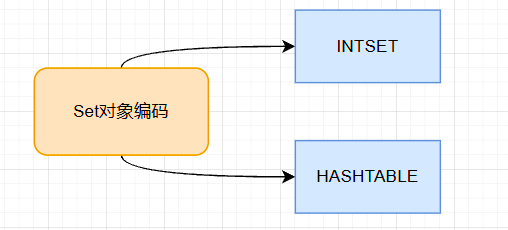
Redis出于性能和内存的综合考虑,也支持两种编码方式,如果集合元素都是整数,且元素个数不超过512个,就可以用INTSET编码,结构如下,可以看到INTSET排列比较紧凑,内存占用少,但是查询时间需要二分查找。
如果不满足INTSET的条件,就需要用HASHTABLE,HASHTABLE结构如下图,可以看到HASHTABLE查询一个元素的1性能很高,能O(1)时间就能找到一个元素是否存在。
总结
Set可以很方便的管理无序集合,还可以为多个集合求交集并集,底层编码模式有INTSET和HASHTABLE两种,INTSET对应少量整数集合下节约内存,HASHTABLE适用于需要快速定位某个元素的场景。
redis对象(四) Hash
1.Hash是什么?
Redis Hash是一个field、value都为string的hash表,存储在Redis的内存中。
Redis中每个hash可以存储2^32 - 1键值对 (40多亿)。
2.适用场景
适用于O(1)时间字典查找某个field对应数据的场景,比如任务信息的配置,就可以以任务类型为field,任务配置参数为value。
3.常用操作
创建、查询、更新、删除
3.1 写操作
3.1.1 HSET
格式:HSET key field value
功能:为集合对应field设置value数据。
> HSET hash1 f1 v1 f2 v2 f3 v3
(integer) 3
3.1.2 HSETNX
格式:HSET key field value
功能:如果field不存在,为集合对应field设置value数据。
> HSETNX hash1 f1 v4
(integer) 0
> HSETNX hash1 f4 v4
(integer) 1
由于f1已经存在,所以不会再设置f1。
3.1.3 HDEL
格式:HDEL key field [field …]
功能:删除指定field,可以一次删除多个。
> HDEL hash1 f1
(integer) 1
3.1.4 DEL
格式:DEL key field [field …]
功能:删除哈希对象。
> DEL hash1
(integer) 1
3.2 读操作
3.2.1 HGETALL
格式:HGETALL key
功能:查找全部数据。
> HSET hash1 f1 v1 f2 v2 f3 v3
(integer) 3
> HGETALL hash1
1) "f1"
2) "v1"
3) "f2"
4) "v2"
5) "f3"
6) "v3"
3.2.2 HGET
格式:HGETALL key field
功能:查找field对应的value。
> HGET hash1 f1
"v1"
3.2.3 HLEN
格式:HLEN key
功能:查找Hash中元素总数。
> HLEN hash1
(integer) 3
3.2.4 HSCAN
格式:HSCAN key cursor [MATCH pattern] [COUNT count]
功能:从指定位置查询一定数量的数据,这里要注意,如果是小数据量下,处于ZIPLIST时,COUNT不管填多少,都是返回全部,因为ZIPLIST本身就是用于小集合,没必要说再切分成几段来返回。
> HSCAN hash1 0 count 100
1) "0"
2) 1) "f1"
2) "v1"
3) "f2"
4) "v2"
5) "f3"
6) "v3"
使用MATCH匹配:
> HSCAN hash1 0 MATCH *2
1) "0"
2) 1) "f2"
2) "v2"
4.底层原理
编码格式
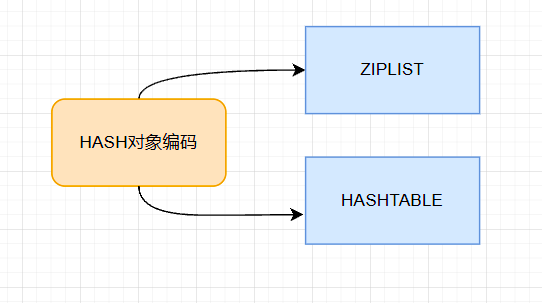
1.Hash对象保存的所有值和键的长度都小于64字节;
2.Hash对象元素个数少于512个。
两个条件任何一条不满足,编码结构就用HASHTABLE。
总结
Hash就是字典,可以存储多个field-value的映射关系,比如学生分数、任务配置等。Hash的底层编码有ZIPLIST和HASHTABLE两种。
redis对象(五) ZSet
1.ZSet是什么?
ZSet就是有序集合,也叫Sorted Set,是一组按关联积分有序的字符串集合,这里的分数是个抽象概念,任何指标都可以抽象为分数,来满足不同的场景。
积分相同的情况下,按字典序排序。
2.适用场景
用于需要排序集合的场景,比如游戏排行榜。
3.常用操作
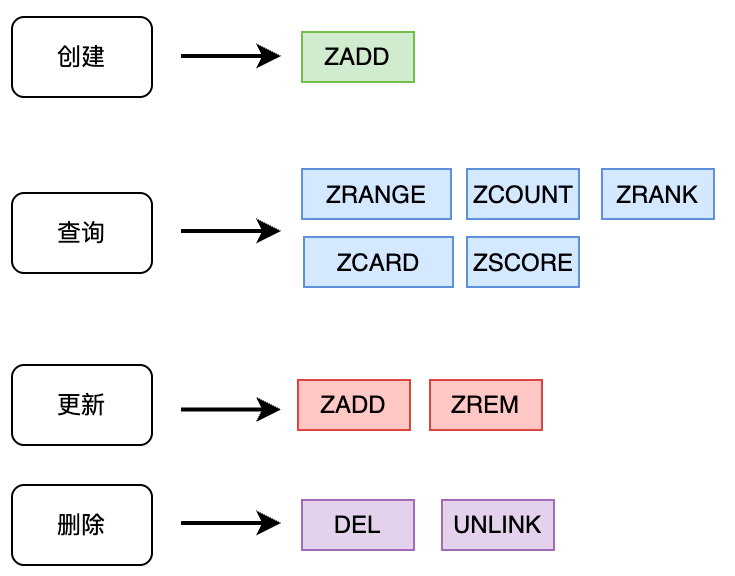
3.1写操作
3.1.1 ZADD
格式:ZADD key score member [score member …]
功能:向Sorted Set增加数据,如果是已经存在的Key,则更新对应的数据
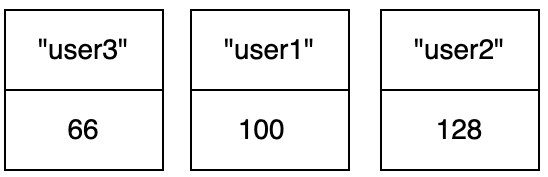
> ZADD zset1 100 user1 128 user2 66 user3
(integer) 3
扩展参数:
XX:仅更新存在的成员,不添加新成员。
NX:不更新存在的成员,只添加新成员。
LT:更新新的分值比当前分值小的成员,不存在则新增。
GT:更新新的分值比当前分值大的成员,不存在则新增。
此时集合中的有序数据如下:
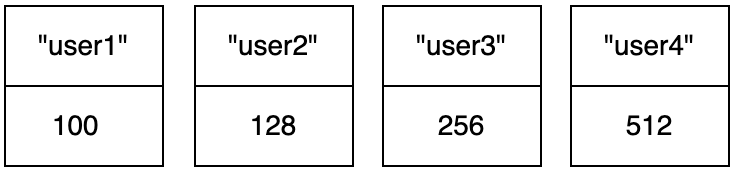
ZADD操作已存的member就是更新。这里返回值是1,表示新增只有一个user4,更新的user3不计入返回值,但是数据是成功更新的。
> ZADD zset1 256 user3 512 user4
(integer) 1
此时集合中的有序数据如下:
3.1.2 ZREM
格式: ZREM key score member [score member …]
功能:删除ZSet中的元素。
> ZREM zset1 user4
(integer) 1
此时集合中的有序数据如下:
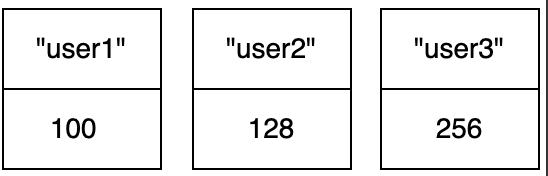
3.2读操作
3.2.1 ZCARD
格式:ZCARD key
功能:查看ZSet中成员总数
> ZCARD zset1
(integer) 3
3.2.2 ZRANGE
格式:ZRANGE key start stop [WITHSCORES]
功能:查询从start到stop范围的ZSet数据,WITHSCORES选填,不填只输出key,没有score值
> ZRANGE zset1 0 -1 WITHSCORES
1) "user1"
2) "100"
3) "user2"
4) "128"
5) "user3"
6) "256"
3.2.3 ZCOUNT
格式:ZCOUNT key min max
功能:计算min-max积分范围的成员个数
> ZCOUNT zset1 50 200
(integer) 2
3.2.4 ZRANK
格式:ZRANK key member
功能:查看ZSet中member的排名索引,索引从0开始,所以排第一,所以就是0
> ZRANK zset1 user2
(integer) 1
> ZRANK zset1 user3
(integer) 2
> ZRANK zset1 user1
(integer) 0
3.2.5 ZSCORE
格式:ZSCORE key member
功能:查看ZSet中member的分数
> ZSCORE zset1 user3
"256"
4.底层实现
4.1 底层编码
ZSet底层编码有两种,一种是ZIPLIST,一种是SKIPLIST+HASHTABLE。
和之前一样,ZSet中的ZIPLIST也是用于数据量比较小的内存节省,结构如下:

如果满足以下条件,则使用ZIPLIST编码:
1.列表对象保存的所有字符串对象长度都小于64字节;
2.列表对象元素个数少于128。
两个条件任何一条不满足,编码结构就使用SKIPLIST+HASHTABLE,其中SKIPLIST也是底层数据结构。
SKIPLIST也就是之前说过的跳表。
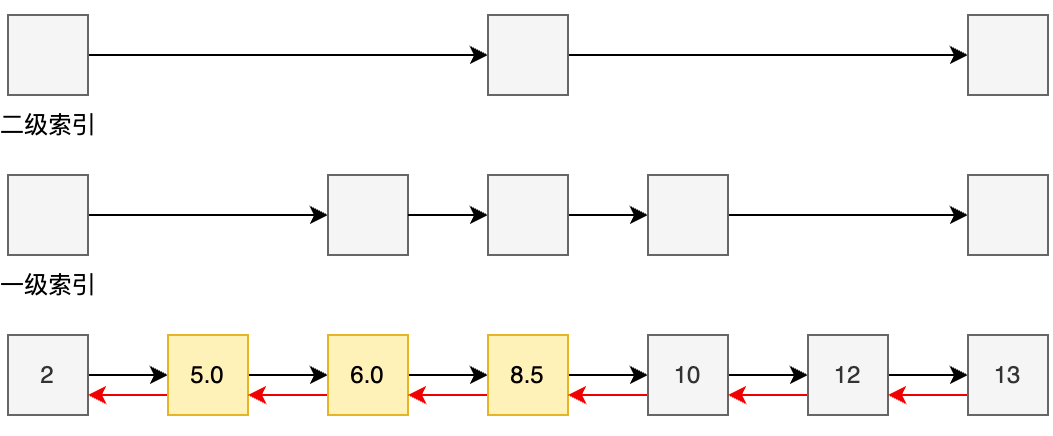
除了SKIPLIST,Redis还使用了HASHTABLE来配合查询,这样可以在O(1)时间复杂度查到成员的分数值。
总结
ZSet就是有序集合,用于保存、查询处理有序的集合,其查询范围、成员分值查询速度都很快。ZSet非常适用于排名场景,比如游戏排行榜。
ZSet底层有两种编码方式,一种是数据量较少的ZIPLIST,另一种是查询性能更优的SKIPLIST+HASHTABLE的编码模式。















 2446
2446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









