







什么是一致性 Hash 算法?
哈希算法大家都不陌生,经常被用在负载均衡、分库分表等场景中,比如说我们在做分库分表的时候,最开始我们根据业务预估,把数据库分成了 128 张表,这时候要插入或者查询一条记录的时候,我们就会先把分表键,如 buyer_id 进行 hash 运算,然后再对 128 取模,得到 0-127 之间的数字,这样就可以唯一定位到一个分表。
但是随着业务得突飞猛进,128 张表,已经不够用了,这时候就需要重新分表,比如增加一张新的表。这时候如果采用 hash 或者取模的方式,就会导致 128+1 张表的数据都需要重新分配,成本巨高。
一致性哈希 (Consistent Hashing)是一种用于分布式系统中数据分片和负载均衡的算法。它的目标是在节点的动态增加或删除时,尽可能地减少数据迁移和重新分布的成本。
1、如何实现?
首先我们需要一个 2^32 大小的环(虚拟)。
然后我们将我们需要的分表映射到上面。

之后我们在插入数据的时候使用 hash 算法计算值之后取模取模 2^32 。最后得出的值对应在环的位置,该位置是哪一张表就插入到哪一张表中。
2、有什么好处
可以解决两个问题:
2.1、分表之后扩容
当我们在业务初期没有预估到有大量的数据量,初期的分表数量已经不够了怎么办?
此时如果我们使用的是一般的 Hash 取模算法,那么就需要把所有的数据都进行一边 Hash 取模,消耗极大。
一致性 Hash 算法就能很好的解决这个问题。
如下:
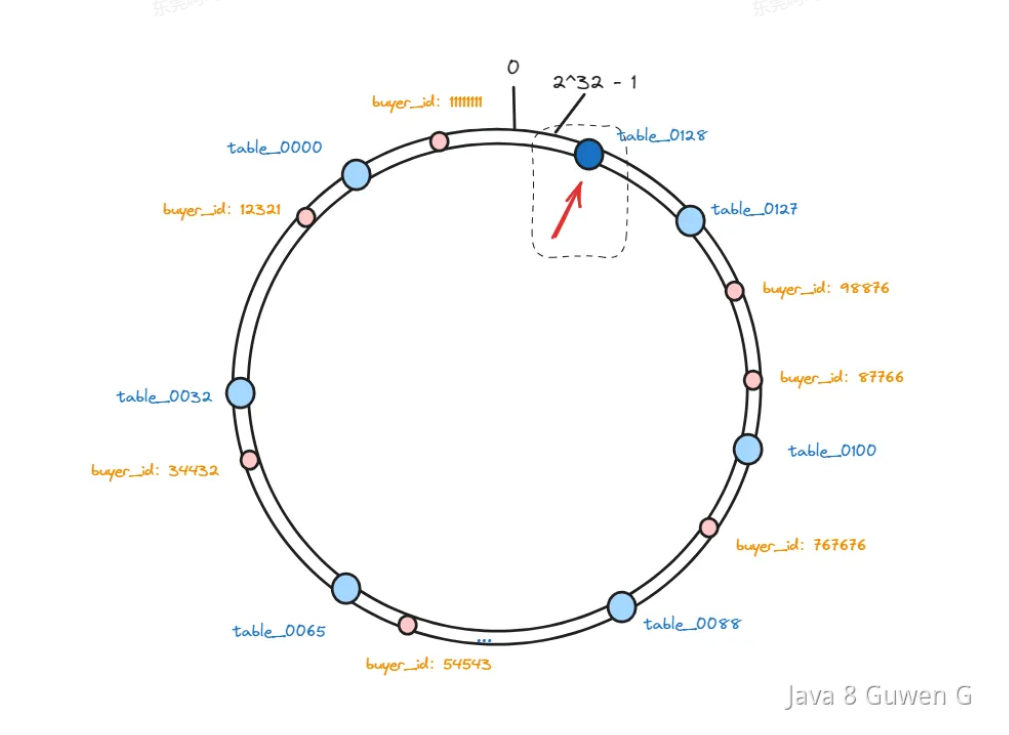
加入我们有 0-127 这 128 张表,我们想再添加一张表怎么办?
我们直接在 hash 环上的 table_0000 和 table_0127 之间添加一个新的节点 table_0128 然后将这两个表中的数据重新计算 hash 值之后映射到三个新的表中即可。
2.2、数据倾斜
我们在分表中不可避免遇到的问题就是数据倾斜。
数据倾斜是指在分布式计算或数据库环境中,数据分布不均匀的现象。在理想的分布式系统中,数据和计算负载应该均匀分布在所有节点上。然而,由于各种原因,某些节点可能承载比其他节点更多的数据或计算负载,这就是数据倾斜。
也就是说某个表中由于分片算法的原因导致存储了大量的数据。
这样会给整个系统造成很大的性能瓶颈。
此时,我们能做的就是进行二次分表,我们的一致性 Hash 算法就可以很好的解决这个问题。
也就是上述解决扩容的解决方法,在数据量大的表的位置添加一个新的表,然后重新计算 hash 值映射即可。
其次,我们也可以在不新增表的情况下处理数据倾斜,如图:
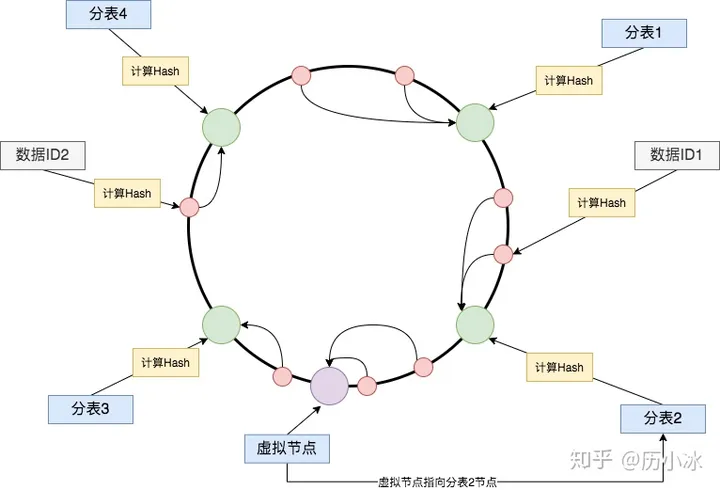
原本分表 2 和分表 3 之间的数据都是存储在分表 3 中的,此时我们可以在 2 和 3 之间新增一个虚拟的节点, 该虚拟节点可以指向任意一个节点,然后把该虚拟节点中的数据都存储在指向的新节点中也就是其他的分表中。
这样可以有效的解决数据倾斜问题。
















 8024
8024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











