







各位同学好,今天和大家分享一下python机器学习中的决策树算法,在上一节中我介绍了决策树算法的基本原理,这一节,我将通过实例应用带大家进一步认识这个算法。文末有完整代码和数据集,需要的自取。那我们开始吧
【机器学习】(4) 决策树算法理论:算法原理、信息熵、信息增益、预剪枝、后剪枝、算法选择
1. Sklearn实现决策树
首先我来介绍一下sklearn库中的决策树分类器 sklearn.tree.DecisionTreeClassifier
导入方法: from sklearn.tree import DecisionTreeClassifier
决策树分类器 DecisionTreeClassifier() 有如下参数在操作时需要注意:
criterion: gini(基尼系数) 或者 entropy(信息熵) 方法。
spliter: best 或 random。best是在所有特征中找到最好的切分点,random是随即找一些特征来进行切分(数据量大时用random)。
max_depth: 树的最大深度。当特征或者数量比较小的时候可以不用管这个值,特征比较多的时候可以限制一下。
min_sample_split: 决策树中某个叶子节点的样本最小个数,如果数据量不大,不需要管这个值,如果样本量比较大,推荐增大这个值。
min_weight_fraction_leaf: 叶子节点所有样本权重和最小值,如果小于这个值,则会和兄弟节点一起被剪枝,默认为0,也就是不考虑权重的问题。 一般来说,如果我们有较多的样本有缺失值,或者分类树样本的分布类别差别很大,就会引入样本权重,这是我们需要注意这个值。
max_leaf_nodes: 最大的叶子节点个数,默认是None,即不限制叶子节点的个数,如果设置了这个值,那么决策树建立的过程中优化叶子节点的个数,如果特征不多,可以不考虑这个值,但如果特征多的话,可以加以限制。
class_weight: 指定样本各特征的权重,默认是balance,即算法自动调节权值。主要是为了
min_impurity_decrease: 最小的不纯度(基尼系数、信息增益等),如果小于这个数,那么就不会再往下生成叶子节点了。
2. 案例实战
2.1 案例简介
导入泰坦尼克号沉船幸存者数据,含有票价、性别、船舱等10项特征值,一列目标值即是否幸存。由于到目前为止文章暂未涉及特征工程等其他机器学习知识,在本章节中我们先选取其中性别、年龄、几等舱三项指标作为特征值,是否幸存作为目标值,构建决策树,帮助大家理解简单算法。后续等特征工程讲完,会将所有特征指标放入预测模型中。感兴趣的小伙伴,可看后续章节。
2.2 数据获取
数据集获取地址:https://github.com/fayduan/Kaggle_Titanic
#(1)数据获取
# 导入泰坦尼克号沉船幸存者和死者数据
import pandas as pd
filepath = 'C:\\Users\\admin\\.spyder-py3\\test\\文件处理\\泰坦尼克数据集\\taitan.csv'
data = pd.read_csv(filepath)
# survived列代表是否获救,pclass代表坐在什么等级的船舱

导入到数据中有数值型、字符串型数据,也存在缺失值,完整操作方法会在后续章节介绍。本节先使用性别sex、年龄age、几等舱pclass三项指标作为特征值,便于大家对决策树算法有个清晰的认识。
2.2 数据预处理
选取性别、年龄、几等舱所谓特征。处理缺失值nan,采用平均年龄填充年龄的缺失值,划分特征值features和目标值data_targets。
Pandas中填充缺失值的操作:变量名.fillna()
填充缺失数据方法:
(1)用某个值替换nan,返回新dataframe给新变量,原dataframe不变
变量名.fillna(替换值)
(2)直接对原dataframe修改,不产生返回值
变量名.fillna(替换值,inplace=True)
(3)使nan与前一行的值相同,默认所有nan都和前一行相同
变量名.fillna(method='ffill')
(4)使接下去的几个nan和前一行相同
变量名.fillna(method='ffill',limit=数量n)
#(2)数据处理
# 选取特征:几等仓、性别、年龄
features = data[['Pclass','Age','Sex']]
# 处理缺失值,缺失的年龄变成平均年龄
features['Age'].fillna(features['Age'].mean(),inplace=True)
# 获取目标值
data_targets = data['Survived']2.3 特征提取
由于特征性别sex对应的值是字符串类型,而最终的训练函数.fit()中,我们需要输入的是数值类型数据或sparse矩阵。因此我们需要对sex这一列进行处理,将其转换为数值型sparse矩阵。有关sparse矩阵及文本特征抽取方法的介绍见该篇文章的1.4小节:【机器学习】(2) 朴素贝叶斯算法:原理、实例应用(文档分类预测)附python完整代码及数据集
本次特征提取我们需要借助字典特征提取的方法 DictVectorizer(),先从sklearn中导入该方法:from sklearn.feature_extraction import DictVectorizer
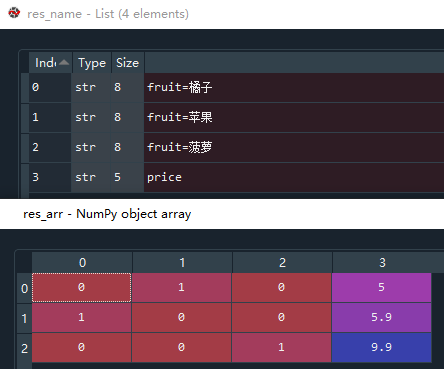
我举个例子帮助大家理解字典特征提取方法,首先我定义了一个由字典组成的列表,字典中有两个key,分别是fruit和price,将fruit对应的值'苹果''橘子''菠萝'从字符串类型转换成数值类型。要注意的是,vet.fit_transform() 函数中需要输入的类型是由字典构成的列表。这样才能将输入的文本类型转换成数值类型。用变量res接收sparse矩阵,使用 res.toarray() 函数将sparse矩阵转换成数组便于观察,vect.get_feature_names() 来获取sparse矩阵的特征名。
# 字典特征抽取
from sklearn.feature_extraction import DictVectorizer
fruits = [{'fruit':'苹果','price':5},{'fruit':'橘子','price':5.9},{'fruit':'菠萝','price':9.9}]
# vect接收字典特征提取方法
vect = DictVectorizer()
# 提取特征,并变成sparse矩阵
res = vect.fit_transform(fruits)
# 转换成数组,看得更清晰
res_arr = res.toarray()
# 获取sparse矩阵的特征名
res_name = vect.get_feature_names()
# 特征名为'橘子''苹果''菠萝''price'0代表橘子,1代表苹果,2代表菠萝,列表的第一个字典中的fruit是苹果,因此0和2索引对应的数值为0,即不是橘子和菠萝,同理列表的第2和3个字典。通过字典特征抽取,将文本数据转变成数值类型数据。
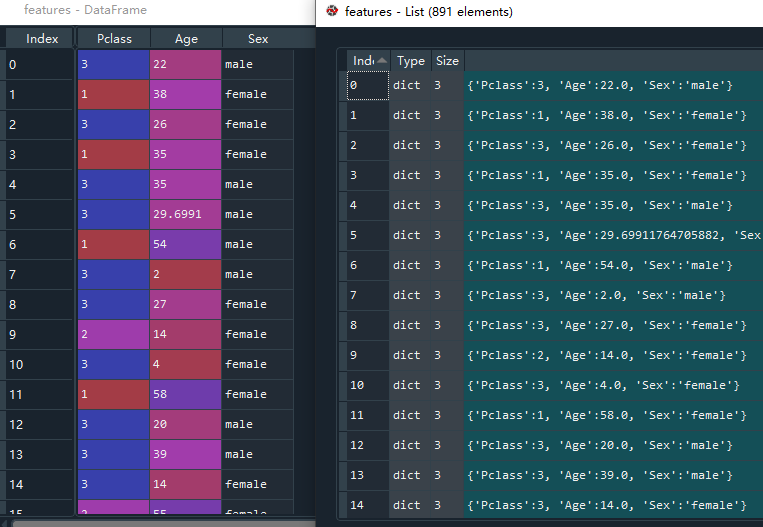
我们回到这个案例中进行特征抽取。现在的特征值是一个DataFrame类型,若想将文本数据转换数值数据,首先要将Dataframe数据转变成由字典组成的列表。借助.to_dict(orient = 'records')的方法,将特征值变成列表数据,用features接收,只有这种类型的数据才能传入vect.fit_transform()函数中,data_features接收的是类型转换后的sparse矩阵。
# sex特征是字符型数据,需要将其转换成数值类型,或变成sparse矩阵
from sklearn.feature_extraction import DictVectorizer #字典特征提取方法
vect = DictVectorizer()
# 将dataframe类型数据转换成由字典构成的列表:[{'pclass':3},{'age':20},{'sex':'male'}]
# 因为字典抽取方法vect.fit只能接收这种类型的数据
features = features.to_dict(orient = 'records')
# 提取特征值并转换成spase矩阵
data_features = vect.fit_transform(features)
2.4 划分训练集和测试集
一般采用75%的数据用于训练,25%用于测试,因此把数据进行训练之前,先要对数据划分。划分方法不再赘述,有疑惑的可看下文中的第2.3节:【机器学习】(2) 朴素贝叶斯算法:原理、实例应用(文档分类预测)附python完整代码及数据集
#(4)划分训练集和测试集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(data_features,data_targets,test_size=0.25)
2.5 决策树分类预测
#(5)使用决策树方法进行分类
from sklearn.tree import DecisionTreeClassifier
# 接收决策树分类器
classifier = DecisionTreeClassifier()
# 训练数据输入,fit()只能识别数值类型,或sparse矩阵
classifier.fit(x_train,y_train)
# 评分法,准确率
accuracy = classifier.score(x_test,y_test)
# 预测
# result = classifier.predict(需要预测的x特征值数据)
采用评分法.score(),得到该模型准确率在80%左右,如果需要预测.predict()函数输入的特征值x也需要是sparse数值型矩阵。本文就不写了,若果有兴趣的可在原数据的最后10行中划分特征值和目标值,特征值作为.predict()预测函数的输入,目标值用来预测验证最终预测结果的准确性。如果不会划分的话,可以看我前几篇机器学习文章,谢谢各位。
数据集获取
https://github.com/fayduan/Kaggle_Titanic
完整代码如下
#(1)数据获取
# 导入泰坦尼克号沉船幸存者和死者数据
import pandas as pd
filepath = 'C:\\Users\\admin\\.spyder-py3\\test\\文件处理\\泰坦尼克数据集\\taitan.csv'
data = pd.read_csv(filepath)
# survived列代表是否获救,pclass代表坐在什么等级的船舱
#(2)数据处理
# 选取特征:几等仓、性别、年龄
features = data[['Pclass','Age','Sex']]
# 处理缺失值,缺失的年龄变成平均年龄
features['Age'].fillna(features['Age'].mean(),inplace=True)
# 获取目标值
data_targets = data['Survived']
##(3)特征抽取
# sex特征是字符型数据,需要将其转换成数值类型,或变成sparse矩阵
from sklearn.feature_extraction import DictVectorizer #字典特征提取方法
vect = DictVectorizer()
# 将dataframe类型数据转换成由字典构成的列表:[{'pclass':3},{'age':20},{'sex':'male'}]
# 因为字典抽取方法vect.fit只能接收这种类型的数据
features = features.to_dict(orient = 'records')
# 提取特征值并转换成spase矩阵
data_features = vect.fit_transform(features)
#(4)划分训练集和测试集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(data_features,data_targets,test_size=0.25)
#(5)使用决策树方法进行分类
from sklearn.tree import DecisionTreeClassifier
# 接收决策树分类器
classifier = DecisionTreeClassifier()
# 训练数据输入,fit()只能识别数值类型,或sparse矩阵
classifier.fit(x_train,y_train)
# 评分法,准确率
accuracy = classifier.score(x_test,y_test)
# 预测
# result = classifier.predict(需要预测的x特征值数据)

















 1299
1299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











