







- 概念:
用鸟哥的话来说:
正则表达式是处理字符串的方法,它是以行为单位来进行字符串的处理行为,正则表达式通过一些特殊符号的辅助,是一种可以让用户轻易达到查找,删除,替换某特定字符串的处理程序.
首先,先概括性地列出常用的符号和代表意义.
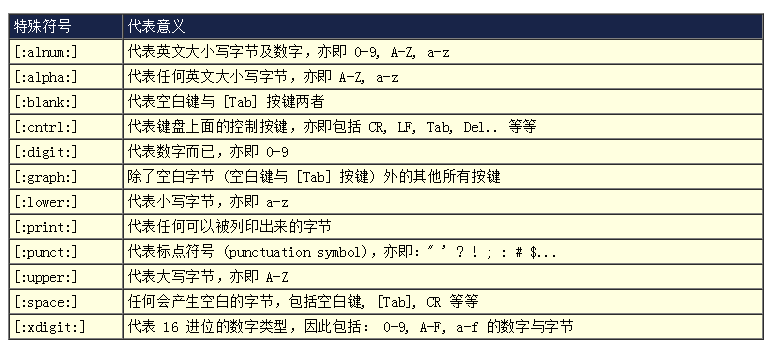
(图片出处:鸟哥Linux私房菜电子版)
这里先了解不同语系对正则表达式字符串排序(数字和大小写字母)的影响
因为后面如果对字符查找会由于范围有所不同而决定敲入指令的小差异.
- LANG=C的情况 : 0123…ABCD…XYZabcde…xyz
- LANG=zh_CH的情况:01234…aAbBcCdDeE…zZ
grep是一个常用的查找行命令,它也是使用正则表达式的常客.
-n 显示行数, –color=auto 将查找关键字显示其他颜色区分
-A+n (After)把找到的关键字所在行加上后续的n行一起显示出来.
-B+n (Befer)把找到的关键字所在行加上前面的n行一起显示出来.
-v 反选,除了关键字所在行的其他行显示出来.
例子:
1. grep ‘hello’ hello.txt
把hello.txt文件中关键字hello所在的行提取出来.
2. grep -n -A3 -B2 –color=auto ‘z++’ 凸图土兔utf8.txt

可以看到, ‘z++’所在行的前后3行都被提取出来.
3. grep -in ‘hello’ hello.txt
忽略大小写查找hello关键字所在行,即HeLLo,HELLO都会入选.
4. 查找范围选取’[ ]‘,在[ ]内表示任取一个字符进行匹配 如:
grep -n -A3 -B2 –color=auto ‘fo[rp]’ 凸图土兔utf8.txt
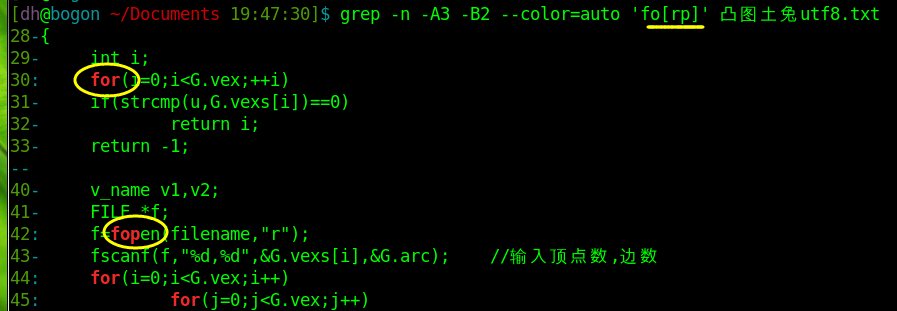
其中 for 和 fopen 都被匹配
5. [^abc],这里的^符号是取反的意思,表示不包含a或者b或者c,有趣的是也可以写成一个范围 用-表示,如[^a-z]或[^0-9]表示不含小写字母或者数字.
根据上面第一张参考图不包含小写字母和数字还可以写成:
grep -n –color=auto ‘[^[:upper:]]’ FILENAME
例子:
grep -n -A3 -B2 –color=auto ‘[^f]or’ 凸图土兔utf8.txt

其中表示查找 含有 or 的字符但是不匹配 f+or
另外注意,这里的取反只是部分取反,就是说如果该行有其他成立的符号还是会被筛选到.如下:

根据敲的命令行
’[^[:upper:]]’ 不提取那些大写字符的, 然而Hello World!却出来了,因为只看 ello orld的话同样符合条件!
’[^[:digit:]]’不提取数字行, 比较第黄色箭头我们可以看到那些所有字符成立的行才会被筛选掉. 2 和 233只是单纯包含文字,因此没有被选中.
行首字符‘^’ 和行尾字符‘$’
- ^除了有排除的意思,还作为表示行首的符号,如:
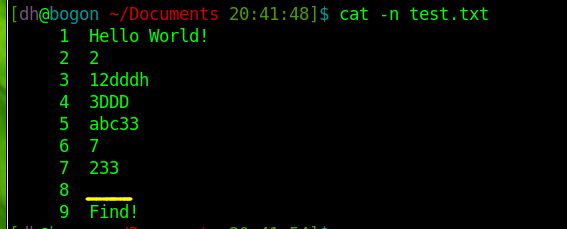
我们来看test的内容 其中第8行为空行
查找命令如下:
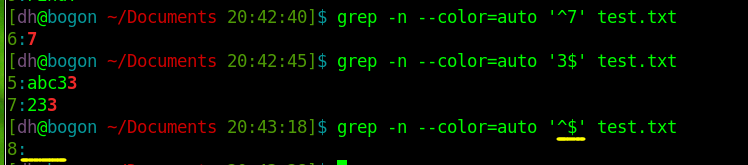
‘^7’表示以7开头的行,所以结果为第6行
‘3$’表示以3结尾的行,结果显而易见,如图.
而空白行怎么表示呢?这里比较形象可以理解为空白和就是只有开头+结尾 ,所以 敲入grep -n –color=auto ‘^$’ test.txt .
正因为‘^’有多个意思,所以使用容易混淆.这里鸟哥有用例子特别拿出来区分:
‘^’在中括号[]之内的表示方向选择,如’[^abc]d’ 表示ad,bc,cd 都会被排除. 而在中括号[]之外的表示定位在行首,如 ‘^[[:lower:]]’ 表示以小写字母开头的行
如:
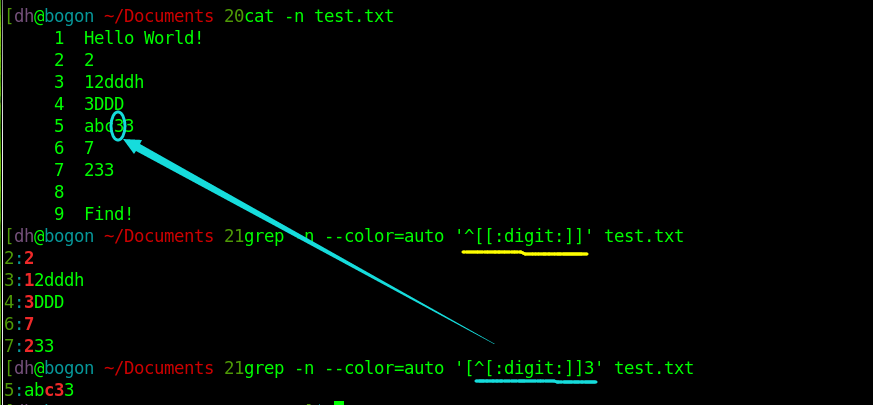
第一个查找以数字开头的行,第二个查找关键字3并且3前面必须没有数字,结果仅仅指向第5行abc33的第一个3 ,而3DDD尽管3前面没有数字,但是前面并没有字符,所以注意的是[]指的是里面必须有内容,
即‘[^[:digit:]]3’ 虽然指3之前不能出现数字,但是必须有其他字符替代才会筛选.
正则表达式还有很多知识点,这次先更新到这里,其他下次补充.
参考资料:
<鸟哥Linux私房菜p348-354>















 2186
2186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









