







什么是tesseract-ocr
OCR(Optical Character Recognition):光学字符识别,是指对图片文件中的文字进行分析识别,获取的过程。
Tesseract:开源的OCR识别引擎,初期Tesseract引擎由HP实验室研发,后来贡献给了开源软件业,后经由Google进行改进,消除bug,优化,重新发布。
现在托管在GitHub中~
源代码位置
托管于 http://code.google.com/p/tesseract-ocr/
目前项目转移到GitHub https://github.com/tesseract-ocr
下载源代码
最终选定的是托管在GitHub上的3.0.2分支
wget https://github.com/tesseract-ocr/tesseract/archive/3.04.zip
编译安装
unzip 3.04.zip
cd tesseract-3.04/
./configure
安装leptonica
报错:
leptonica... configure: error: leptonica not found解决方案: 安装 leptonica
官网地址: http://www.leptonica.org/download.html
wget http://www.leptonica.org/source/leptonica-1.72.tar.gz
tar xvzf leptonica-1.72.tar.gz
cd leptonica-1.72/
./configure
make && make install完成安装
./configure
make && make install
sudo ldconfig配置文件位置
/usr/local/share/tessdata语言文件
文件源码
我们需要下载支持的语言对应的配置中
GitHub地址 https://github.com/tesseract-ocr/langdata
修改变量
创建存放语言文件的文件夹 /usr/local/share/tessdata/lang
修改配置的变量 export TESSDATA_PREFIX=/some/path/to/tessdata
这里注意的是,我们修改的是路径的前缀,真实的语言文件的路径实际是/usr/local/share/tessdata/lang/tessdata
否则就会出现下面的错误

放到配置文件夹
解压之后放到语言配置文件夹中
wget https://github.com/tesseract-ocr/tessdata/archive/master.zip使用
准备测试图片
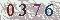
上传到测试服务器
scp code.jpg root@xxx.xxx.xx.xx:/data/
验证
tesseract /data/code.jpg out
查看结果
cat out.txt
0376
-
安装完成,验证正确~
-
)
















 2690
2690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











