






2019年4月1日21:32:02
今天阅读了Charu C . Aggarwal 著作《推荐系统-原理与实践》,主要内容包括 矩阵分解
1、无约束矩阵分解
a) 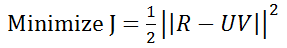 ,满足U和V上无约束
,满足U和V上无约束
b) 预测矩阵R的(i,j)位置的值
c) 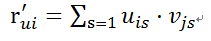
d) 梯度求导需要对同时求导
2、随机梯度下降
a) 对矩阵中是数据进行随机打乱,更细已知点的值
3、正则化
a) 正则化是当评分矩阵R稀疏且已知值相对较少时,会出现过拟合问题。为了解决过拟合问题,在目标函数中添加了正则项,其中为正则化参数,非负数,正则化其实是加入了矩阵的二范数。
b) 正则化目标函数为
c) 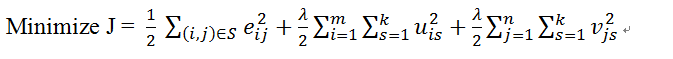
4、增量式隐分量训练
a) 类型循环训练的方式,每次仅对q=1执行更新,分别学术U和V的第一列和。然后从R中减去外积矩阵。如此循环。
b) 增量方法需要调整外循环的两次执行之间的评分矩阵。因此优化的参数较少,该方法会对每个分量的收敛更快、更稳定。
5、交替最小二乘和坐标下降
a) 交替最小二乘法
i. 固定U不变,通过将问题转化为最小二乘回归问题来处理V的n行中的每一行。每行计算相互独立,可并行计算。
ii. 保持V不变,通过将问题转化为最小二乘回归问题来处理U的m行中的每一行。每行计算相互独立,可并行计算。
iii. 这两个步骤迭代直到收敛。当目标函数中包含正则化项,依旧进行迭代。
b) 坐标下降法
i. 通过对矩阵中的每个点,中的每个点,保持其他参数不变,每次进行训练其中的一个点,类似训练坐标(i,j)。
6、合并用户和物品偏差
a) 思想为用户可能存在评价偏差,一些用户偏向于给高分,一些用户偏向于给低分,即吝啬用户。
b) 通过引入变量,表示用户评分值的一般偏差。
c) 同样的,可能一些商品存在好评,大卖的商品能够普遍获得较高的评分,而残次品可能普遍获得较低评分
d) 通过引入变量,表示商品评分的一般偏差
e) 损失变为
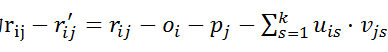
2019年4月2日22:03:56
决策树方法
决策树是对特征向量上的特征,构造树节点,并基于基尼指数
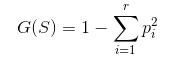
来评估节点划分的准确性。
非对称因子模型
非对称因子模型主要创新在于引入; 隐式反馈矩阵。 对于m X n 的评分矩阵R,如果r_ij 已知,则将mXn隐式反馈矩阵的F=【f_ij】置为1,如果未知,则为0.
也就是说 假定用户已经给出了评分,则对物品的评价已经产生了信息,无需考虑对应的评分结果是多少。 训练过程,用矩阵 FY 用与替代用户因子矩阵 U 。 、
评分矩阵被分解为 R≈[ FY ] V^t 。
主要创新在于用FY 来代替 传统因子分解的 FY
该思路可以简化模型训练过程,参数更少,且效果依旧能够得到提升。
SVD++(虽然就SVD++,其实矩阵并非正交,存在误导)
SVD++ 中,将隐含用户-因子矩阵FY不用于创建显示用户-因子矩阵 U,而仅是调整它。
预测评分r_ij表示为
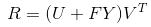
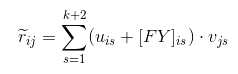
奇异值分解(SVD)
奇异值分解是矩阵分解的一种形式,其中 U 和 V 的列被限定为相互正交的。相互正交的优点在于。概念可以完全独立于彼此且可以在散点图中进行几何解释。
其中、
、
分别是mxk 、kxk、nxk的矩阵。
用户因子定位为 ,
。
分解过程的目标是用正交列发现矩阵 U 和 V ,故SVD可以表示为矩阵 U 和 V 上的优化问题。
满足:
U的列相互正交
V的列相互正交
非负矩阵分解
非负矩阵分解的优势在于,较强的可解释性。要求矩阵中的每一项均为非负数。
优化目标函数为
相当于在迭代过程中,对r_ij 嵌套了 max(r_ij ,0)
矩阵因子分解总结
前文赘述的各种矩阵因子分解模型,有很多相同之处。所有之前提到的优化问题都在对因自己在U 和 V 的各种约束下是的剩余矩阵 (R-UV^t)的 Forbenius范数(F范数)最小化。目标函数的目的是是的UV^t 尽可能近似评分矩阵R。对因子矩阵的限制则实现不同程度的可解释性。
广泛的矩阵分解模型家族可以使用任何其他目标函数或约束来达到相似的近似。 泛化的形式为
Optimize J = 【对于R和 UV^T的匹配进行量化的目标函数】, 满足:U和V上的约束。
通常会加入正则化因子 防止过拟合。
| 方法 | 约束 | 目标 | 缺点 |
| 无约束 | 无约束 | Forbenius + 正则项 | z最优质的解;对大多数矩阵适用;正则化避免过拟合;可解释性差 |
| SVD | 正交 | Forbenius+正则项 | 可视化的解释;样本外推荐:适用于密集矩阵;语义可解释性差;系数矩阵效果不好 |
| 最大裕量 | 无约束 | 铰链损失+裕量正则化 | 最优质的解;避免过拟合;与无约束情况类似;可解释性差;适用于离散评分 |
| 非负矩阵分解 | 非负 | Forbenius+正则化 | 优质解;高语义可解释性;可以同时对喜欢和不喜欢进行评分时可解释性差;一些情况下较少出现过拟合;最适合用于隐式反馈 |
| 概率隐语义分析 | 非负 | 最大似然+正则化 | 优质解;高语义可解释性;概率可解释性;可以同时对喜欢和不喜欢进行评分时可解释性差;一些情况下较少出现过拟合;适合用于隐式反馈 |















 246
246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









