







机器学习——算法基础(决策树,随机森林)
分类算法-决策树
认识决策树
决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法
信息熵

“谁是世界杯冠军”的信息量应该比5比特少。香农指出,它的准确信息量应该是:
H = -(p1logp1 + p2logp2 + … + p32log32)
H的专业术语称之为信息熵,单位为比特。
公式:
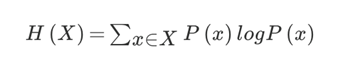
当这32支球队夺冠的几率相同时,对应的信息熵等于5比特
决策树的划分依据之一-信息增益
信息增益:当得知一个特征条件之后,减少的信息熵的大小。
特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,即公式为
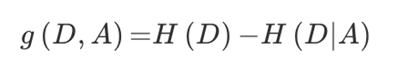
注:信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度
信息增益的计算

常见决策树使用的算法
ID3
信息增益 最大的准则
C4.5
信息增益比 最大的准则
CART
回归树: 平方误差 最小
分类树: 基尼系数 最小的准则 在sklearn中可以选择划分的原则
( 基尼系数相比于信息增益划分更为细致)
sklearn决策树API

决策树的结构、本地保存

决策树的优缺点以及改进
优点:
简单的理解和解释,树木可视化。
需要很少的数据准备,其他技术通常需要数据归一化,
缺点:
决策树学习者可以创建不能很好地推广数据的过于复杂的树,这被称为过拟合。
决策树可能不稳定,因为数据的小变化可能会导致完全不同的树被生成
改进:
减枝cart算法
随机森林
集成学习方法-随机森林
什么是集成学习
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测
什么是随机森林
定义:在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
随机森林建立多个决策树的过程

学习算法
根据下列算法而建造每棵树:
用N来表示训练用例(样本)的个数,M表示特征数目。
输入特征数目m,用于确定决策树上一个节点的决策结果;其中m应远小于M。
从N个训练用例(样本)中以有放回抽样的方式,取样N次,形成一个训练集(即bootstrap取样),并用未抽到的用例(样本)作预测,评估其误差。
集成学习API

随机森林的超参数:
- n_estimators:决策树的数量
- max_depth:每棵树的深度限制
随机森林的优点
在当前所有算法中,具有极好的准确率
能够有效地运行在大数据集上
能够处理具有高维特征的输入样本,而且不需要降维
能够评估各个特征在分类问题上的重要性
对于缺省值问题也能够获得很好得结果
















 298
298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











