






 本文介绍了编译器前端的基础知识,包括词法分析、语法分析和语义分析。词法分析通过有限自动机识别Token,语法分析构建抽象语法树(AST),语义分析确保程序的正确性。了解这些原理对于开发者更好地理解框架和工具的工作机制至关重要,例如Spring框架中的注解处理和Babel的语法转换。此外,编译器的正确性是保障代码安全的关键,可信编译器的实现包括编译器自身的可信和生成代码的可信。
本文介绍了编译器前端的基础知识,包括词法分析、语法分析和语义分析。词法分析通过有限自动机识别Token,语法分析构建抽象语法树(AST),语义分析确保程序的正确性。了解这些原理对于开发者更好地理解框架和工具的工作机制至关重要,例如Spring框架中的注解处理和Babel的语法转换。此外,编译器的正确性是保障代码安全的关键,可信编译器的实现包括编译器自身的可信和生成代码的可信。
作为一名程序员,编译器是我们日常开发中时时刻刻都会用到的工具。但是现在很多程序员往往都忽略了编译器的重要性和背后的原理,他们会说:「我不可能去写一门新的语言,还有必要学习编译技术吗?」这种想法是把编译技术的用途简单化了。编译原理不只是炫耀的屠龙技。在实际工作中,我们经常会碰到需要编译技术的场景。
Java 程序员应该会非常熟悉 Spring,在 Spring 框架中对注解的支持和字节码动态生成都属于编译技术;前端程序员通常会使用 Babel 这个工具,主要是为了将ES6语法编写的代码转换为做向后兼容的 JS 语法,以便运行在旧版本的浏览器中,那么在不同语法转化的过程中也是用到了编译技术 ,所以想要学好框架和工具,编译技术是必不可少的。
1. 编译器过程
编译器也是软件,有输入和输出,它的输入就是源代码,它的输出是目标代码,在输入到输出的过程中,我们将其分为编译器前端和编译器后端。这里的「前端」指的是对程序代码的分析和理解过程。它通常只跟语言的语法有关,跟目标机器无关。而「后端」则是生成目标代码的过程,跟目标机器有关。为了方便理解,下图展现了编译器的整个编译过程。

在很多大学教授的编译原理或使用的编译技术的场景中,只需要前端技术就能解决,比如之前提到的 Babel 工具,就只是用到了前端技术,并没有生成与目标机器有关的代码。今天在这里,我们主要去了解编译器前端的基础知识。
2. 词法分析
编译器的第一阶段工作是词法分析。当阅读一遍英语文章时,我们会将其看做一串英文单词来阅读而不是一个个字母。当编译器在阅读程序代码时,也会将其视为一个个词法标记(Token),词法标记(Token)是就是构成源代码的最小单元。后续直接将其称为 Token。
举个简单的例子,如果编译器需要分析出 Token 序列,需要怎么做呢?
public class Test {
public static void main(String[] args) {
int age = 25;
}
}
首先我们需要了解什么样的一串字符才算是一个 Token,在上面的代码中, public、 static、 ;、 age、 =等这样的字符序列都算是一个 Token,每一种语言都有它自己对 Token 定义的一个说明,具体需要在官方文档中查阅。
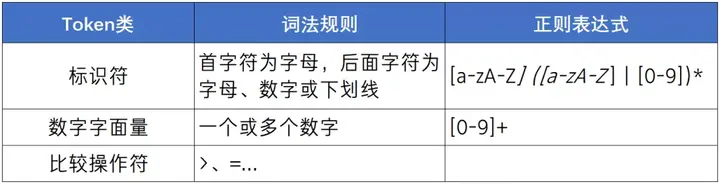
我们将这些 Token 做个分类,将其分为数字字面量、标识符、比较操作符等等,下面列一张表简述一下各类 Token 的词法规则,并且这些词法规则可以通过正则表达式来定义。
编译器是从第一个字符开始往后一个一个读取字符的。那么如何识别出 Token呢?通常情况下,我们会根据空格来识别出 Token,当编译器读取到空格时,那么认为当前 Token 读取完毕,接下来读取下个 Token,但是我们知道在写代码过程中,没有空格也是被允许的,比如上面代码中 intage = 25 也可以写成 intage = 25,所以空格这种策略是有待改进的。
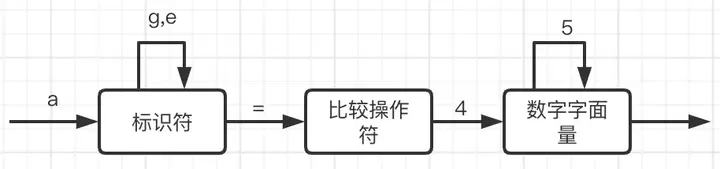
那么如何更高效的识别呢?有限自动机算法会帮助我们解决这个难题。有限自动机是有限个状态的自动机器,它会分析整个程序的字符串,当遇到不同的字符时,会驱使它迁移到不同的状态。
例如扫描 age 时,处于标识符状态,当它遇到一个 = 符号时,就切换到了等于操作符的状态,在切换之前,会将所读取到的字符 a、 g、 e 构成一个 Token,每次切换不同状态,都会得到一个新的 Token,直到程序读取结束。词法分析过程,就是这样一个个状态迁移的过程。
3. 语法分析
编译器的下一个阶段工作是语法分析。词法分析是识别出一个个Token,那么语法分析是在词法分析的基础上分析出语法结构的。
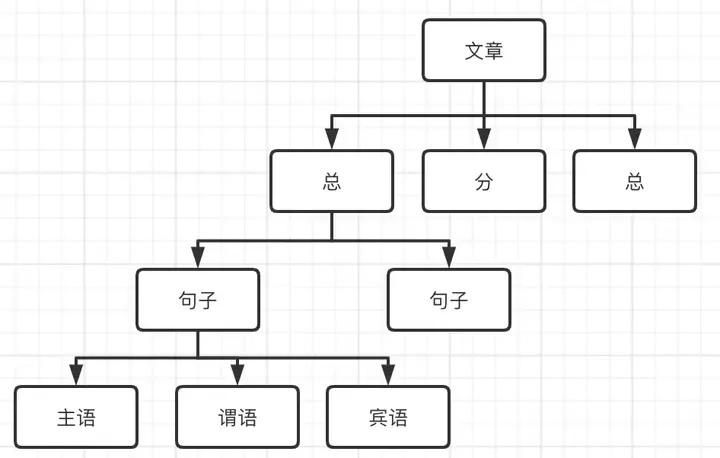
我们日常在写文章造句都会遵循着主谓宾、总分总这样的结构,这样的结构会让我们阅读起来非常流畅。而程序拥有良好的语法结构也会让编译器读取起来非常方便。而在编译器中这种语法结构是树状结构,因为计算机会更加容易理解和分析树这种数据结构。
我们将这颗树叫做抽象语法树(Abstract Syntax Tree,AST)。树的每个节点是一个语法单元,这个单元构成的规则叫做语法规则(与词法分析的词法规则不同)。如下图,一篇文章的语法结构是这样的。
程序也是如此,总是一个结构套着另一个结构,大的程序套着子程序,子程序中也包含着其他程序。在这里,我们画出 1+2*3 这个表达式的语法结构。
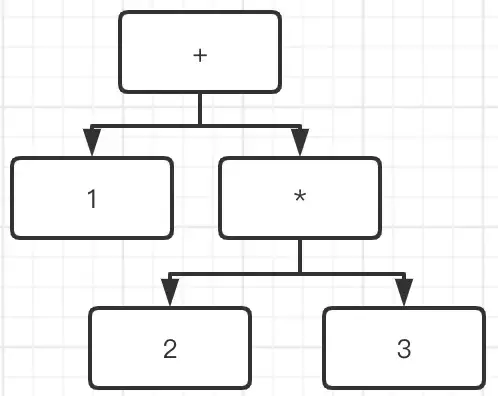
那么计算机怎么去处理这个表达式的树结构,树结构又有什么优势呢?其中一个优势,是每一个子节点都可以通过遍历节点的子树获取该节点的值,当我们从根节点遍历这颗树时,我们就可以获得这个表达式的值。
首先 + 号根节点读取到 1 和 * 子树的结果,并将它们相加。那么在获取 * 子树的结果就是遍历 * 的子树,将 2 与 3 读取并且相乘得到 6。最终将 6 与 1 相加得到最终结果为 7,这样我们就获得了表达式的值。
如果再将判断语句、循环语句等节点加到 AST 上,并且遍历执行它。那么其实我们是在执行一个脚本程序。所以脚本语言的执行,就是遍历 AST 的过程。
4. 语义分析
编译器前端的最后一项工作是语义分析,语义分析就是让计算机理解我们真正的意图,把一些模棱两可的地方去掉。更简单的说法就是联系上下文。
在阅读文章时,我们需要联系上下文才能真正明白作者的意图;在编译器理解程序时,也需要联系上下文,比如:
- 在同一个作用域中,不允许有两个名称相同的变量,这是唯一性检查。
- 表达式的数据类型是什么,需要做类型推断吗,如果在推断的过程中,出现类型不匹配的时候,是报错还是自动转换?
上面这些就是语义规则。语义分析就是把根据语义规则进行分析判断,然后将分析成果标注在 AST 上,做了这些标注后,编译器在后面就可以根据这些信息生成目标代码了。
5. 小结
编译器前端的基础知识我们已经学习完了,我们来总结一下学习内容。
- 词法分析是把程序分割成一个个 Token 的过程,通过有限自动机算法来实现。
- 语法分析是把程序的结构识别出来,并形成一棵抽象语法树。
- 语义分析是生成一些属性信息,让计算机能够依据这些信息生成目标代码。
当然各个阶段的一些算法并没有还具体展开讲,语法分析中的递归下降算法也并未涉及。之后有机会再进行讲解。
其实现在的编译器前端已经发展的很成熟,我们并不需要手写编译器。有一些现成的工具会帮我们去做词法分析、语法分析,比如 Yacc(GNU版本,Bison)、Anltr、JavaCC 等等。我们只需要输入 Token 词法表、语法规则文件后,工具自动会帮我们生成词法解析器和语法解析器。
6. 可信编译器
编译器作为用于产生代码的工具,编译器的实现和维护自然经过了「精雕玉琢」,因此编译器的正确性问题容易被人们忽视。但了解实际情况的人都知道,编译器的「误编译」问题是司空见惯、习以为常之事。对于许多领域来说,由于一般不会引发本质的问题,又是小概率事件,人们也往往容易忽视误编译所带来的影响。
如何才能保证编译器的安全和可信?对于编译器来说,安全和可信的具体指标就是其正确性,要保证从源程序到目标程序的翻译过程正确,即保证源语言的行为特征能够在目标语言中被正确地体现,杜绝「误编译」。可信编译具有两方面含义:
- 编译器自身是可信的。 即必须保证整个编译操作的可信性, 保证编译器在编译过程中不会给编译处理对象带来任何安全性问题, 防止恶意攻击者通过修改编译器, 在编译过程中对代码的原始语义进行篡改, 影响程序代码本身的可信性。
- 编译所得可执行程序代码是可信的。 可信编译器除实现传统的编译功能外,还需对其编译对象的安全性进行检测加强、可信性进行验证, 确保系统安全、可靠运行。
目前保证可信性的方法主要有两类:
- 非形式化的方法(或传统的方法),如采用测试和过程管理;
- 采用形式化的方法,主要包括直接对编译器本身进行验证和翻译确认,以及混合使用这些方法。
由迪捷软件自主研发的 ModelCoder 是一款支持多种嵌入式系统建模并可以自动生成高安全可靠的C代码的软件设计和开发工具。支持同步数据流以及状态机等嵌入式模型,其从模型生成代码的过程经过了形式化验证,以保证生成过程的正确无误性。

ModelCoder 采用了最严格的形式化技术,用定理证明的方式对模型到代码的生成过程进行了严格的数学证明,早期应用于填补了国内空白的核级DCS控制系统,攻克了软件代码生成技术这一世界性难题。同时,也应用于飞机的飞控,飞机的航电等多个安全关键领域的嵌入式软件的设计和开发过程中。
















 234
234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









