






概述
在日常对话中,由于我们的大脑记录了对话的历史信息,为了减少冗余的内容,在进行回复时通常会存在指代和省略的情况。因为人脑具有记忆的能力,能够很好地重建对话历史的重要信息,自动补全或者替换对方当前轮的回复,来理解回复的意思。
但是对于大模型的对话,模型并没有人脑这样的能力,在用户进行多轮对话时,用户的简短提问可能会指代上文中的部分信息,如果仅用当次问题去问答,会使对话效果不佳,大模型答非所问,效果较差。另外,在基于私域知识内容的场景下,需要先基于向量检索所需的内容,此时会存在检索不到有效信息导致无法获得有效回答等问题。
QA增强
QA增强即多轮对话增强,它的核心其实在于对指代进行消解和省略补全;根据历史轮和当前轮的对话,从候选会话历史的集合中找到最适合对应指代位置的答案,然后将指代具体化,或者预测指代可能的具体内容以补全省略信息。或者,提升更加精确的语义粒度和句法完整度。
它解决的问题是防止多轮对话情况下,拿来检索的问题不是用户的真实意图,提高对话的回复效果。但缺点是需要大型语言模型(LLM)生成一轮对话,这会影响性能并且需要消耗大量的token。
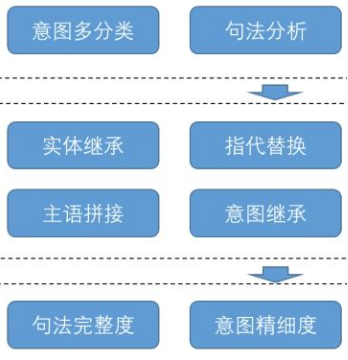
基于Langchain的多轮对话构建QA增强

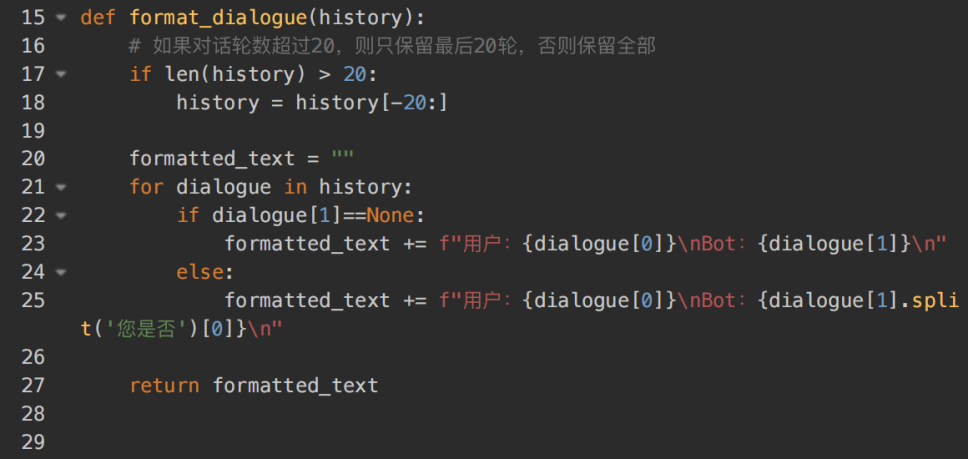


以下是一个QA转换后的例子,将指代内容替换之后的输出(基于知识库的检索问答)
Q1:RAG是什么?
Q2:它的步骤有哪些?=====》RAG基本流程有几个步骤?
Q3:它的检索操作怎样的?==》请问RAG中的检索召回环节具体包括哪些操作?
历史会话信息如下:
[HumanMessage(content='什么是RAG'), AIMessage(content='RAG是Retrieval Augmented Generation的缩写,是一种检索增强生成技术。它类似于搜索引擎,但是作为一个中间件技术,检 索到的结果不会直接作为最后的输出,而是将其插入prompt中在喂给大模型,通过提高prompt中上下文的质量来提高模型回复的效果。RAG的主要作用是在大模型之前的部分,即数据检索和信息整合。'),HumanMessage(content='RAG基本流程有几个步骤?'),AIMessage(content='RAG的基本流程包括以下步骤:\n1. 数据准备\n2. 内容检索\n3. 生成\n在数据准备阶段,需要进行数据加载、文本切片、向量化等操作。在内容检索阶段,需要进行向量化、相似度计算、文档召回等操作。在生成阶段,需要进行向量化、生成答案等操作 。'), HumanMessage(content='请问RAG中的检索召回环节具体包括哪些操作?'), AIMessage(content='RAG中的检索召回环节包括以下操作:\n1. 数据读取与预处理\n2. 数据切片环节,包括按Token长度切片、按中文各符号递归分割、Markdown格式切片、HTML格式切片、按不同语言的代码规则切片、表格切片等\n3. 数据语义级预处理环节,包括关键信息抽取和自动生成问题\n4. 向量化环节,包括Embedding Model选型和embedding model微调\n5. 数据入库环节\n6. 内容检索,包括输入向量化、相似度计算和文档召回')
在上面的场景中,我们需要了解RAG的相关知识,在后续对话中的指代和省略的内容需要替换成RAG的相关描述,在检索阶段搜索到有效的信息。
问题的全面性重构QA增强
优点:提供更全面的回答。
缺点:可能影响性能;生成的问题有小概率不准确。
对用户问题生成若干个相似问题或其他角度的问题,确保召回信息的全面性。根据内容总结出最合适的提问方式。
总结
QA增强的目的旨在提高模型的回复效果,从而获得更有效的信息。在实际使用过程中,可以通过使用场景调整prompt,提供一个对话的大背景,以便于模型给出更好的问题重构。同时,使用如Qwen1.5、LLaMA7B这样经过特殊训练、针对语义优化的小模型,可以提高问题重构的效率。
在QA重构后,问答效果会有明显改善,相关指标提升显著。另一方面,有效的召回检索信息使得额外的信息可以顺利地接入,例如,利用用户历史数据可以使模型效果持续提升和优化。















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









