






问题描述
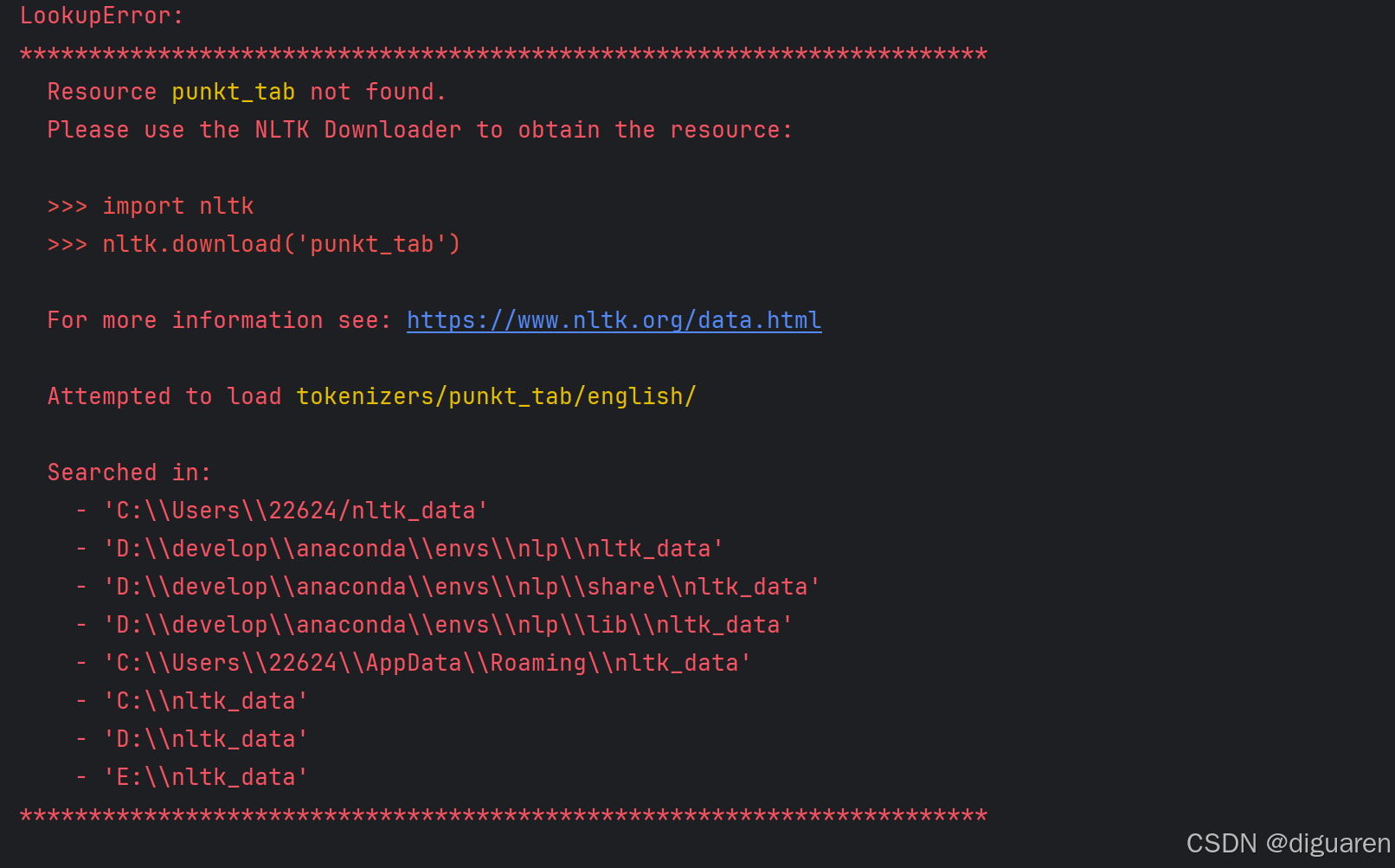
从错误信息来看,我的程序尝试使用NLTK库中的sent_tokenize函数来对文本进行句子分割,但是它找不到所需的punkt资源。这个资源是NLTK用来进行句子分割的预训练模型。
解决方法
第一步:在使用nltk这个工具包时,需要的数据通常是不能通过nltk.download(‘xxx’)下载下来的,我们可以从官网http://www.nltk.org/nltk_data/,或者直接在我的主页发的共享资源下载即可。
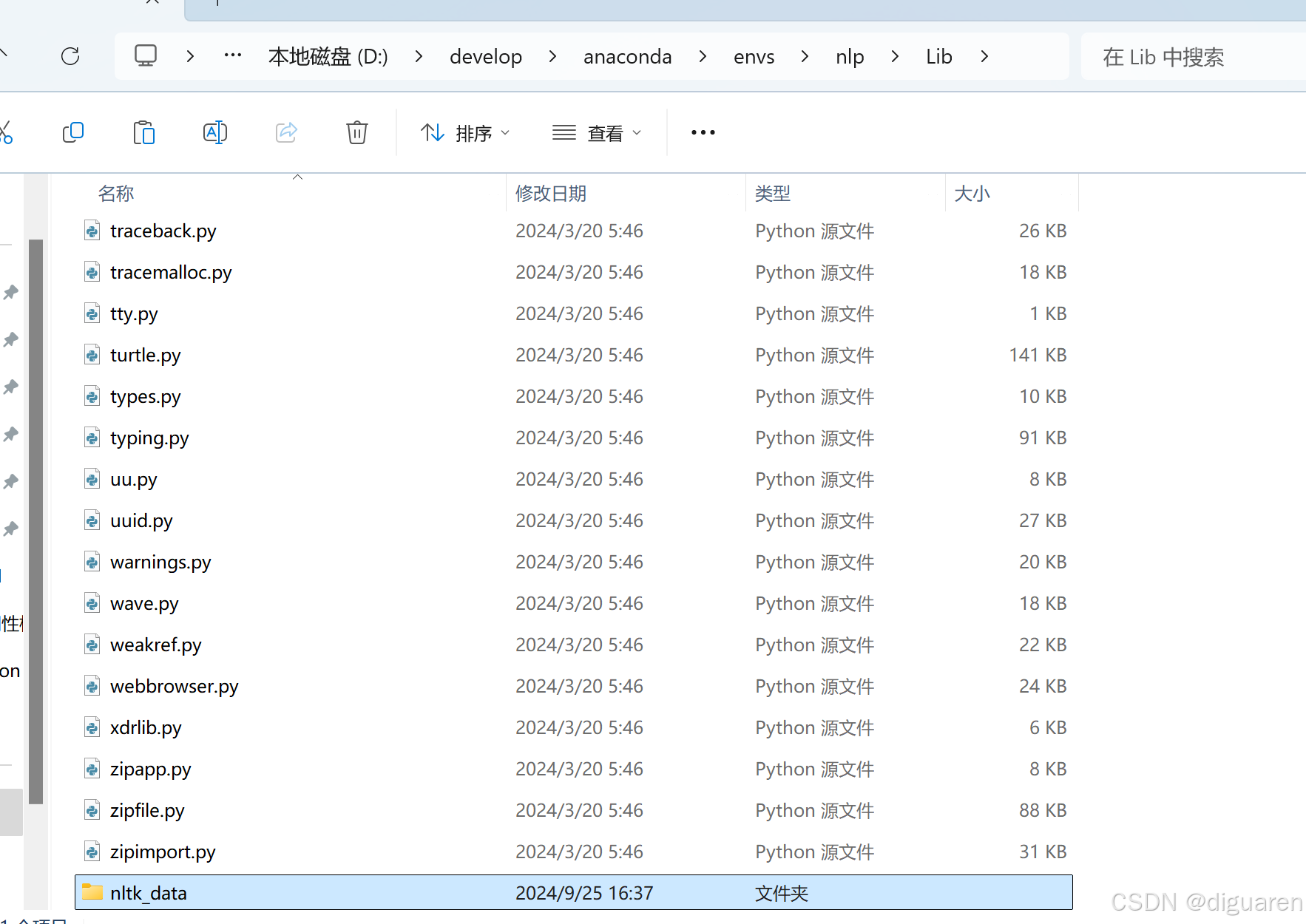
查看放入puntk的位置,找到这些目录的任意一个目录就行
import nltk
nltk.word_tokenize("dsd dcascacav ds")
第二步:下载完nltk_data_gh_pages.zip文件,解压后将该文件放在上述任意一个文件夹内。(注意:一定要改名字为nltk_data)。
第三步:将解压后的文件夹的packages 内的tokenizers复制到nltk_data目录下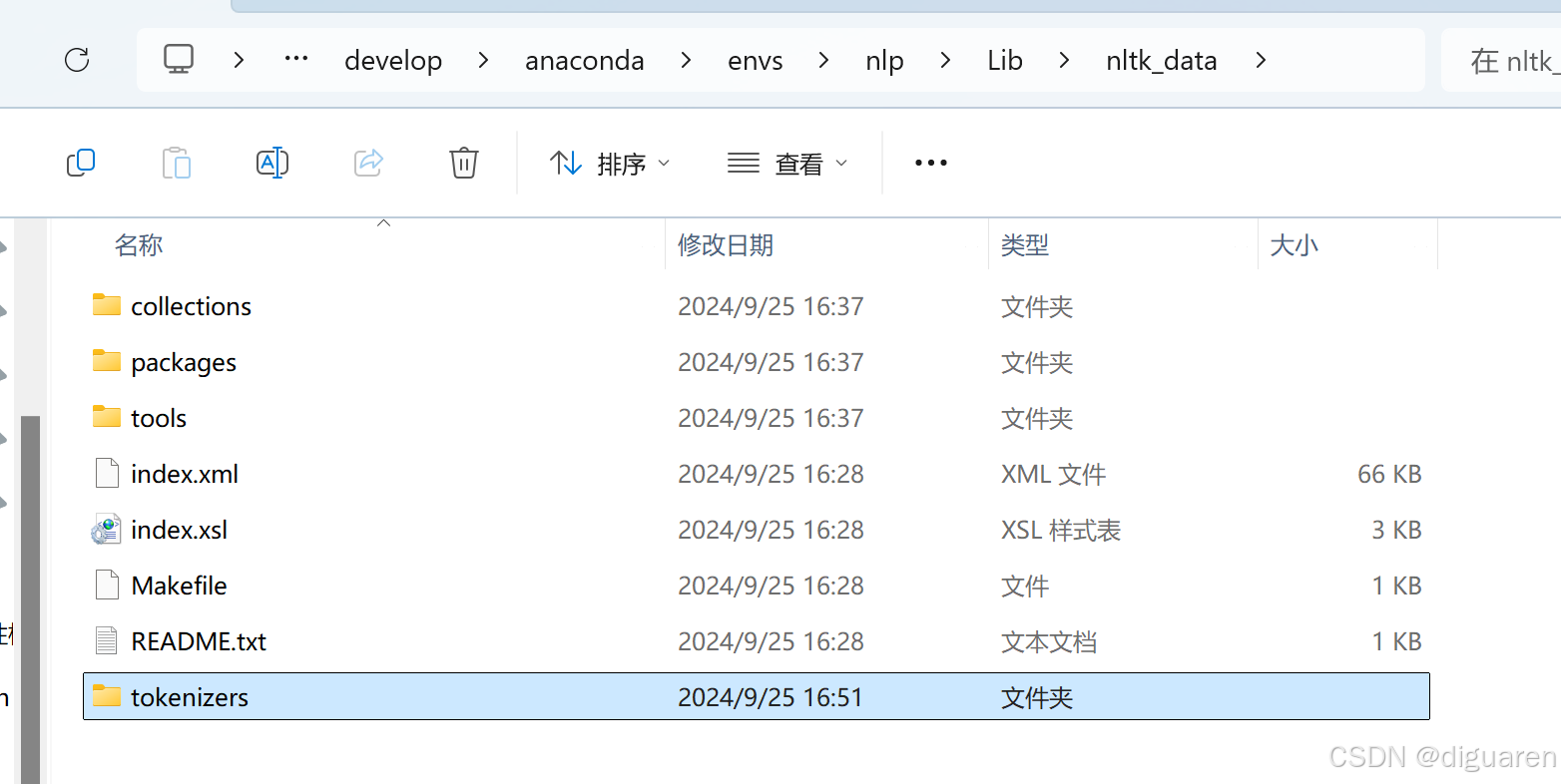
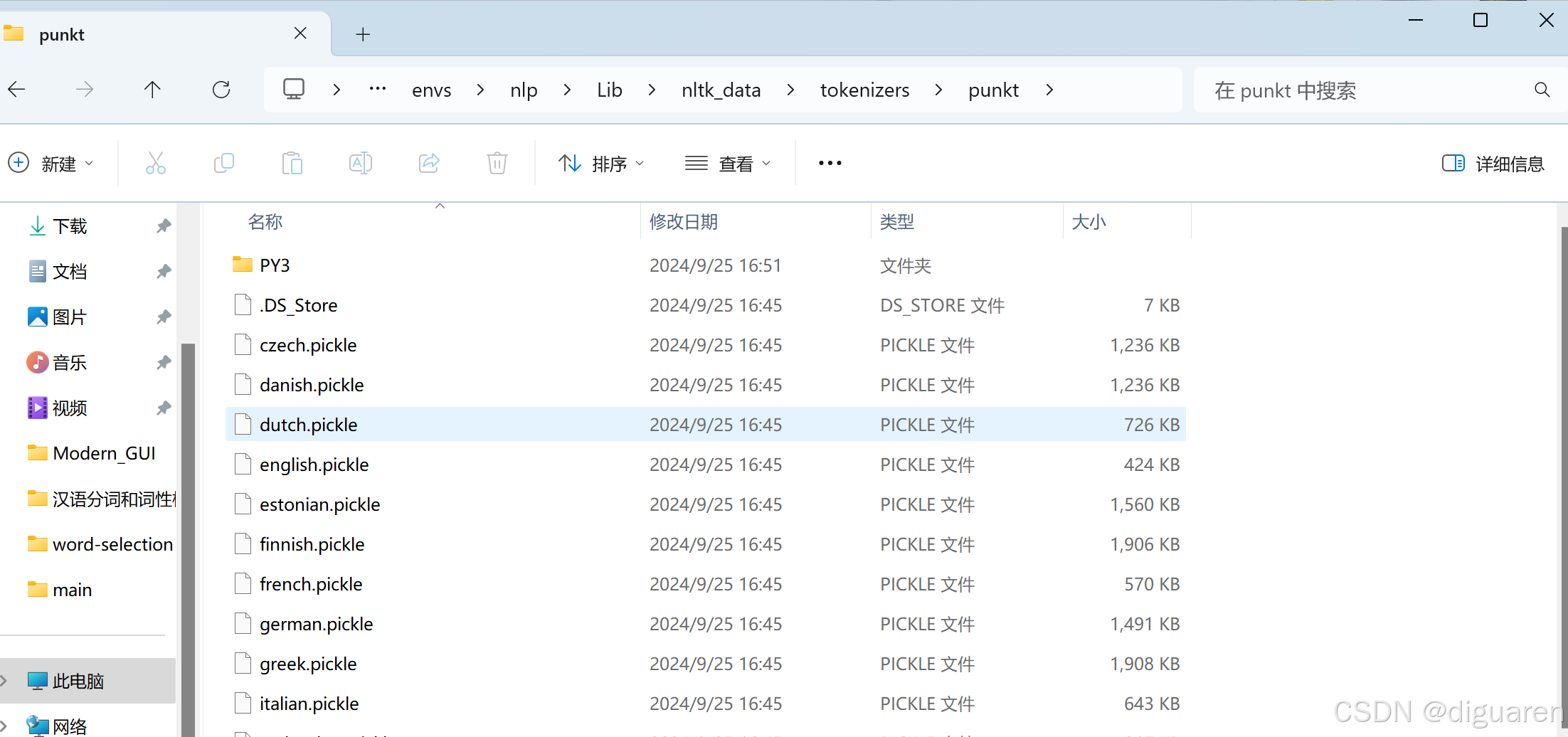
第四步:解压puntk文件,注意解压的时候不要造成目录嵌套如:nltk_data\tokenizers\punkt\punkt的情况出现,理想状态是nltk_data\tokenizers\punkt\


















 902
902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











