






轻量级自适应提取模块 (LAEM) 与多路径分流特征匹配模块 (MSFM)

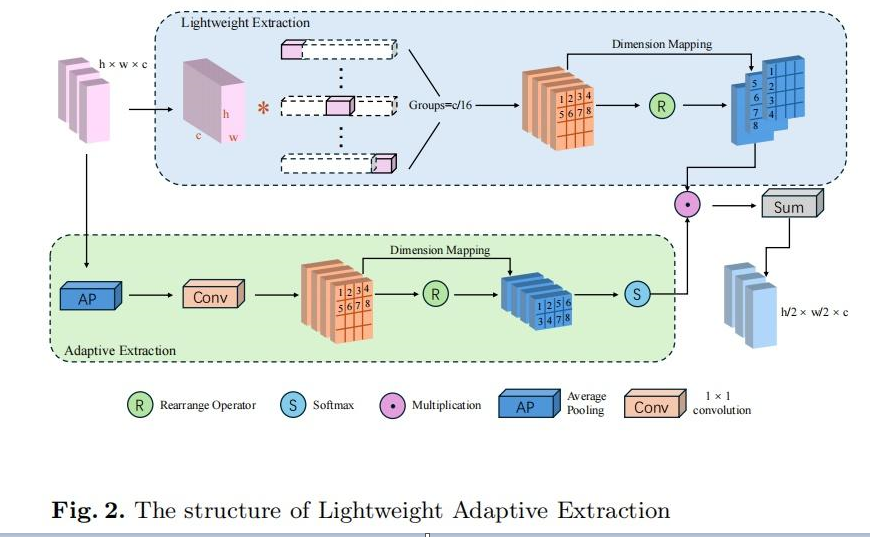
1. 轻量级自适应提取模块 (LAEM)
功能
通过自适应保留高信息熵像素,优化降采样过程,保留医学图像中的边缘和角落信息,降低计算复杂度。
实现流程
- LE 路径:通过组卷积将空间信息映射到通道维度,四倍降采样,保留空间结构。
- AE 路径:通过平均池化降采样,结合 softmax 计算像素权重,优先保留高信息熵像素。
- 特征融合:两路径输出拼接,通过 1x1 卷积整合通道信息。
Lightweight Adaptive Extraction 结构图:
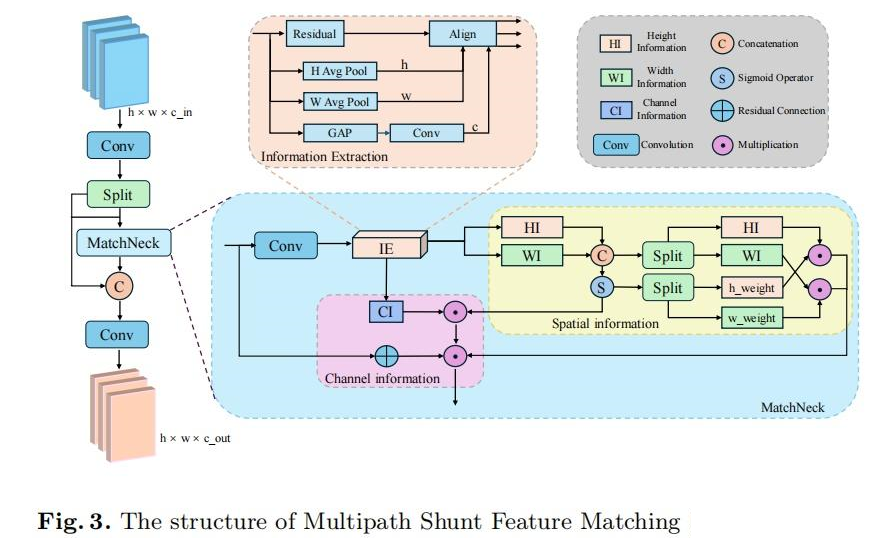
2. 多路径分流特征匹配模块 (MSFM)
功能
通过多路径分流和空间-通道信息协同融合,增强 ROI 特征表达,捕捉复杂空间关联。
实现流程
-
特征分流:输入特征分为空间和通道信息分支。
-
MatchNeck 块
:
- 空间信息分支:平均池化提取空间信息,softmax 计算权重,与通道信息相乘。
- 通道信息分支:全局平均池化提取通道信息,与空间分支融合。
-
特征整合:空间权重与通道信息相乘,拼接后通过残差连接和 1x1 卷积优化。
Multipath Shunt Feature Matching 结构图:
3、代码实现
import torch
import torch.nn as nn
from einops import rearrange
class MatchNeck_Inner(nn.Module):
def __init__(self, channels) -> None:
super().__init__()
self.gap = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
Conv(channels, channels)
)
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
self.conv_hw = Conv(channels, channels, (3, 1))
self.conv_pool_hw = Conv(channels, channels, 1)
def forward(self, x):
_, _, h, w = x.size()
x_pool_h, x_pool_w, x_pool_ch = self.pool_h(x), self.pool_w(x).permute(0, 1, 3, 2), self.gap(x)
x_pool_hw = torch.cat([x_pool_h, x_pool_w], dim=2)
x_pool_h, x_pool_w = torch.split(x_pool_hw, [h, w], dim=2)
x_pool_hw_weight = x_pool_hw.sigmoid()
x_pool_h_weight, x_pool_w_weight = torch.split(x_pool_hw_weight, [h, w], dim=2)
x_pool_h, x_pool_w = x_pool_h * x_pool_h_weight, x_pool_w * x_pool_w_weight
x_pool_ch = x_pool_ch * torch.mean(x_pool_hw_weight, dim=2, keepdim=True)
return x * x_pool_h.sigmoid() * x_pool_w.permute(0, 1, 3, 2).sigmoid() * x_pool_ch.sigmoid()
class MatchNeck(nn.Module):
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
self.MN = MatchNeck_Inner(c2)
def forward(self, x):
return x + self.MN(self.cv2(self.cv1(x))) if self.add else self.MN(self.cv2(self.cv1(x)))
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class LAE(nn.Module):
# Light-weight Adaptive Extraction
def __init__(self, ch, group=16) -> None:
super().__init__()
self.softmax = nn.Softmax(dim=-1)
self.attention = nn.Sequential(
nn.AvgPool2d(kernel_size=3, stride=1, padding=1),
Conv(ch, ch, k=1)
)
self.ds_conv = Conv(ch, ch * 4, k=3, s=2, g=(ch // group))
def forward(self, x):
# bs, ch, 2*h, 2*w => bs, ch, h, w, 4
att = rearrange(self.attention(x), 'bs ch (s1 h) (s2 w) -> bs ch h w (s1 s2)', s1=2, s2=2)
att = self.softmax(att)
# bs, 4 * ch, h, w => bs, ch, h, w, 4
x = rearrange(self.ds_conv(x), 'bs (s ch) h w -> bs ch h w s', s=4)
x = torch.sum(x * att, dim=-1)
return x
class MSFM(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1)
self.m = nn.ModuleList(MatchNeck(self.c, self.c, shortcut, g, k=(3, 3), e=1.0) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
if __name__ == '__main__':
x = torch.randn(4, 64, 128, 128).cuda()
# model = LAE(64).cuda()
model = MSFM(64, 64).cuda()
out = model(x)
print(out.shape)
'__main__':
x = torch.randn(4, 64, 128, 128).cuda()
# model = LAE(64).cuda()
model = MSFM(64, 64).cuda()
out = model(x)
print(out.shape)

















 2918
2918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









