







golang中提供了多种profile用于分析golang程序的CPU、内存等使用情况。heap profile是堆内存使用情况的profile信息,用于分析程序当前的堆内存使用情况,在分析内存开销和内存泄露问题时是一种有效的分析工具。
https://lrita.github.io/2017/05/26/golang-memory-pprof/介绍了heap profile的用法。https://golang.org/doc/diagnostics.html和https://golang.org/pkg/runtime/pprof/#WriteHeapProfile是golang官方对profiling的介绍和API。
生成profile的方式主要有两种:
1. 在程序中import "/net/http/pprof",并启动一个http server,之后就可以通过http://localhost/debug/pprof/来获取pprof性能分析的相关信息,包括profile。
2. 直接在代码中调用pprof.WriteHeapProfile将heap profile写入指定文件。
本文不具体讨论heap profile的使用和分析方法,而是分析heap profile的生成原理,便于真正理解heap profile输出的数据含义。
profile包含信息
首先要解决的问题是,heap profile中到底保存了什么信息?通过http://127.0.0.1:8080/debug/pprof/heap?debug=1可以看到debug版本的heap profile信息,可以看到包含两部分:
1. heap alloc调用栈
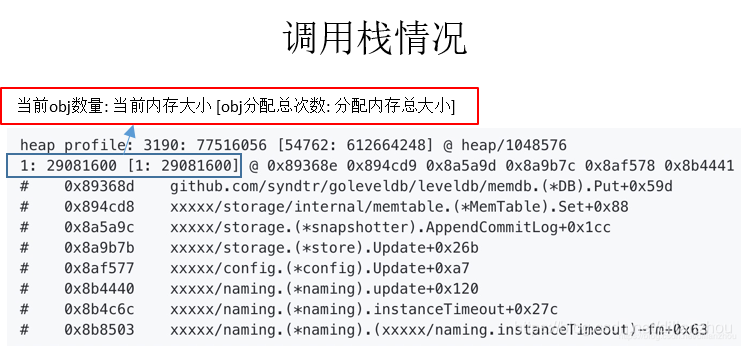
这部分是heap profile采集到的堆分配操作的代码调用栈,也是pprof后续分析的主要依据
2. 内存使用统计
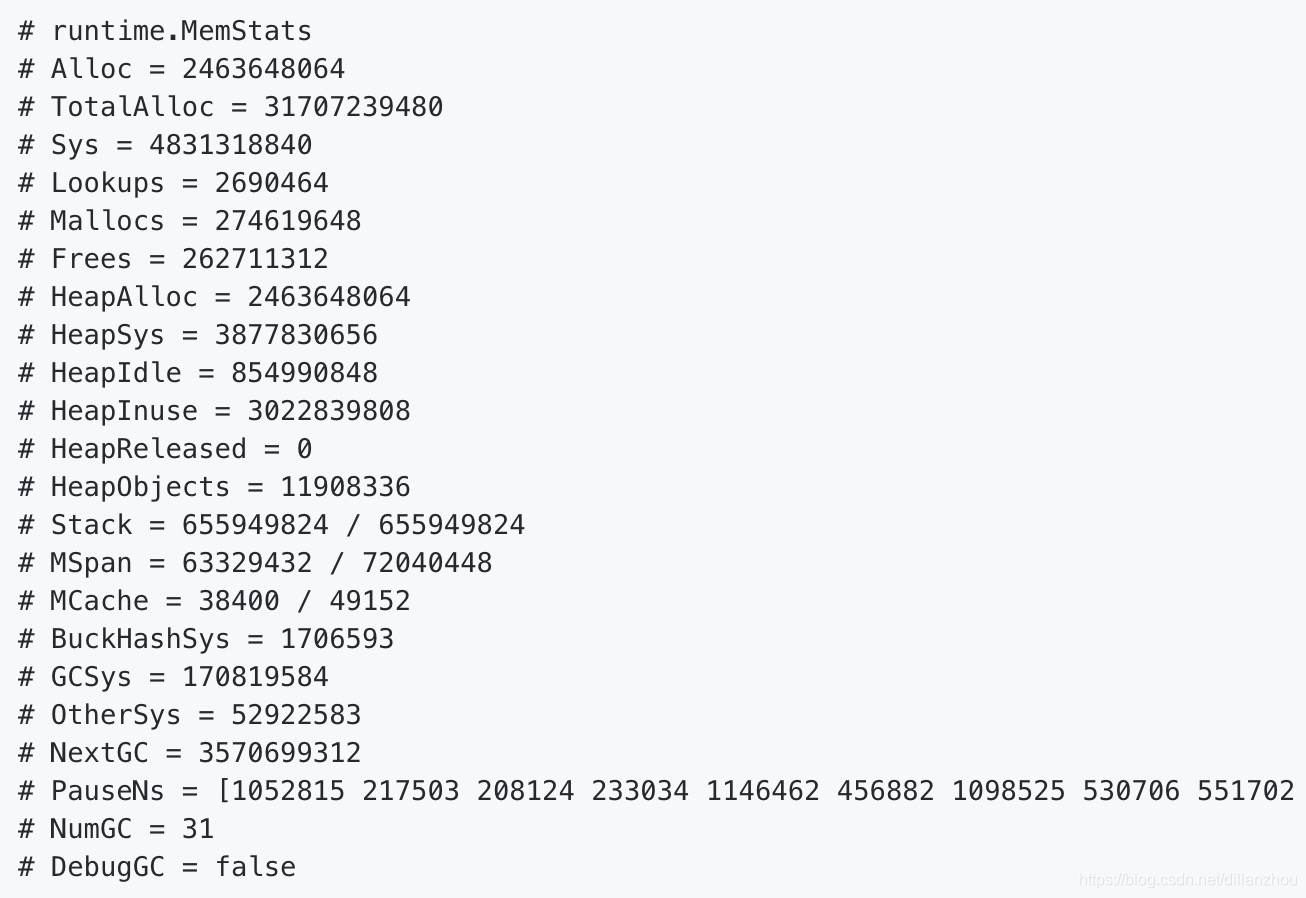
这部分是对内存分配和使用情况的一个整体统计
但如果需要输出供pprof工具分析的数据文件,其中是不包含第二部分统计值的,只包含第一部分堆分配调用栈。
使用pprof.WriteHeapProfile或http://127.0.0.1:8080/debug/pprof/heap方式生成的heap profile数据文件,是提供给pprof工具分析的,因此内容基本不可读。文件内容基本上就是堆分配调用栈信息的protobuf格式编码。通过pprof工具可以将结果展现成svg图:
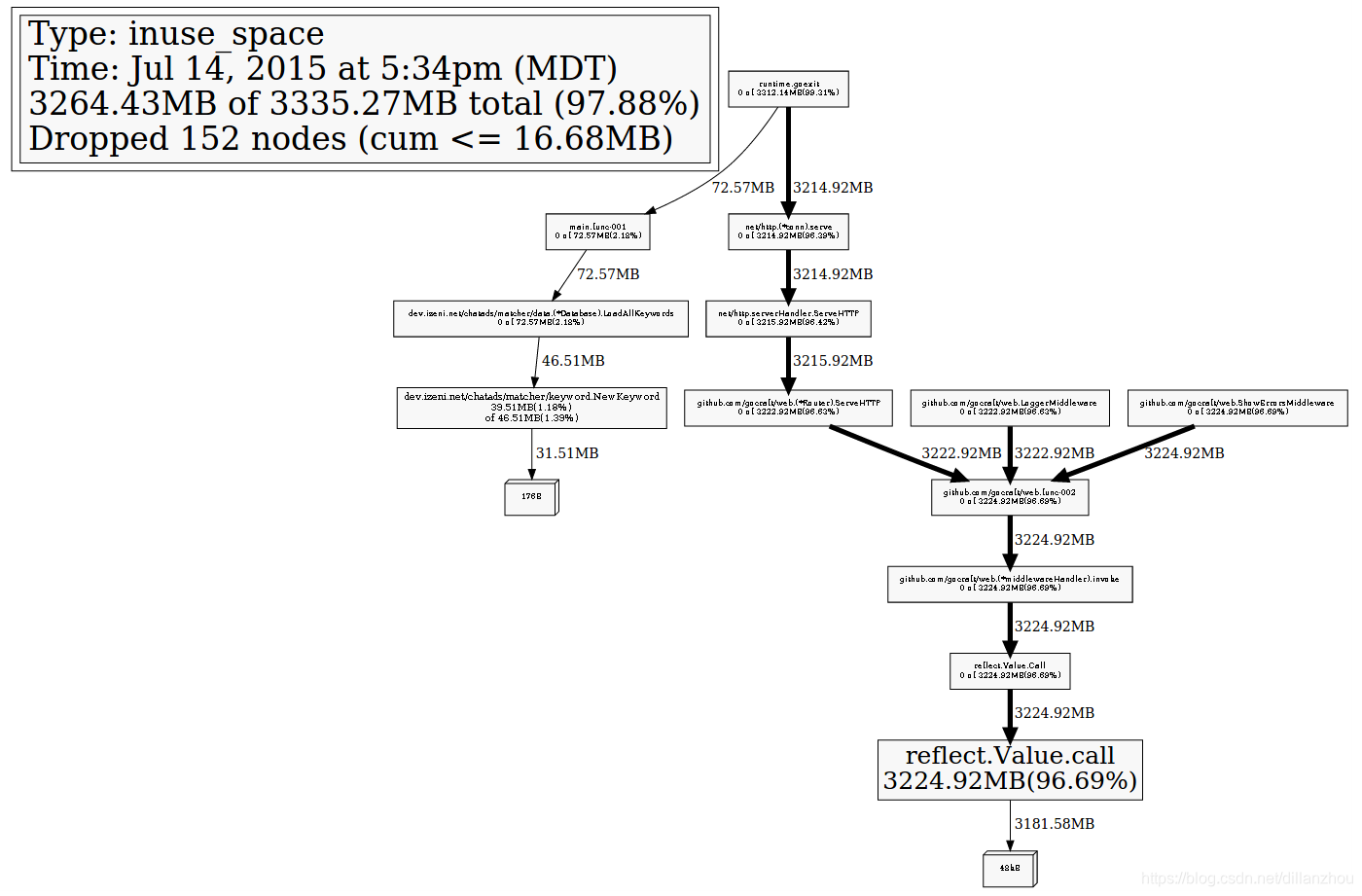
profile采集过程
在信息采集方面,需要回答两个问题:
1. 堆分配操作的调用栈信息是在什么时候获取的?
2. 调用栈信息是如何保存的?
首先,调用栈信息是在goruntime分配内存时采样获取的。golang的内存分配由go/src/runtime/malloc.go中的mallocgc函数实现,其中有这样一段代码:
if rate := MemProfileRate; rate > 0 {
if rate != 1 && int32(size) < c.next_sample {
c.next_sample -= int32(size)
} else {
mp := acquirem()
profilealloc(mp, x, size)
releasem(mp)
}
}
可以看到mallocgc会根据MemProfileRate配置值,来调用profilealloc记录当前的调用栈信息。具体逻辑为:
1. MemProfileRate<=0:不采样
2. MemProfileRate=1:每次分配都记录
2. MemProfileRate>1:每分配满若干字节采样一次。这里的若干字节不是一个严格固定的值,而是以MemProfileRate为均值的指数分布中随机取一个值。这是为了避免内存分配有固定的规律,如果严格按固定字节数采样,可能会每次都刚好采到特定类型的分配。
MemProfileRate的默认值为512*1024,即每分配512KB(近似),就采样一次。MemProfileRate的值可以通过GODEBUG="memprofilerate=xxx"来修改。
具体的采样工作在go/src/runtime/mprof.go的mProf_Malloc中实现:
// Called by malloc to record a profiled block.
func mProf_Malloc(p unsafe.Pointer, size uintptr) {
var stk [maxStack]uintptr
nstk := callers(4, stk[:])
lock(&proflock)
b := stkbucket(memProfile, size, stk[:nstk], true)
c := mProf.cycle
mp := b.mp()
mpc := &mp.future[(c+2)%uint32(len(mp.future))]
mpc.allocs++
mpc.alloc_bytes += size
unlock(&proflock)
// Setprofilebucket locks a bunch of other mutexes, so we call it outside of proflock.
// This reduces potential contention and chances of deadlocks.
// Since the object must be alive during call to mProf_Malloc,
// it's fine to do this non-atomically.
systemstack(func() {
setprofilebucket(p, b)
})
}具体采样逻辑如下:
1. 调用callers->gentraceback,获取调用栈的各层PC(指令地址)
2. 调用stkbucket记录调用栈。调用栈的记录方式简单的说,就是把相同的调用栈分配信息合并起来保存,而每个不同的调用栈都保存单独的PC数组,两个调用栈只要PC有一层不相等或分配的内存长度不同就认为是不同的。检索和保存调用栈的数据结构是哈希表,保存在全局数组buckhash *[179999]*bucket中。stkbucket根据当前调用栈PC数组和分配内存长度计算哈希值,在哈希表中查找或添加bucket项,每个bucket负责保存一个调用栈。bucket.next用于索引hash值相同的bucket链表。bucket.allnext则将所有memProfile类型的bucket都链在一起,便于遍历输出,表头为mbuckets。每个bucket之后会有连续空间保存PC数组,以及memRecord。
3. 将分配次数和分配大小记录到bucket的memRecord中,这里的memRecord包含一个数组,其中会记录3轮gc间的分配情况。只有当一轮gc完成时,memRecord才会将上一轮gc到这一轮gc间内存分配和释放的次数加入最终展示的次数中。这个设计是为了避免在gc执行前获取heap profile,会看到大量临时申请的空间,而且在一轮gc周期的不同时刻会看到不稳定的heap状态。
4. 调用setprofilebucket将bucket记录到此次分配地址相关的mspan上。用于后续记录内存释放信息。大体的逻辑是在gc释放内存时,会调用mspan.sweep->freespecial->mProf_Free来记录对应的内存释放情况。
profile输出过程
输出heap profile的接口有两个,分别是pprof.WriteHeapProfile和pprof.Lookup("heap").WriteTo(w, 0),后者是/net/http/pprof提供的http profile功能当前所使用的接口。从注释来看,pprof.WriteHeapProfile是早期的接口,为了兼容早期代码而保留了下来,golang核心代码中不再调用这个接口。两个接口的实现有一些区别,但最核心的输出逻辑是相同的,这里以pprof.WriteHeapProfile为例。
pprof.WriteHeapProfile是一个接口,在go 1.12中,其实现是writeHeapInternal函数。
writeHeapInternal有一个debug参数,如果debug==true,则会输出前文介绍的可读调用栈和统计信息。这里重点分析debug==false的情况,也是调用pprof.WriteHeapProfile时的情况。
具体逻辑如下:
1. 调用runtime.MemProfile将保存在bucket中的信息提取转换到[]runtime.MemProfileRecord数组中,每个MemProfileRecord对应一个有效的bucket(这里的有效主要根据bucket分配的内存是否已全部释放等条件判断),包括相关调用栈信息以及内存分配释放的次数和大小。
2. 调用writeHeapProto将信息输出到文件。在这个函数中,会逐个遍历[]runtime.MemProfileRecord数组,逐个输出调用栈信息。
处理单个MemProfileRecord的逻辑为:
1. 遍历调用栈PC,使用runtime.FuncForPC(addr).Name()获得PC指针对应的函数名,如果是"runtime."开始的函数直接跳过不输出信息,因此最终输出的调用栈是不包含goruntime内部栈的。因为这部分栈对于分析heap没有意义,绝大部分情况下是一样的,包含了heap profile功能本身的栈。
2. 对于非goruntime内部函数,调用*profileBuilder.locForPC返回一个唯一ID。也就是说最终输出的调用栈不是用PC地址表示的,而是这个ID,每个不同的ID对应一个不同的函数调用位置。
3. 估算当前调用栈分配的内存大小。根据之前介绍的逻辑,bucket中保存的只是采样数据,而不是完整的内存分配信息,那么如何获得调用栈真正分配的内存大小呢?这里调用了scaleHeapSample,根据分配的单块内存大小以及采样分布,来估算出真正分配的内存量。因此我们最终在输出数据中看到的内存分配量是一个估算总值,而不是采样值总和。
4. 将调用栈、估算的分配量、单块内存大小这些信息使用protobuf编码后输出到文件。
这里还有一个问题:在生成的heap profile文件中,我们保存的调用栈信息是用id表示的,而heap profile文件可以在没有执行文件的情况下提供调用栈的函数名称,可见heap profile中保存了调用栈函数名以及与id的对应关系。这个信息是在*profileBuilder.locForPC中产生和输出的,大体过程如下:
1. 根据PC地址获取调用栈信息
2. profileBuilder.locs是一个从PC地址到locationID的map,如果当前PC不在map中,则继续执行下面步骤
3. 调用runtime.CallersFrames获取调用栈函数信息
4. 将当前PC加入locs中,新的locationId为len(locs)+1,可见id是顺序增加的
5. 逐层处理调用栈函数。profileBuilder.funcs是一个从函数名到funcID的map,如果当前函数名不在map中,则将其加入并产生新的funcID
6. 记录locationID、PC地址,以及每层调用栈函数的funcID、代码行数,输出到文件
7. 将新遇到的函数的funcID、函数名、所处文件名记录到文件中。这里记录的其实还不是最终的函数名、文件名字符串,而是profileBuilder.stringIndex返回的一个哈希值,这样可以将相同的函数名只保存一份,减少最终输出文件的大小。
根据输出的这些信息,pprof工具就能够还原出每层调用栈的函数信息了,索引关系为:locationID->funcID->函数名/文件名
总结
本文较详细的分析了golang的heap profile的采集生成原理,其实其中大部分逻辑对其他profile也是通用的。goruntime通过采样方式记录了部分内存分配操作的调用栈等信息,在输出时根据采样模型估算实际分配情况,并将调用栈信息输出到文件中。
值得一提的是,heap profile常用于分析内存泄漏问题,可以从profile中获取占用内存过多的对象类型,以及其分配的位置。但很多情况下根据这些信息还不能直接分析出内存泄漏的根本原因。这时可以结合gcore和viewcore工具,从coredump中分析出泄漏内存对象的引用关系,找出这些内存不能被gc回收的根本原因。

















 1437
1437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









