









该爬虫主要用到了scrapy框架. 通过此例子大家可以熟悉下scrapy的流程:
-
由于该网站是通过js处理的,在spidertieba.py中,通过response.xpath(’//li[@class=" j_thread_list clearfix"]’)解析字段信息, 始终没法抓取到数据.
-
如何抓取到数据是关键, 就想到了用scrapy + selenium 进行动态加载页面的内容爬取。
在middlewares.py中,使用了 selenium+chromedriver使chrome无界面化. 当然大家可以选择PhantomJS + 火狐都可以, PhantomJS已经停止更新了, 谷歌浏览器支持力度最大,建议用chrome -
在DownloaderMiddleware中,主要是通过该函数 def process_request(self, request,
spider):来模拟浏览器发送请求. -
至于为什么要放到中间件DownloaderMiddleware中处理,大家可以看下scrapy架构图。
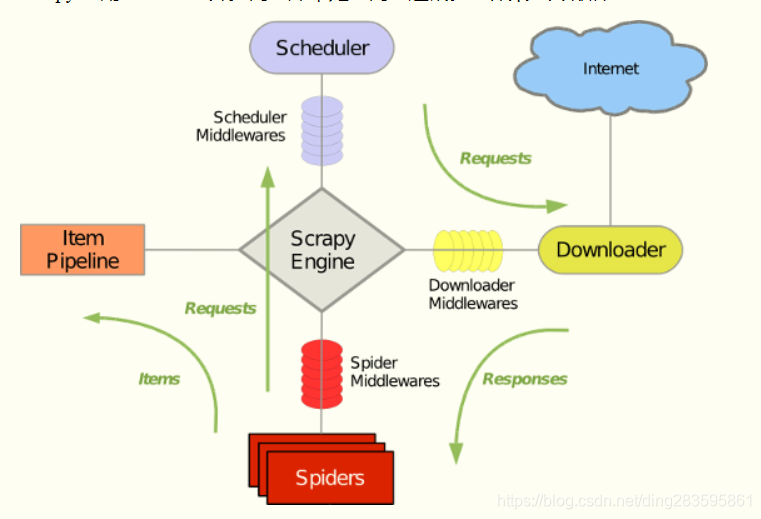
-
在settings.py中,需要把DOWNLOADER_MIDDLEWARES 和ITEM_PIPELINES打开。
spidertieba.py:用于请求数据并解析数据,然后保存到item中
items.py: 创建要保存的字段信息
middlewares.py: 用selenium+chromedriver模拟谷歌浏览器发送请求.目的就是进行动态加载页面,方便spidertieba.py中通过xpath解析数据
pipelines.py: 创建文件& 保存item数据, 例子中是以json格式保存数据
settings.py:配置信息, 需要把DOWNLOADER_MIDDLEWARES 和ITEM_PIPELINES打开
运行scrapy crawl spidertieba
最终会保存tieba.json文件
大家可以下载源码:
https://download.csdn.net/download/ding283595861/11708840
需要修改一个地方:在middlewares.py中,需要把第一个参数改成 你们自己本地的路径:
self.driverwebdriver.Chrome(r’D:\*****\chromedriver_win32\chromedriver.exe’,options=chrome_options)














 1592
1592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









