







- 本文旨在介绍 torch 模型研发 的整体流程, 对数据加载、建模的过程没有深究细节;
- 此外包含了一些 损失函数、优化器函数 的延申阅读(1.2节),可起到简单的“查函数”的作用
torch开发深度学习模型的简要流程
1. 速览
1.1 深度学习开发的一般流程
这里的 深度学习开发 是指 模型研发,不包括工程化落地的部分(比如 转onnx、模型集成 等后续工作不在本文的介绍范围之内)。
1.1.1 流程简述
模型开发的一般过程可大致分为如下步骤:
-
step1: 数据
收集数据、数据加载函数 -
step2: 建模
搭建神经网络结构:①继承;②初始化时创建层;③重写forword。 -
step3: 训练 & 模型参数保存
选好优化器类型、学习率;设计损失函数;保存模型参数;训练过程追踪。 -
step4: 模型参数加载 & 测试
加载模型参数;测试该模型参数的效果;分析badcase。
1.1.2 流程详述
-
step1: 数据
– step1.1: 收集数据
(a) 来源:各种官方数据集、用户提供的数据集、自己采集、爬虫(慎用😁);
(b) 划分训练集&测试集:在模型验证阶段需要划分测试集用于验证模型效果(比如可以采用7:3的比例划分),在最终成品阶段如果期待进一步提高模型效果,可以采用全集重新训练,或者在现有参数基础上 以较小的学习率在测试集上训练(不一定真的提高哦)。
– step1.2: 数据加载
主要考虑加载一个batch的数据,也就是如何加载 一次迭代训练 用到的一批数据(包括输入张量&输出标签)。 -
step2: 建模
也就是搭建神经网络结构。
在pytorch中:
①需要继承Module类;
②在初始化时创建大量 神经网络层对象;
③重写forword函数,也就是编写正向传播过程。 -
step3: 训练 & 模型参数保存
– (a) 核心步骤
① 选好优化器类型、学习率:优化器就是迭代模型参数的工具,其原理来自于工程优化(如梯度下降算法)以及 链式求导(反向传播过程);
② 设计损失函数:损失函数也就是优化目标,即工程优化中构造有最小值的最优化目标;
③ 定期地保存训练过程中的模型参数:这个“期”值得探讨,可以每隔固定的迭代次数保存一次模型参数,也可以每个epoch(完整跑完一遍训练集数据称为一个epoch)保存一遍模型参数,也可以根据训练过程的loss(小于某阈值)、acc(大于某阈值)保存模型参数。
– (b) 训练过程追踪
方便我们观察模型参数的收敛情况:
① loss是否呈现明显的下降趋势(或 acc 呈现明显地上升趋势);
② 模型是否已经收敛,是否可以终止训练了,又或者需要增加训练轮数。 -
step4: 模型参数加载 & 测试
① 可以直接测试 训练得到的最终的模型(也就是最后一轮训练结束得到的模型);
② 更常用的是,我们加载训练过程中保存的某个模型参数,然后测试该模型参数的效果;
③ 保存测试结果(负例的输入、标签、模型输出),以便分析模型犯错的特点,进而给出模型改进的方向。
1.2 初识torch关键类和函数(含大量延申阅读)
1.2.1 建模 & 模型层信息
(1) 继承 torch.nn.Module;重写 init()、forward(x)
(2) 常用的 激活函数 & 损失函数 在 torch.nn.functional. 下 或者 torch.nn. 下
- 延申阅读:PyTorch的十八个损失函数
(3) 模型层信息: mdl.named_parameters()
详见2.2节的show_model() 函数,包含:层名、张量形状、是否可训练、驱动信息(cpu|cuda|…) 的打印
1.2.2 优化器 & 迭代
(1)创建优化器: torch.optim. 下有各种常用的优化器
- 延申阅读:Pytorch 30种优化器总结
(2)一次迭代优化
optimizer.zero_grad() # 梯度清空
loss.backward() # 反向传播
optimizer.step() # 优化模型参数
1.2.3 模型保存 & 加载
(1)关键函数: torch.save()、torch.load()
(2)保存&加载 模型整体
torch.save(model, save_path_str)
model = torch.load(save_path_str)
(3)保存&加载 模型参数
torch.save(model.state_dict(), save_path_str)
model.load_state_dict( torch.load(save_path_str) )
2. 举例:手写数字识别(含代码)
2.1 任务&模型简介
手写数字识别是一个非常经典的任务,以现在的眼光看似乎十分简单,但这正适合作为入门教材。
(1)输入
输入是 12828 的张量, 实际上是一张小图片,也就是一个手写数字。
(2)输出
输出目标是 0,1, … ,9 中的一个数字。
(3)模型结构
模型结构非常简单,将输入展平为向量,通过三层全连接层得到输出向量 (输出向量维度为10, 也就是一个类别向量,以 onehot 编码作为优化目标)
(4)优化相关
① 本文在输出层上 - 甚至没采用softmax函数来作为最终输出概率向量的函数;
② 本文在损失函数上 - 没有采用 交叉熵损失函数CrossEntropyLoss作为损失函数,而是简单采用 均方差损失函数mse_loss;
③ 本文在优化器上 - 直接采用了梯度下降优化器SGD
虽然文章采用的神经网络结构相当落后,但损失的下降过程还是非常明显的,且3个epoch 的正确率在95%左右。说明这个模型对该任务是“适配”的,似乎是因为这个任务比较“纯粹”(毕竟只有手写数字数据集,业务范围相当狭窄),当然如果采用卷积神经网络处理图像分类应该会有更好的效果。
2.2 代码
#%% global params
# 1. 模型参数
class_n = 10
pic_w = 28
pic_h = 28
pic_flat = pic_w*pic_h
# 2. 训练参数
epoch_num = 3
batch_size_train = 64
learn_rate = 0.01
momentum = 0.9
show_train_step = 10
save_mdl_param_path = "./output/model_param/<tag>/model_param_dict.bin"
save_loss_pic_path = "./output/model_param/loss.jpeg"
# 3. 测试参数
batch_size_test = 100
show_test_step = 10
save_badcase_path = "./output/bad_case/<tag>/badcase.txt"
save_acc_path = "./output/bad_case/<tag>/acc.txt"
test_epc_num = 1 # 0,1,2 即 [0,epoch_num)
badcase_show_id = 0
save_badcase_pic_path = "./output/bad_case/<tag>/badcase_"+str(badcase_show_id)+".jpeg"
# 4. 硬件调用参数
device = "cuda"
#%% import
import os
import numpy as np
import torch
import torchvision
from matplotlib import pyplot as plt
#%% com func - 1. dir
def make_dir_by_tag(org_path, tag):
base_folder, file_name = org_path.split("<tag>")
save_folder = base_folder + str(tag)
save_path = save_folder + file_name
if not os.path.exists(save_folder):
os.makedirs(save_folder)
return save_path
#%% work func - 1. func: data loader
def get_dataLoader_by_batchSize(batch_size):
return torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
def one_hot(y, class_n=class_n):
batch_size = y.size(0)
ret = torch.zeros((batch_size, class_n))
for i in range(batch_size):
class_idx = y[i]
ret[i][class_idx] = 1
return ret
#%% work func - 2. class: model
class MyFirstModel(torch.nn.Module):
def __init__(self):
super(MyFirstModel, self).__init__()
# 核心网络层
self.fc1 = torch.nn.Linear(pic_flat, 256)
self.fc2 = torch.nn.Linear(256,64)
self.fc3 = torch.nn.Linear(64,10)
def forward(self, x):
"""正向传播"""
x = self.fc1(x)
x = torch.nn.functional.relu(x) # 激活函数层
x = self.fc2(x)
x = torch.nn.functional.relu(x) # 激活函数层
x = self.fc3(x)
return x
def show_model(mdl, msg = ""):
print("-"*15)
print(msg, "| model params:")
model_params = mdl.named_parameters()
for name,param in model_params:
print(
"name:",name,
"| shape:", param.size(),
"| requires_grad:", param.requires_grad,
"| device:",param.device
)
print("-"*15)
#%% work func - 3. train func
def save_model_by_epcNum(mdl, epc_num):
torch.save(
mdl.state_dict(),
make_dir_by_tag(save_mdl_param_path, "epc_" + str(epc_num) )
)
def trainning():
ret_trainLoss = []
train_data_loader = get_dataLoader_by_batchSize(batch_size_train)
mdl = MyFirstModel().to(device)
show_model(mdl, "trainning")
optimizer = torch.optim.SGD(mdl.parameters(), lr=learn_rate, momentum=momentum)
for epc in range(epoch_num):
for batch_idx, (x, y) in enumerate(train_data_loader):
x = x.view(x.size(0), pic_flat).to(device)
y = one_hot(y).to(device)
pred_y = mdl(x)
loss = torch.nn.functional.mse_loss(y, pred_y).to(device)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 训练过程 打印
if batch_idx % show_train_step == 0:
print("epc:",epc, ", step:",batch_idx, "| loss:",loss.item())
ret_trainLoss += [loss.item()]
# 保存每个 epoch 的 模型参数
save_model_by_epcNum(mdl, epc)
return mdl, ret_trainLoss
def show_loss(loss_list):
plt.figure()
plt.plot(range(len(loss_list)), loss_list)
# plt.show()
if save_loss_pic_path:
plt.savefig(save_loss_pic_path)
# work func - 4. test func
def save_one_badcase(x, y_tag, y_pred, save_tag):
f = open(
make_dir_by_tag(save_badcase_path, str(save_tag) ),
'a',
encoding="utf8"
)
f.write(
"x:"+str(x)
+ "\ttag:" + str(y_tag)
+ "\tpred:" + str(y_pred)
+ "\n"
)
f.close()
def save_one_acc(acc, acc_msg, save_tag):
f = open(
make_dir_by_tag(save_acc_path, str(save_tag) ),
'a',
encoding="utf8"
)
f.write("acc:"+str(acc) + " ("+acc_msg+")" + "\n")
f.close()
def testing(mdl, model_tag:str):
print("="*20)
print("start testing ...")
show_model(mdl, "testing")
ret_acc = "null"
ret_acc_n = ""
ret_bad = {
"x": [],
"y_tag": [],
"y_pred": []
}
total_n = 0
pred_right_n = 0
test_data_loader = get_dataLoader_by_batchSize(batch_size_test)
for batch_idx, (x, y) in enumerate(test_data_loader):
x_org = x.to(device)
x = x.view(x.size(0), pic_flat).to(device)
pred_y = mdl(x)
pred_classID = pred_y.argmax(dim=1).to(device)
for i in range(batch_size_test):
total_n += 1
if y[i] == pred_classID[i]:
pred_right_n += 1
else:
# 保存 预测错误的数据
bad_x = x_org[i][0].cpu().detach().numpy()
bad_y_tag = y[i].item()
bad_y_pred = pred_classID[i].item()
ret_bad["x"] += [bad_x]
ret_bad["y_tag"] += [bad_y_tag]
ret_bad["y_pred"] += [bad_y_pred]
save_one_badcase(bad_x, bad_y_tag, bad_y_pred, model_tag)
# 测试过程打印
if batch_idx%show_test_step == 0:
print(str(batch_idx)+",", end="")
print()
ret_acc = pred_right_n/total_n if total_n else "null"
ret_acc_n = str(pred_right_n) + "/" + str(total_n)
save_one_acc(ret_acc, ret_acc_n, model_tag)
return ret_acc, ret_acc_n, ret_bad
def show_test_bad(tesd_bad_dict, idx, save_tag):
print("="*20)
print("start show_test_bad()")
if "x" not in tesd_bad_dict or len(tesd_bad_dict["x"]) == 0:
print("warn | show_test_bad() | tesd_bad_dict is empty !")
return
x = tesd_bad_dict["x"][idx]
y_tag = tesd_bad_dict["y_tag"][idx]
y_pred = tesd_bad_dict["y_pred"][idx]
print("x.shape:", x.shape)
print("tag:",y_tag)
print("pred:",y_pred)
plt.figure()
plt.imshow(x)
plt.title("tag:"+str(y_tag)+"\n"+"pred:"+str(y_pred))
# plt.show()
if save_badcase_pic_path:
plt.savefig( make_dir_by_tag(save_badcase_pic_path, save_tag) )
# work func - 5. load model
def load_model_by_epcNum(epc_num):
mdl = MyFirstModel().to(device)
mdl.load_state_dict(
torch.load(
make_dir_by_tag(save_mdl_param_path, "epc_" + str(epc_num) )
)
)
return mdl
#%% run demo
def run_demo1_train_and_test():
# 1. 模型训练
model, loss_list = trainning()
show_loss(loss_list)
# 2. 训练的最终结果测试
acc, acc_msg, badcase = testing(model, "final_model")
print("final model ( epc",epoch_num-1,") | acc:",acc,"("+acc_msg+")")
show_test_bad(badcase, badcase_show_id, "final_model") # 展示第一个badcase
def run_demo2_load_and_test(epc_num):
if epc_num >= epoch_num:
print("error | epoch num:",epc_num," - out of max epoch_num:",epoch_num-1)
return
# 1. 通过 训练过程中 保存的模型参数 重新加载模型
model = load_model_by_epcNum(epc_num)
# 2. 测试模型
save_tag = "epc_"+str(epc_num)
acc, acc_msg, badcase = testing(model, save_tag)
print("epc",epc_num,"| acc:",acc,"("+acc_msg+")")
show_test_bad(badcase, badcase_show_id, save_tag) # 展示第一个badcase
#%% main
if __name__ == "__main__":
print("start testing...")
# 1. 训练 & 测试
run_demo1_train_and_test()
# 2. 加载 & 测试
run_demo2_load_and_test(test_epc_num)
3. 执行说明
3.1 关于 MNIST 数据集
(1)首次执行 会下载 MNIST手写数字数据集
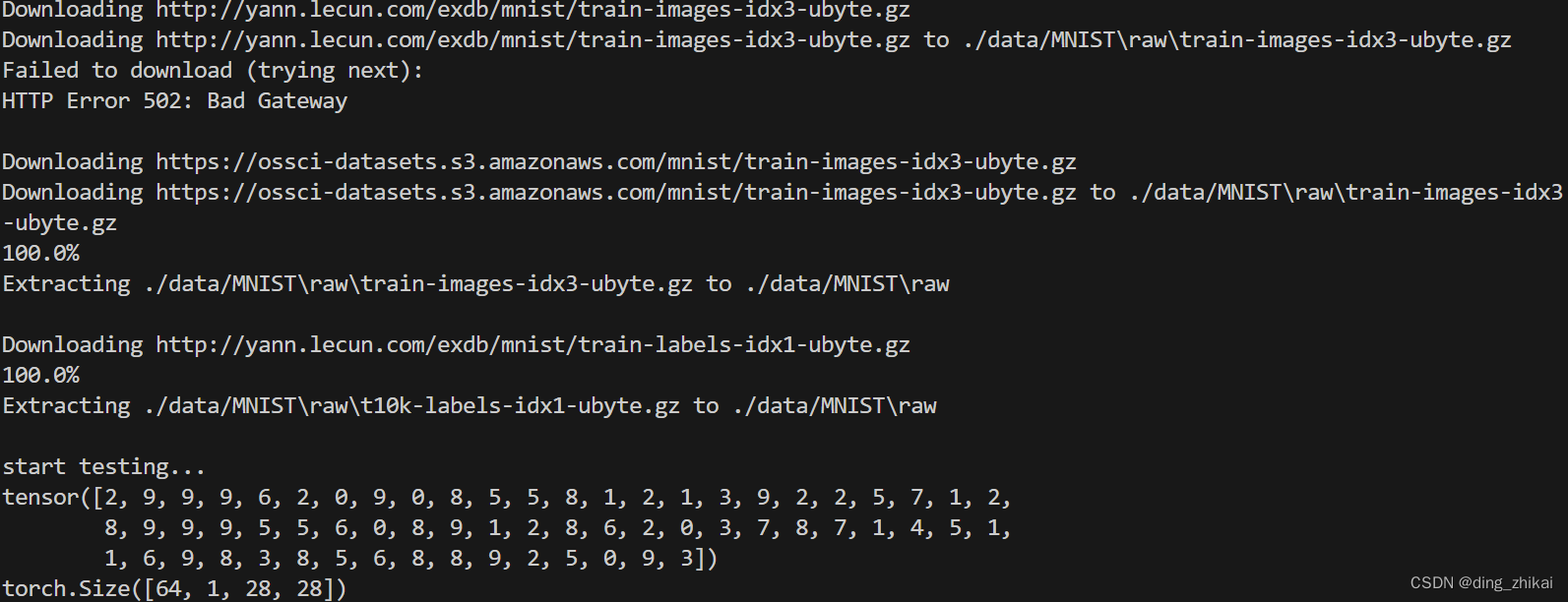
- 可以在 vscode右侧的 资源管理器 里面看到 下载的数据
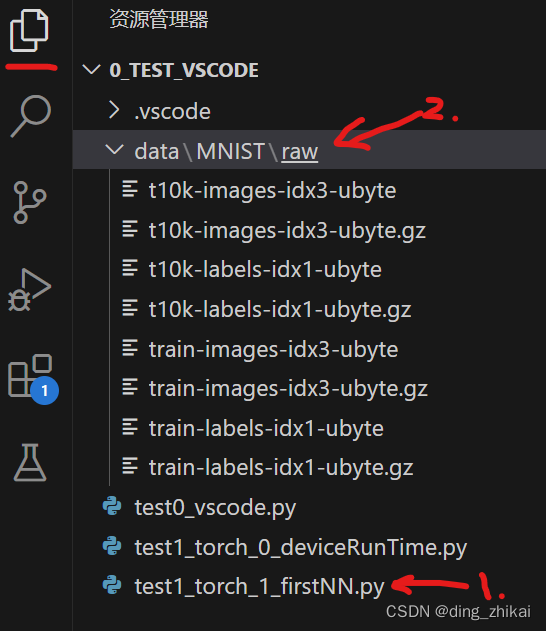
图中 1是源码位置;
图中 2是下载到 源码同级的位置 的数据, 同级是因为代码里面写的相对路径(如下图),意味着会保存到执行程序同级下的data文件夹中:
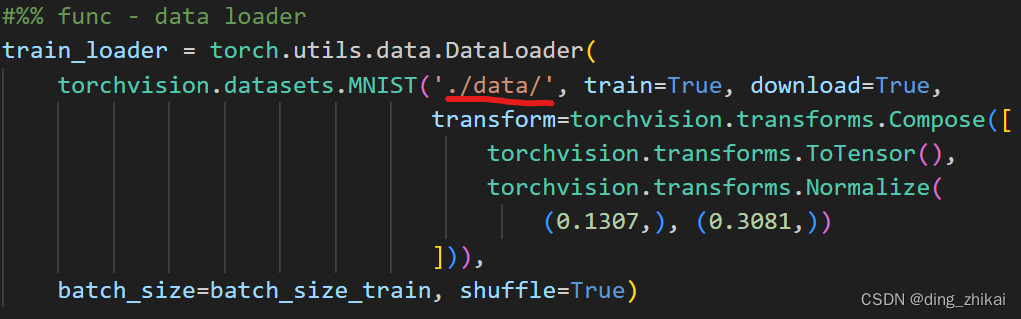
(2)后续执行会从本地直接加载数据

3.2 产物
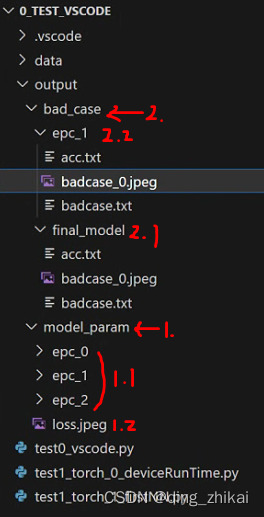
① 产物都放在 output 中
② 训练过程中生成 ./output/model_param/ 文件夹及内容,保存了模型参数(每个epoch 保存一次),训练完后会画损失曲线并保存为./output/model_param/loss.jpeg
③ 测试过程中 生成 ./output/badcase/ 文件夹及内容,保存了: acc、测试中所有错误预测的例子、第一个badcase的可视化图片
- 注:
a) ./output/badcase/final_model是训练完成后的模型的测试结果,相当于./output/model_param/epc_2的模型参数的测试结果;
b) ./output/badcase/epc_1 顾名思义,相当于./output/model_param/epc_1的模型参数的测试结果;















 1968
1968











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









