







在uvmlab3中,将SV环境移植到UVM的重点如下:
- TLM的单向、多向通信端口的使用
- TLM的通信管道
- UVM的回调类型 uvm_callback
- UVM的一些仿真控制函数
TLM单向、多向通信
知识回顾
1、何为事务级、何为事务级通信(TLM)?有什么用?
事务级:所谓transaction level是相对DUT中各个模块之间信号线级别的通信来说的。 简单来说, 一个transaction就是把具有某一特定功能的一组信息封装在一起而成为的一个类。
事务级通信(TLM):是一种在较高抽象级别上对任何系统或设计进行建模的方法。 在TLM中,使用事务对不同模块之间的通信进行建模,从而抽象出所有底层实现细节。 这是验证方法中用于提高模块化和重用性的主要概念之一。 即使DUT的实际接口由信号级别的活动表示,但大多数验证任务(如生成激励,功能检查,收集覆盖率数据等)都可以在事务级别上更好地完成,只要使它们独立于实际信号级别的细节即可 。 这有助于在项目内部和项目之间重用和更好地维护这些组件
作用:
- TLM端口是提高数据通信抽象级的必要条件,同时使得组件之间的通信频率下降,提高了整体的仿真效率。失去标准化的TLM通信,那么就算UVM环境构建好,也无法完成高效的仿真任务
- 通信函数可以定制化,比如可以定制get()、peek()、put()的内容和参数,比mailbox通信更加灵活。
- 降低组件之间的依赖性;降低组件和环境的耦合度。
- 例子:只有端口类型为port(也就是initiator)的才需要通过端口宏声明去解决方法名的冲突问题,port端口则不需要如此操作。也就是initiator一端不用去关心谁会和它连接,和它连接的有几个端口,只需要正常声明、例化端口即可,方法名用put/get/peek就行,不需要加后缀。而这些需要修改的部分在target一端进行即可。(下文会提到)
- 标准化的TLM通信为UVM和其他验证方法混合使用提供了统一对话的基础
2、何为单向、多向?
单向:指从initiator到target的数据流向是单一方向的,或者说initiator和target只能扮演producer和consumer中的一个角色。
多向:注意,多向通信仍是两个组件之间的通信,指如果initiator与target之间的相同TLM端口数目超过1个的情况。比如下图组件1和组件2分别有两个uvm_blocking_put_port和uvm_blocking_put_imp端口。虽然我们可以给端口例化不同的名字,连接也可以通过不同名字来索引,但是端口对应的task名都是put,会产生冲突。
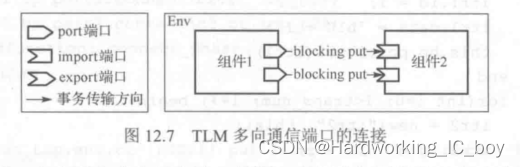
通过端口宏声明可以解决上述问题,即让不同端口对应不同名的任务,来解决方法名的冲突问题。
下面这段例码就通过宏来解决多个同类端口连接到同一个target的问题:
//解决target一端方法名冲突的几个要点
//端口宏声明
`uvm_blocking_put_imp_deck(_p1)
`uvm_blocking_put_imp_deck(_p2)
//端口声明
uvm_blocking_put_imp_p1 #(type, comp2) bp_imp_p1;
uvm_blocking_put_imp_p2 #(type, comp2) bp_imp_p2;
//端口例化
function new(string name, uvm_component parent);
super.new(name, parent);
bt_imp_p1 = new("bt_imp_p1", this);
bt_imp_p2 = new("bt_imp_p2", this);
……
endfunction
//不同名put任务的定义
task put_p1(itrans t);
……
key.put();
endtask
task put_p2(itrans t);
……
key.put();
endtask
注意,只有端口类型为imp(也就是imp类型只能是target)的才需要通过端口宏声明来解决方法名冲突的问题,而port则不需要关注方法名字,直接还用put就行。这也体现了TLM通信的优势之一——降低组件之间的耦合度。也就是initiator一端不用去关心谁将会和它连接,有几个端口,只要正常地声明、例化端口即可,方法就用put\get\peek等就行,不用加后缀。而这些需要修改的部分只在target端进行即可。
假设我们在initiator这边的端口也将方法名设置为put_p1等有后缀的,那么一来会报错,二来下次你连接的target只要一个端口,那么你到时又需要修改。这就是耦合度高了,不利于维护。
TLM通信步骤
- 搞清楚控制流和数据流——分辨initiator(通信发起端)和target(通信接收方),producer(数据流出方)和consumer(数据流入方);
- 在target中实现TLM通信方法,以方便initiator调用target中的通信方法实现数据传输;
- 在两个对象中创建TLM端口;
- 在更高层次中将两个对象的端口进行连接。一般做法及注意事项如下:
- 声明port和export端口,只需要指定transaction参数类型。而声明imp端口,则需要同时指定transaction参数类型以及所在的component类型。因为端口只是作为通信的管道,最终的操作还是要落实到component上,所以需要指定所在的component类型;.
- 在initiator端例化port,在中间层次例化export,在target端例化imp;
实验
之前的monitor到checker的通信,以及checker与refmod的通信都是通过mailbox以及在上层进行句柄传递实现的。接下来我们将采用TLM端口进行通信。
如图1所示,我们将在monitor、checker和refmod上添加若干TLM的通信端口,完成下列要求:
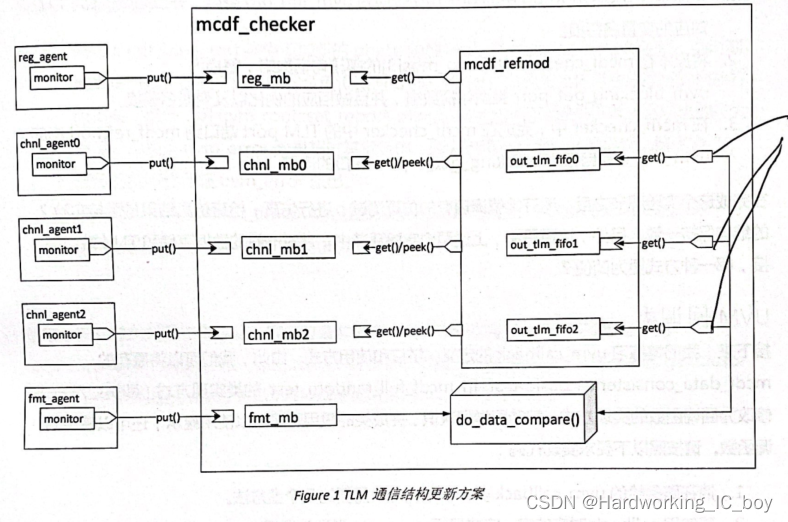
1、将monitor中的用来与checker中的mailbox通信的mon_mb句柄替换为对应的uvm_blocking_put_port类型。
以chnl_monitor为例。
// mailbox #(mon_data_t) mon_mb;
uvm_blocking_put_port #(mon_data_t) mon_bp_port;
2、在checker中声明与monitor通信的import端口类型,以及reference model通信的import端口类型。由于checker与多个monitor以及reference model通信(数据从多个组件流入checker),是典型的多方向通信类型,因此需要使用多端口通信的宏声明方法。在使用了宏声明端口类型之后,再在checker中声明其句柄,并且完成例化。
//宏声明
`uvm_blocking_put_imp_decl(_chnl0)
`uvm_blocking_put_imp_decl(_chnl1)
`uvm_blocking_put_imp_decl(_chnl2)
`uvm_blocking_put_imp_decl(_fmt)
`uvm_blocking_put_imp_decl(_reg)
`uvm_blocking_get_peek_imp_decl(_chnl0)
`uvm_blocking_get_peek_imp_decl(_chnl1)
`uvm_blocking_get_peek_imp_decl(_chnl2)
`uvm_blocking_get_imp_decl(_reg)
//句柄声明
uvm_blocking_put_imp_chnl0 #(mon_data_t, this) chnl0_bp_imp;
uvm_blocking_put_imp_chnl1 #(mon_data_t, this) chnl1_bp_imp;
uvm_blocking_put_imp_chnl2 #(mon_data_t, this) chnl2_bp_imp;
uvm_blocking_put_imp_fmt #(fmt_trans, this) fmt_bp_imp;
uvm_blocking_put_imp_reg #(reg_trans, this) reg_bp_imp;
uvm_blocking_get_peek_imp_chnl0 #(mon_data_t, this) chnl0_bgpk_imp;
uvm_blocking_get_peek_imp_chnl1 #(mon_data_t, this) chnl1_bgpk_imp;
uvm_blocking_get_peek_imp_chnl2 #(mon_data_t, this) chnl2_bgpk_imp;
uvm_blocking_get_imp_reg #(reg_trans, this) reg_bg_imp;
//例化
chnl0_bp_imp = new("chnl0_bp_imp", this);
chnl1_bp_imp = new("chnl1_bp_imp", this);
chnl2_bp_imp = new("chnl2_bp_imp", this);
fmt_bp_imp = new("fmt_bp_imp", this);
reg_bp_imp = new("reg_bp_imp", this);
chnl0_bgpk_imp = new("chnl0_bgpk_imp", this);
chnl1_bgpk_imp = new("chnl1_bgpk_imp", this);
chnl2_bgpk_imp = new("chnl2_bgpk_imp", this);
reg_bg_imp = new("reg_bg_imp", this);
3、根据声明的import端口类型,实现其对应的方法。
//put
task put_chnl0(mon_data_t t);
chnl_mbs[0].put(t);
endtask
task put_chnl1(mon_data_t t);
chnl_mbs[1].put(t);
endtask
task put_chnl2(mon_data_t t);
chnl_mbs[2].put(t);
endtask
task put_fmt(fmt_trans t);
fmt_mb.put(t);
endtask
task put_reg(reg_trans t);
reg_mb.put(t);
endtask
//peek、get
task peek_chnl0(output mon_data_t t);
chnl_mbs[0].put(t);
endtask
task peek_chnl1(output mon_data_t t);
chnl_mbs[1].put(t);
endtask
task peek_chnl2(output mon_data_t t);
chnl_mbs[2].put(t);
endtask
task get_chnl0(output mon_data_t t);
chnl_mbs[0].get(t);
endtask
task get_chnl1(output mon_data_t t);
chnl_mbs[1].get(t);
endtask
task get_chnl2(output mon_data_t t);
chnl_mbs[2].get(t);
endtask
task get_reg(output reg_trans t);
reg_mb.get(t);
endtask
4、根据图1,继续在mcdf_refmod中声明用来与mcdf_checker中的import连接的端口,并且完成例化。同时注意其端口类型的区别。
//声明端口
// mailbox #(reg_trans) reg_mb;
// mailbox #(mon_data_t) in_mbs[3];
uvm_blocking_get_port #(reg_trans) reg_bg_port;
uvm_blocking_get_peek_port #(mon_data_t) in_bgpk_ports[3];
//例化
reg_bg_port = new("reg_bg_port", this);
foreach(in_bgpk_ports[i]) in_bgpk_ports[i] = new(sformatf("in_bgpk_ports[%0d]",i),this);
5、在mcdf_env的connect_phase()阶段,完成monitor的TLM port 与mcdf_checker TLM import的连接
chnl_agts[0].monitor.mon_bp_port.connect(chker.chnl0_bp_imp);
chnl_agts[1].monitor.mon_bp_port.connect(chker.chnl1_bp_imp);
chnl_agts[2].monitor.mon_bp_port.connect(chker.chnl2_bp_imp);
reg_agt.monitor.mon_bp_port.connect(chker.reg_bg_imp);
fmt_agt.monitor.mon_bp_port.connect(chker.fmt_bp_imp);
**注意:只有initiator才能调用connect函数,target则作为connect的参数。**此处initiator是monitor,它们要将数据put到checker里,所以是monitor来调用connect函数,而checker作为参数。
6、在mcdf_checker的connect_phase阶段,完成mcdf_refmod的TLM port与mcdf_checker的TLM import的连接。
// foreach(this.refmod.in_mbs[i]) begin
// this.refmod.in_mbs[i] = this.chnl_mbs[i];
// this.exp_mbs[i] = this.refmod.out_mbs[i];
// end
this.refmod.in_bgpk_ports[0].connect(this.chnl0_bgpk_imp);
this.refmod.in_bgpk_ports[1].connect(this.chnl1_bgpk_imp);
this.refmod.in_bgpk_ports[2].connect(this.chnl2_bgpk_imp);
this.refmod.reg_bg_port.connect(this.reg_bp_imp);
同样的,此处initiator是refmod,它们要将数据get过来,所以是refmod来调用connect函数。
TLM通信管道
完成了上述实验,感觉工作量增加了不少。比如需要自己去实现具体的get/peek/put()方法。
那么有没有既可以使用TLM端口,又不用自己去实现具体的方法呢?
有!那就是TLM通信管道!
知识回顾
TLM通信管道的作用?
- 可以不用在target一端实现传输方法,同时也能享受TLM的好处
分类
TLM FIFO
引入原因:
- consumer在没有分析transaction时,希望先存储到本地FIFO中,稍后使用
- TLM FIFO uvm_tlm_fifo类是一个新组件,继承于uvm_componnet类,预先内置了多个端口以及实现了多个对应方法,用户无需自己实现这些方法,同时又能够享受TLM端口的好处。(注意,uvm_tlm_fifo只是声明了这些端口,当我们要使用的时候还是要例化的)
uvm_tlm_fifo组件内部实现
- 内置了一个没有尺寸限制的mailbox#(T),用来存储数据类型T。而uvm_tlm_fifo的多个端口对应的方法均是利用该mailbox实现了数据读写;
- 也就是说,功能类似于mailbox,不同之处在于其提供了各种端口供用户使用
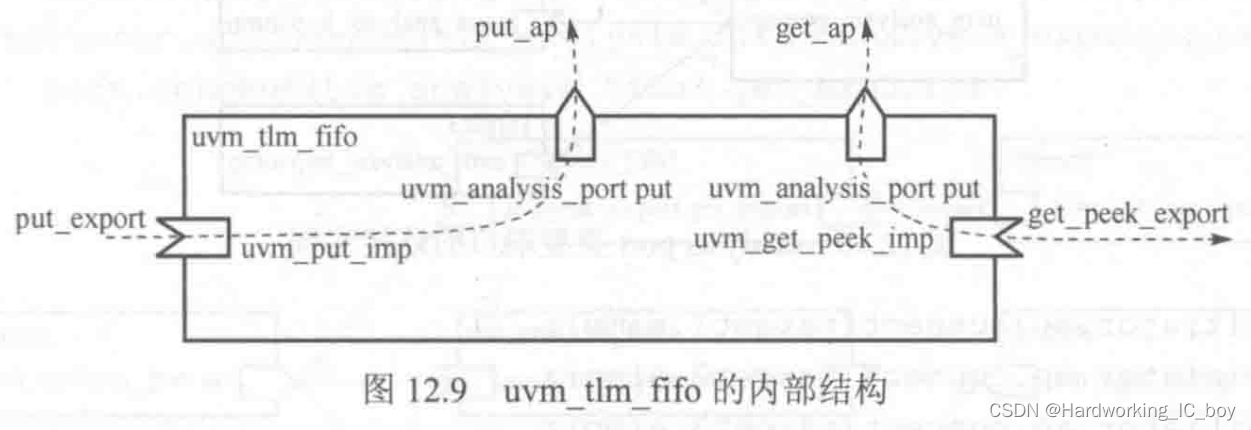
- 常用端口
- put_export:用户可以通过该端口调用put、try_put、can_put
- put_ap:调用了put方法写入的数据同时也会通过该端口的write函数送出
- get_peek_export:用户可通过该端口调用get、try_get、can_get、peek、try_peek、can_peek
- get_ap:调用了get和peek方法读出的数据也会通过该端口的write函数送出
analysis端口
作用:
- 如果数据源端发生变化需要通知和它关联的多个组件,就可以用到analysis端口,可以满足一端到多端的通信
分类:
- uvm_analysis_port、uvm_analysis_export、uvm_analysis_imp
analysis port类型端口连接实例
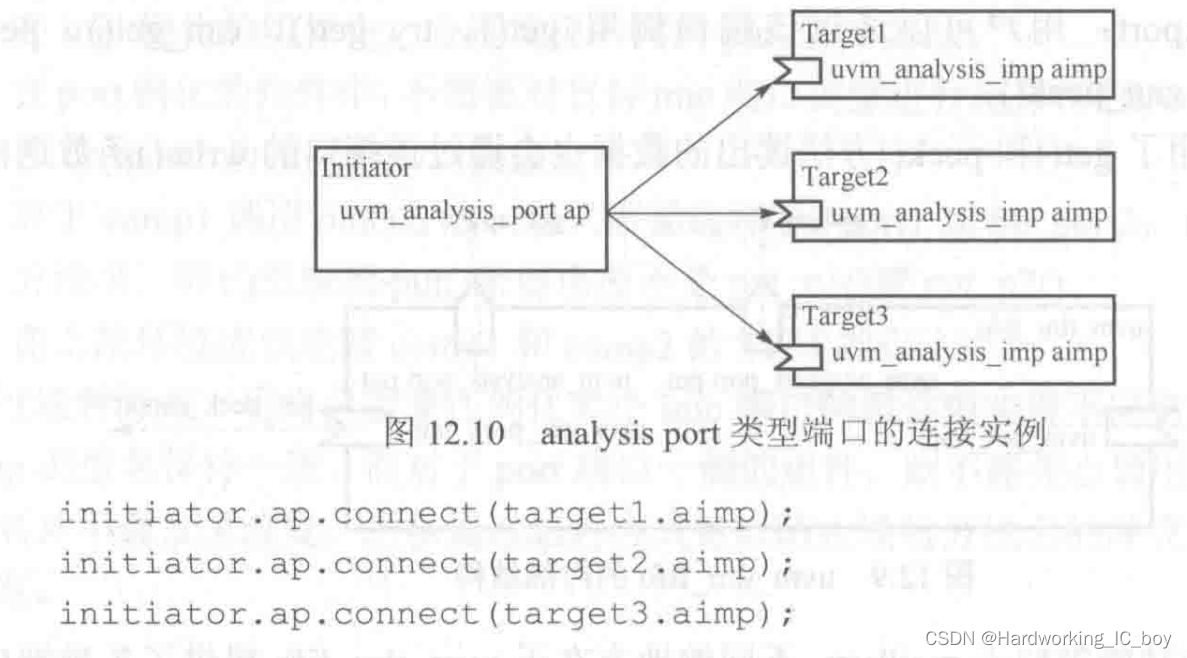
说明:
- 这是从一个initiator端到多个target端的方式。analysis port采用的是“push"模式,也就是从initiator端调用多个target端的write函数实现数据传输;
- 在initiator调用write函数时,实际上是通过循环的方式将所有连接的target内置的write函数进行调用。由于函数是立即返回的,所以无论连接多少个target,initiator端调用write函数总是可以立即返回
- 和单一端口函数调用不同的是,即使没有和target相连,调用write函数时也不会发生错误
analysis_port/analysis_export和port/export端口的区别
1、可连接imp数量
- analysis_port、analysis_export更像是一个广播,可以一对多
2、方法区别
- analysis_port、analysis_export没有阻塞、非阻塞的概念,因为本身就是广播,不必等待相连端口的响应(感觉也可以理解为非阻塞,因为马上返回)
- analysis_port、analysis_export只有write一种操作,而port、export端口有put/get/peek等操作
analysis TLM FIFO
- uvm_tlm_analysis_fifo继承于uvm_tlm_fifo,既有面向单一TLM端口的数据缓存特性,又可以实现一对多通信

如果想轻松实现一端到多端的数据传输,可以如下插入多个uvm_tlm_analysis_fifo
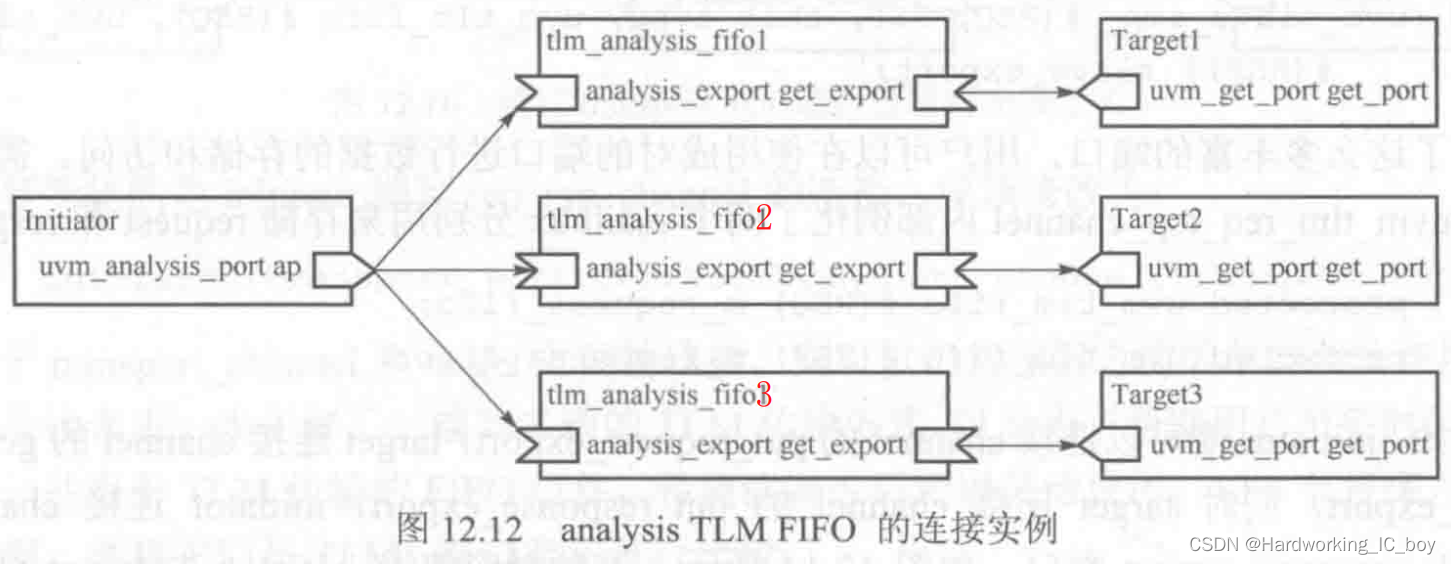
- 将initiator的analysis port连接到tlm_analysis_fifo的get_export端口,这样数据可以从initiator发起,写入到各个tlm_analysis_fifo的缓存中
- 将多个target的get_port连接到tlm_analysis_fifo的get_export,注意保持端口类型的匹配,这样从target一侧只需要调用get方法就可以得到先前存储在tlm_analysis_fifo中的数据
实验
1、将原本在mcdf_refmod中的out_mb替换为uvm_tlm_fifo类型,并且完成例化,以及对应的变量名替换;
//TODO-2.1 replace the out_mbs[3] with uvm_tlm_fifo type
// mailbox #(fmt_trans) out_mbs[3];
uvm_tlm_fifo #(fmt_trans) out_tlm_fifos[3];
//TODO-2.1 instantiate the TLM fifos
// foreach(this.out_mbs[i]) this.out_mbs[i] = new();
foreach(out_tlm_fifos[i]) out_tlm_fifos[i] = new($sformatf("out_tlm_fifos[%0d]",i),this);
//TODO-2.1 replace the out_mbs[3] with uvm_tlm_fifo type
// this.out_mbs[id].put(ot);
this.out_tlm_fifos[id].put(ot);
2、将原本在mcdf_checker中的exp_mbs[3]的邮箱句柄数组,替换为uvm_blocking_get_port类型句柄数组,并且做相应的例化以及变量名替换;
//TODO-2.2 replace exp_mbs[3] with TLM uvm_blocking_get_port type
// mailbox #(fmt_trans) exp_mbs[3];
uvm_blocking_get_port #(fmt_trans) exp_bg_ports[3];
//TODO-2.2 instantiate the TLM blocking_get ports
foreach(exp_bg_ports[i]) exp_bg_ports[i] = new($sformatf("exp_bg_ports[%0d]",i),this);
//TODO-2.2 replace the exp_mbs with the TLM ports
// this.exp_mbs[mont.ch_id].get(expt);
this.exp_bg_ports[mont.ch_id].get(expt);
3、在mcdf_checker中,完成在mcdf_checker中的TLM port端口到mcdf_refmod中的uvm_tlm_fifo自带的blocking_get_export端口的连接。
//TODO-2.3 connect the TLM blocking_get ports to the blocking_get
//exports of the reference model
foreach(exp_bg_ports[i]) begin
exp_bg_ports[i].connect(refmod.out_tlm_fifos[i].blocking_get_export);
end
此处的blocking_get_export我们不需要去声明以及例化,uvm_tlm_fifo中预先内置了。
UVM的回调类型uvm_callback
知识回顾
callback机制必要性?
- callback机制的最大用处就是提高验证平台的可重用性。 很多情况下, 验证人员期望在一个项目中开发的验证平台能够用于另外一个项目。 但是, 通常来说, 完全的重用是比较难实现的, 两个不同的项目之间或多或少会有一些差异。 如果把两个项目不同的地方使用callback函数来做, 而把相同的地方写成一个完整的env, 这样重用时, 只要改变相关的callback函数,env可完全的重用。
- 例如,对于VIP( Verification Intellectual Property) 来说, 一个很容易预测到的需求是在driver中, 在发送transaction之前, 用户可能会针对transaction做某些动作, 因此应该提供一个pre_tran的接口, 如用户A可能在pre_tran中将要发送内容的最后4个字节设置为发送的包的序号, 这样在包出现比对错误时, 可以快速地定位, B用户可能在整个包发送之前先在线路上发送几个特殊的字节, C用户可能将整个包的长度截去一部分, D用户……总之不同的用户会有不同的需求。 正是callback机制的存在, 满足了这种需求, 扩大了VIP的应用范围。
- 工厂机制的override是为了覆盖,而callback是为了延伸。
为什么要专门定义一个uvm_callback类?
以前用户自定义了回调函数不就够了,为啥还要专门定义一个uvm_callback类?
为了使函数回调拥有顺序和继承性(是通过两个相关类uvm_callback_iter和uvm_callback#(T,CB)来实现的)。
- 所谓的顺序指的是,当你添加了多个cb,那就按顺序执行。也就是下面先执行m_cb1,再执行m_cb2
uvm_callbacks #(comp1)::add(c1,m_cb1);
uvm_callbacks #(comp1)::add(c1,m_cb2);
- 所谓的继承性指的是,如果cb2继承于cb1,那么将其与comp1绑定时只需要绑定父类cb1就行了、(`uvm_register_cb(comp1,cb1)),不需要绑定子类cb2(不需要写`uvm_register_cb(comp1,cb1))
预留一个callback任务/函数接口的三步骤
1、定义callback类
class cb1 extends uvm_callback;
`uvm_object_utils(cb1)
function new(string name = "cb1");
super.new(name);
endfunction
virtual function void do_trans(edata d);//此处do_trans指具体的回调函数
d.data = 200;
`uvm_info("CB", $sformatf("cb1 executed with data %0d", d.data), UVM_LOW)
endfunction
endclass
2、绑定及插入callback
绑定及插入cb(在要预留callback函数/任务接口的类中调用uvm_register_cb进行绑定,并在调用callback函数/任务接口的函数/任务中, 使用uvm_do_callbacks宏来插入cb
`uvm_register_cb(comp1,cb1)
注意,comp1和cb1都是类名,而不是实例名。
`uvm_do_callbacks(comp1,cb1,do_trans(d))
这里uvm_do_callbacks的三个参数意义如下:
- 第一个参数comp1是调用回调函数do_trans的类的名字
- 第二个参数cb1是指回调函数do_trans在哪个uvm_callback类里
- 第三个参数do_trans是要调用的回调函数,在调用时要顺便给出do_trans的参数,此处为d
3、添加callback
`uvm_callbacks #(comp1)::add(c1,m_cb1)
注意,c1和m_cb1都是实例名。
实验
接下来,我们将练习uvm_callback的定义、链接和使用方式。由此,我们可以将原有的 mcdf_data_consistence_basic_test 和 mcdf_full_random_test 的类实现方式(即类继承方式) 修改为回调函数的实现方式,帮助同学们认识,完成类的复用除了可以使用继承,还可以使用回调函数。请按照以下要求实现代码:
1、请在路桑给的uvm_callback类中,预先定义需要的几个虚方法.
class cb_mcdf_base extends uvm_callback;
`uvm_object_utils(cb_mcdf_base)
mcdf_base_test test;
function new (string name = "cb_mcdf_base");
super.new(name);
endfunction
virtual task cb_do_reg();
// User to define the content
endtask
virtual task cb_do_formatter();
// User to define the content
endtask
virtual task cb_do_data();
// User to define the content
endtask
endclass
回调类中需要包含之后要用到的回调函数。
2、请使用callback对应的宏,完成目标uvm_test类型与目标uvm_callback类型的关联.
`uvm_register_cb(mcdf_base_test,cb_mcdf_base)
3、请继续在目标uvm_test类型指定的方法中,完成uvm_callback的方法回调指定.
virtual task do_reg();
//TODO-3.3 Use callback macro to link the callback method
`uvm_do_callbacks(mcdf_base_test, cb_mcdf_base, cb_do_reg())
endtask
// do external formatter down stream slave configuration
virtual task do_formatter();
//TODO-3.3 Use callback macro to link the callback method
`uvm_do_callbacks(mcdf_base_test, cb_mcdf_base, cb_do_formatter())
endtask
// do data transition from 3 channel slaves
virtual task do_data();
//TODO-3.3 Use callback macro to link the callback method
`uvm_do_callbacks(mcdf_base_test, cb_mcdf_base, cb_do_data())
endtask
此处要调用回调函数的类为mcdf_base_test,包含回调函数的callback类为cb_mcdf_base,要调用的回调函数分别为cb_do_reg()、cb_do_formatter()、cb_do_data()。
4、请分别完成uvm_callback和对应test类的定义:
a、cb_mcdf_data_consistence_basic 和 cb_mcdf_data_consistence_basic_test
此处cb_mcdf_data_consistence_basic 加上 cb_mcdf_data_consistence_basic_test,其作用就相当于mcdf_data_consistence_basic_test。
class cb_mcdf_data_consistence_basic extends cb_mcdf_base;
`uvm_object_utils(cb_mcdf_data_consistence_basic)
function new (string name = "cb_mcdf_data_consistence_basic");
super.new(name);
endfunction
task cb_do_reg();
//user to adapt contents from mcdf_data_consistence_basic_test
bit[31:0] wr_val, rd_val;
super.cb_do_reg();
// slv0 with len=8, prio=0, en=1
wr_val = (1<<3)+(0<<1)+1;
test.write_reg(`SLV0_RW_ADDR, wr_val);
test.read_reg(`SLV0_RW_ADDR, rd_val);
void'(test.diff_value(wr_val, rd_val, "SLV0_WR_REG"));
// slv1 with len=16, prio=1, en=1
wr_val = (2<<3)+(1<<1)+1;
test.write_reg(`SLV1_RW_ADDR, wr_val);
test.read_reg(`SLV1_RW_ADDR, rd_val);
void'(test.diff_value(wr_val, rd_val, "SLV1_WR_REG"));
// slv2 with len=32, prio=2, en=1
wr_val = (3<<3)+(2<<1)+1;
test.write_reg(`SLV2_RW_ADDR, wr_val);
test.read_reg(`SLV2_RW_ADDR, rd_val);
void'(test.diff_value(wr_val, rd_val, "SLV2_WR_REG"));
// send IDLE command
test.idle_reg();
endtask
task cb_do_formatter();
//user to adapt contents from mcdf_data_consistence_basic_test
super.cb_do_formatter();
void'(test.fmt_gen.randomize() with {fifo == LONG_FIFO; bandwidth == HIGH_WIDTH;});
test.fmt_gen.start();
endtask
task cb_do_data();
//user to adapt contents from mcdf_data_consistence_basic_test
super.cb_do_data();
void'(test.chnl_gens[0].randomize() with {ntrans==100; ch_id==0; data_nidles==0; pkt_nidles==1; data_size==8; });
void'(test.chnl_gens[1].randomize() with {ntrans==100; ch_id==1; data_nidles==1; pkt_nidles==4; data_size==16;});
void'(test.chnl_gens[2].randomize() with {ntrans==100; ch_id==2; data_nidles==2; pkt_nidles==8; data_size==32;});
fork
test.chnl_gens[0].start();
test.chnl_gens[1].start();
test.chnl_gens[2].start();
join
#10us; // wait until all data haven been transfered through MCDF
endtask
endclass: cb_mcdf_data_consistence_basic
//TODO-3.4 define cb_mcdf_data_consistence_basic_test
class cb_mcdf_data_consistence_basic_test extends mcdf_base_test;
// declare uvm_callback member
`uvm_component_utils(cb_mcdf_data_consistence_basic_test)
function new(string name = "cb_mcdf_data_consistence_basic_test", uvm_component parent);
super.new(name, parent);
endfunction
function void build_phase(uvm_phase phase);
super.build_phase(phase);
// instantiate uvm_callback and add it
cb = cb_mcdf_data_consistence_basic::type_id::create("cb"); //创建回调函数
uvm_callbacks#(mcdf_base_test)::add(this,cb);//添加回调函数。注意mcdf_base_test是父类
endfunction
function void connect_phase(uvm_phase phase);
super.connect_phase(phase);
// connect test handle to uvm_callback member
cb.test = this;
endfunction
endclass: cb_mcdf_data_consistence_basic_test
可以发现,cb_mcdf_data_consistence_basic_test 中并没有具体实现do_reg()、do_formatter()、do_data(),具体实现的内容放在了cb_mcdf_data_consistence_basic;
我们要做的是,采用下列语句将要调用回调函数的组件类以及包含回调函数的回调类进行add,
uvm_callbacks#(mcdf_base_test)::add(this,cb);
那么运行test时,就会调用cb_mcdf_data_consistence_basic这个回调类里的回调函数。
b、cb_mcdf_full_random 和 cb_mcdf_full_random_test
类似,此处略。
UVM的仿真控制函数
知识回顾
- end_of_elaboration_phase位于build_phase和connect_phase之后,用于微调测试环境
实验
我们也可以回顾实验1对uvm_root类的应用,学习更多关于uvm_root类的方法,请按照以下实验要求实现代码:
1、请在 mcdf_base_test 类中添加新的 phase 函数 end_of_elaboration_phase().同时利用uvm_root类来将信息的冗余度设置为UVM_HIGH ,以此来允许更多低级别的信息打印出来。另外,请设置uvm_root::set_report_max_quit_count()函数来设置仿真退出的最大数值,即如果uvm_error数量超过其指定值,那么仿真会退出。该变量默认数值为-1, 表示仿真不会伴随uvm_error退出。
2、请利用uvm_root::set_timeout()设置仿真的最大时间长度,同时由于此功能的生效,可以清除原有方法do_watchdog()的定义和调用。
1、2实验要求代码如下:
function void end_of_elaboration_phase(uvm_phase phase);
super.end_of_elaboration_phase(phase);
uvm_root::get().set_report_verbosity_level_hier(UVM_HIGH);
uvm_root::get().set_report_max_quit_count(1);
uvm_root::get().set_timeout(10ms);
endfunction
原先仿真的退出逻辑如下:do_watchdog的作用是,超过某个时间后如果仿真数据还没发送完,也直接结束。也就是,在fork… join_any块中,如果在规定时间内,数据正常发送完,那就正常退出。如果规定时间到了还没发送完,那么do_watchdog()完成,也会直接跳出当前的fork… join_any块,从而调用drop_objection结束仿真。
fork
this.do_data();
this.do_watchdog();//此处用join_any,也就是达到指定时间数据还没发送完,就drop_objection
join_any
















 2153
2153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











