







前言
一个好的预测模型能够在未知的数据上有好的表现,为了缩小训练数据和测试数据之间模型性能的差异,应该使模型尽可能的简单,简单性的另一种角度是平滑性,即函数不应该对输入的微小变化敏感。可以通过对输入加入噪声,增强输入-输出映射的平滑性。在前向传递过程中,是在训练过程中丢弃一些神经元。标准的暂退法包括在计算下一层前将当前层的一些节点置零。
定义暂退操作
暂退法函数将从均匀分布U[0,1]中抽取样本,样本数与这层的神经网络维度一致,保留对应样本大于p的节点,以实现按照概率p丢弃神经元。
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
if dropout == 1:
return torch.zeros_like(X)
if dropout == 0:
return X
# 给输入的每个元素分配保留的概率,大于dropout
mask = (torch.rand(X.shape) > dropout).float()
return mask * X / (1.0 - dropout)
定义模型参数和模型
采用两层网络的MLP使用Relu激活函数。
常用的暂退技巧:在靠近输入层的地方设置较低的暂退概率。
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
dropout1, dropout2 = 0.2, 0.5
# 在靠近输入的地方设置较低的暂退概率,暂退只在训练期间使用
# 定义模型
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2, is_train=True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_train
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape(-1, self.num_inputs)))
if self.training == True:
H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.training == True:
H2 = dropout_layer(H2, dropout2)
out = self.lin3(H2)
return out
训练和测试
使用fashion-mnist数据集
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
num_epochs,lr,batch_size=10,0.5,256
loss=nn.CrossEntropyLoss(reduction='none')
train_iter,test_iter=data_iter.load_data_fashion_mnist(batch_size)
trainer=torch.optim.SGD(net.parameters(),lr=lr)
Train.train(net,train_iter,test_iter,loss,num_epochs,trainer)
模型训练方法参考本专栏之前的文章
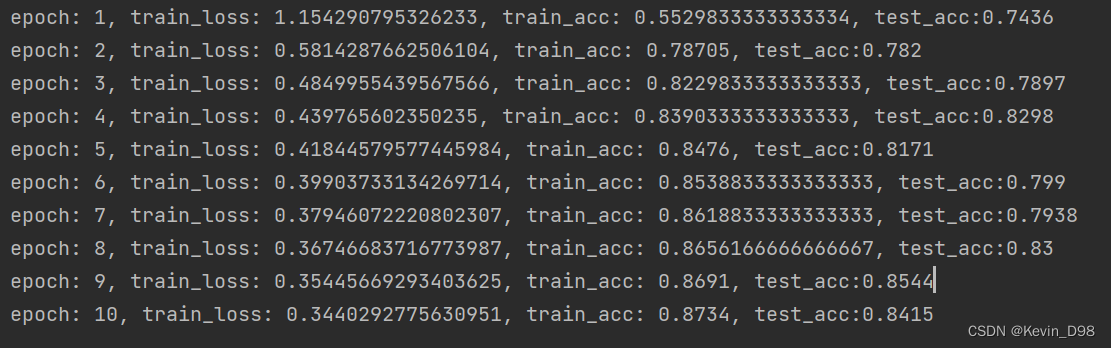

简洁实现
net_concise=nn.Sequential(nn.Flatten(),
nn.Linear(784,256),
nn.ReLU(),
nn.Dropout(dropout1),
nn.Linear(256,256),
nn.ReLU(),
nn.Dropout(dropout2),
nn.Linear(256,10))
def init_weight(m):
if type(m)==nn.Linear:
nn.init.normal_(m.weight,std=0.01)
net_concise.apply(init_weight)
trainer_concise=torch.optim.SGD(net_concise.parameters(),lr=lr)
Train.train(net_concise,train_iter,test_iter,loss,num_epochs,trainer_concise)















 2642
2642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









