







 本文介绍了LeNet-5模型的结构,包括其卷积编码器和全连接层,以及如何使用GPU加速训练过程。通过xavier初始化和交叉熵损失函数,展示了训练过程和性能评估的方法。
本文介绍了LeNet-5模型的结构,包括其卷积编码器和全连接层,以及如何使用GPU加速训练过程。通过xavier初始化和交叉熵损失函数,展示了训练过程和性能评估的方法。
前言
LeNet是最早发布的卷积神经网络之一。该模型被提出用于识别图像中的手写数字。
LeNet
LeNet-5由以下两个部分组成
- 卷积编码器(2)
- 全连接层(3)
卷积块由一个卷积层、一个sigmoid激活函数和一个平均汇聚层组成。
第一个卷积层有6个输出通道,第二个卷积层有16个输出通道。采用2×2的汇聚操作,且步幅为2.
3个全连接层分别有120,84,10个输出。
此处对原始模型做出部分修改,去除最后一层的高斯激活。
net=nn.Sequential(nn.Conv2d(1,6,kernel_size=5,padding=2),nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2,stride=2),
nn.Conv2d(6,16,kernel_size=5),nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2,stride=2),
nn.Flatten(),
nn.Linear(16*5*5,120),nn.Sigmoid(),
nn.Linear(120,84),nn.Sigmoid(),
nn.Linear(84,10))
模型训练
为了加快训练,使用GPU计算测试集上的精度以及训练过程中的计算。
此处采用xavier初始化模型参数以及交叉熵损失函数和小批量梯度下降。
batch_size=256
train_iter,test_iter=data_iter.load_data_fashion_mnist(batch_size)
将数据送入GPU进行计算测试集准确率
def evaluate_accuracy_gpu(net,data_iter,device=None):
"""使用GPU计算模型在数据集上的精度"""
if isinstance(net,torch.nn.Module):
net.eval()
if not device:
device=next(iter(net.parameters())).device
# 正确预测的数量,预测的总数
eva = 0.0
y_num = 0.0
with torch.no_grad():
for X,y in data_iter:
if isinstance(X,list):
X=[x.to(device) for x in X]
else:
X=X.to(device)
y=y.to(device)
eva += accuracy(net(X), y)
y_num += y.numel()
return eva/y_num
训练过程同样将数据送入GPU计算
def train_epoch_gpu(net, train_iter, loss, updater,device):
# 训练损失之和,训练准确数之和,样本数
train_loss_sum = 0.0
train_acc_sum = 0.0
num_samples = 0.0
# timer = d2l.torch.Timer()
for i, (X, y) in enumerate(train_iter):
# timer.start()
updater.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
updater.step()
with torch.no_grad():
train_loss_sum += l * X.shape[0]
train_acc_sum += evaluation.accuracy(y_hat, y)
num_samples += X.shape[0]
# timer.stop()
return train_loss_sum/num_samples,train_acc_sum/num_samples
def train_gpu(net,train_iter,test_iter,num_epochs,lr,device):
def init_weights(m):
if type(m)==torch.nn.Linear or type(m)==torch.nn.Conv2d:
torch.nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
net.to(device)
print('training on',device)
optimizer=torch.optim.SGD(net.parameters(),lr=lr)
loss=torch.nn.CrossEntropyLoss()
# num_batches=len(train_iter)
tr_l=[]
tr_a=[]
te_a=[]
for epoch in range(num_epochs):
net.train()
train_metric=train_epoch_gpu(net,train_iter,loss,optimizer,device)
test_accuracy = evaluation.evaluate_accuracy_gpu(net, test_iter)
train_loss, train_acc = train_metric
train_loss = train_loss.cpu().detach().numpy()
tr_l.append(train_loss)
tr_a.append(train_acc)
te_a.append(test_accuracy)
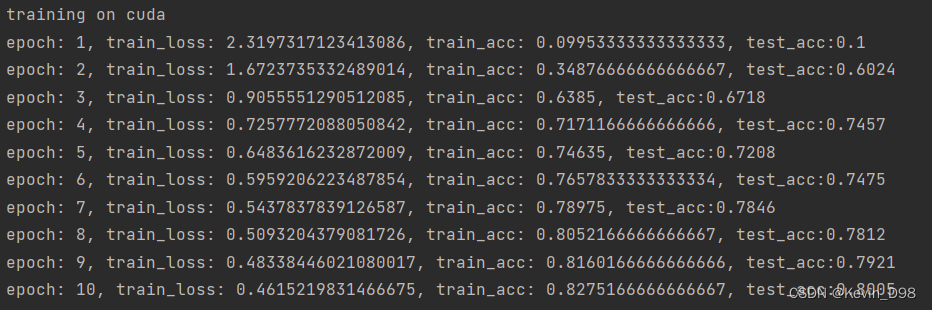
print(f'epoch: {epoch + 1}, train_loss: {train_loss}, train_acc: {train_acc}, test_acc:{test_accuracy}')
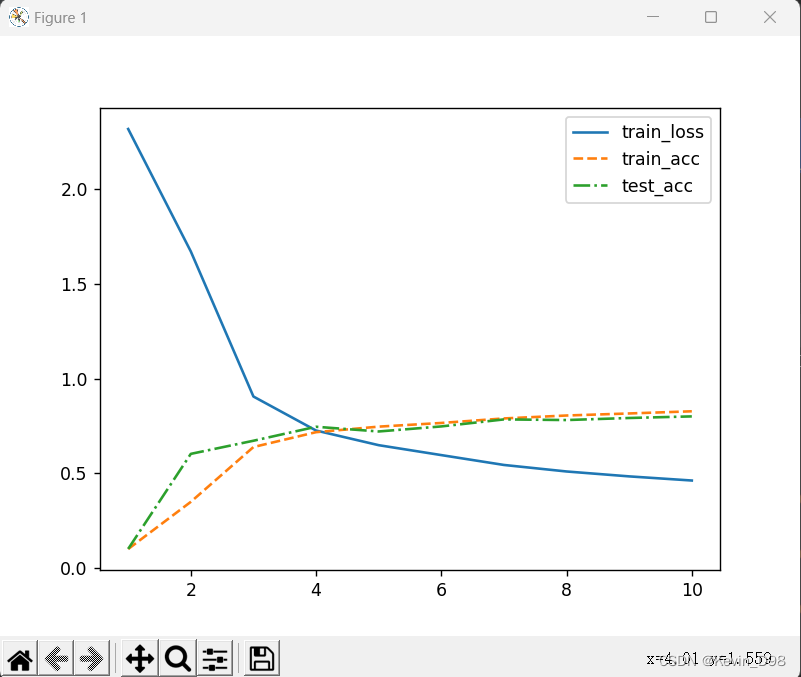
x = torch.arange(num_epochs)
plt.plot((x + 1), tr_l, '-', label='train_loss')
plt.plot(x + 1, tr_a, '--', label='train_acc')
plt.plot(x + 1, te_a, '-.', label='test_acc')
plt.legend()
plt.show()
print(f'on {str(device)}')
lr,num_epochs=0.9,10
Train.train_gpu(net,train_iter,test_iter,num_epochs,lr,device='cuda')















 1714
1714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









