






knn使用场景
K近邻算法是一种基本的分类和回归方法。在分类问题中,KNN算法假设给定的训练集的实例类别已经确定,对于新来的实例,KNN算法根据其k个最近邻的训练集实例的类别,通过多数表决等方式对新实例的类别进行预测。
KNN算法的三个基本要素是:k值的选择(即输入新实例要取多少个训练实例点作为近邻),距离度量方式(欧氏距离,曼哈顿距离等)以及分类的决策规则(常用的方式是取k个近邻训练实例中类别出现次数最多者作为输入新实例的类别)。
knn算法步骤

knn距离计算方法

k值选取及局限性

knn分类决策规则

knn实现中用到的kdtree
k近邻为减少搜索空间的复杂度,常采用k-d树的空间二叉树,它是一种k维欧几里得空间组织点的数据结构。
k-d树的经典创建过程如下:
a)随着树的深度轮流选择轴当做分割面。
(例如在三维空间中根节点是 x 轴垂直分割面,其子节点皆为 y 轴垂直分割面,其孙节点皆为 z 轴垂 直分割面,其曾孙节点则皆为 x 轴垂直分割面,依此类推。)
b)点由垂直分割面之轴坐标的中位数区分放入子树。
wikipedia图示如下:
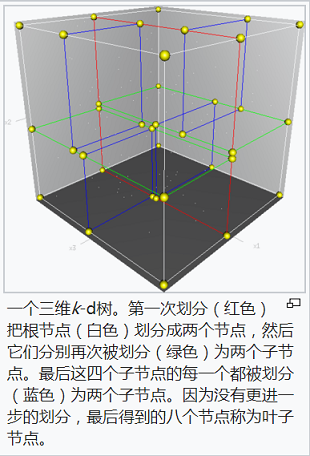
k-d树创建实例:
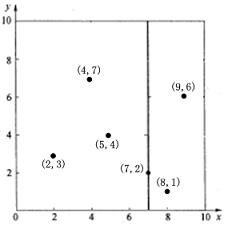
假设有6个二维数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},首先根据x轴找到中位数7,以分割面x=7分为左右两个子空间,(2,3) (4,7) (5,4)位于左子空间,(8,1) (9,6)位于右子空间,左子空间再以y=4为分割面划分左子空间为上下两部分,同理划分右子空间。
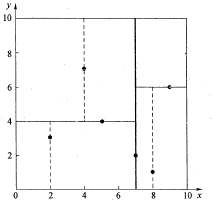
k-d树最邻近搜索的过程如下:
a)从根节点开始,递归的往下移。往左还是往右的决定方法与插入元素的方法一样(如果输入点在分区 面的左边则进入左子节点,在右边则进入右子节点)。
b)一旦移动到叶节点,将该节点当作"目前最佳点"。
c)解开递归,并对每个经过的节点运行下列步骤:
1)如果目前所在点比目前最佳点更靠近输入点,则将其变为目前最佳点。
2)检查另一边子树有没有更近的点,如果有则从该节点往下找。
d)当根节点搜索完毕后完成最邻近搜索。
参考推荐:
李航《统计学习方法》















 7672
7672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









