






 本文介绍了在pytest中如何利用参数化避免逻辑重复,通过@pytest.mark.parametrize装饰器定义多组测试用例数据,以及如何从Excel文件中读取数据进行测试。讲解了基本用法、用例数据和测试函数分离,以及使用openpyxl库处理Excel测试数据的步骤。
本文介绍了在pytest中如何利用参数化避免逻辑重复,通过@pytest.mark.parametrize装饰器定义多组测试用例数据,以及如何从Excel文件中读取数据进行测试。讲解了基本用法、用例数据和测试函数分离,以及使用openpyxl库处理Excel测试数据的步骤。
参数化的使用场景:
对于一个测试点,设计多条逻辑相似,只是输入数据和预期结果不同的用例时,如果每条用例都单独编写测试函数,会产生大量逻辑重复的代码。怎么办?==》使用“参数化”的方式编写一条测试函数,提供一组(多条)测试用例数据,达到只定义一个测试函数,但是却可以被作为多条用例执行多次的效果
如何在pytest中实现参数化(语法规则):
。使用@pytest.mark.parametrize装饰器实现参数化
。在定义测试函数时,在测试函数头顶上使用parametrize装饰器
。这时就可以用“参数化”的方式只编写一个测试板书来对应多天用例
参数化的用法:
==》1.使用@pytest.mark.parametrize为测试函数定义“多组”用例数据。
(1)每组用例数据中,可以使用多个值,参数的个数对应“”值’的个数。
(2)“参数名字字符串”必须和测试函数的形参对应
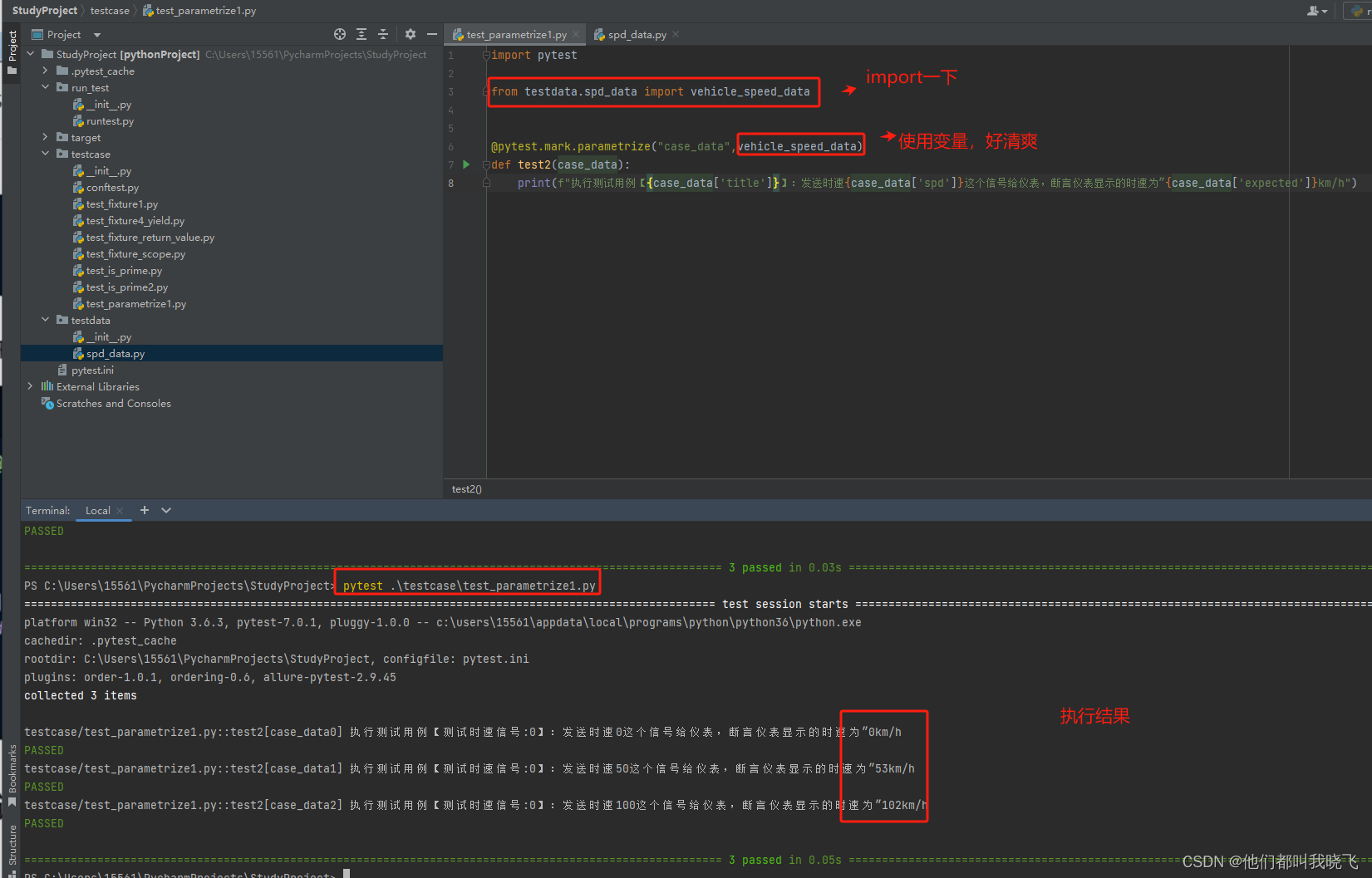
==》2.用例数据和测试函数分离—将用例数据存放在独立的python文件中
==》3.更彻底的分离—将用例数据定义在外部的Excel(/xlsx)文件中
1.1基本用法如下图:只有一个参数:
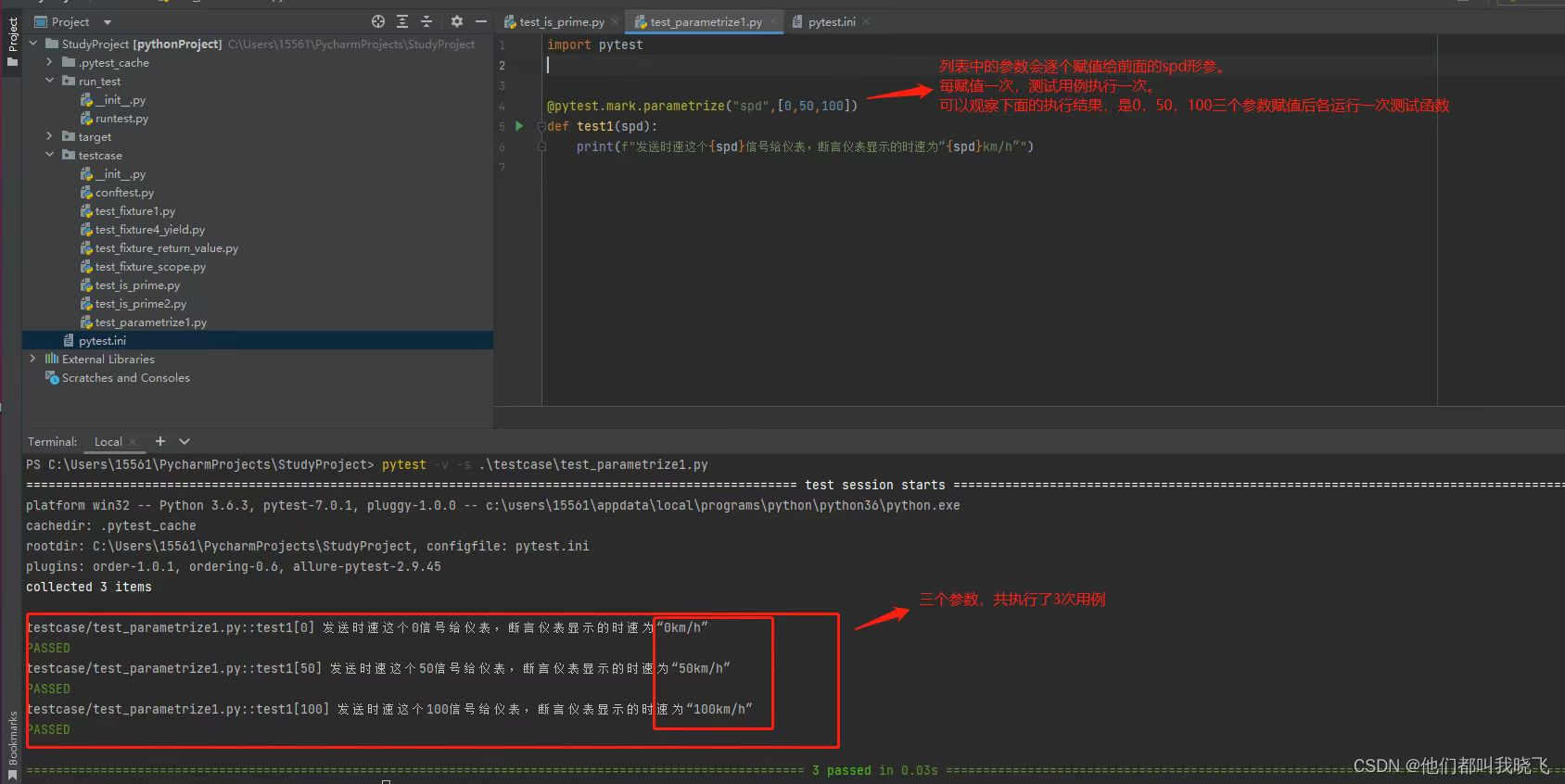
多个参数:
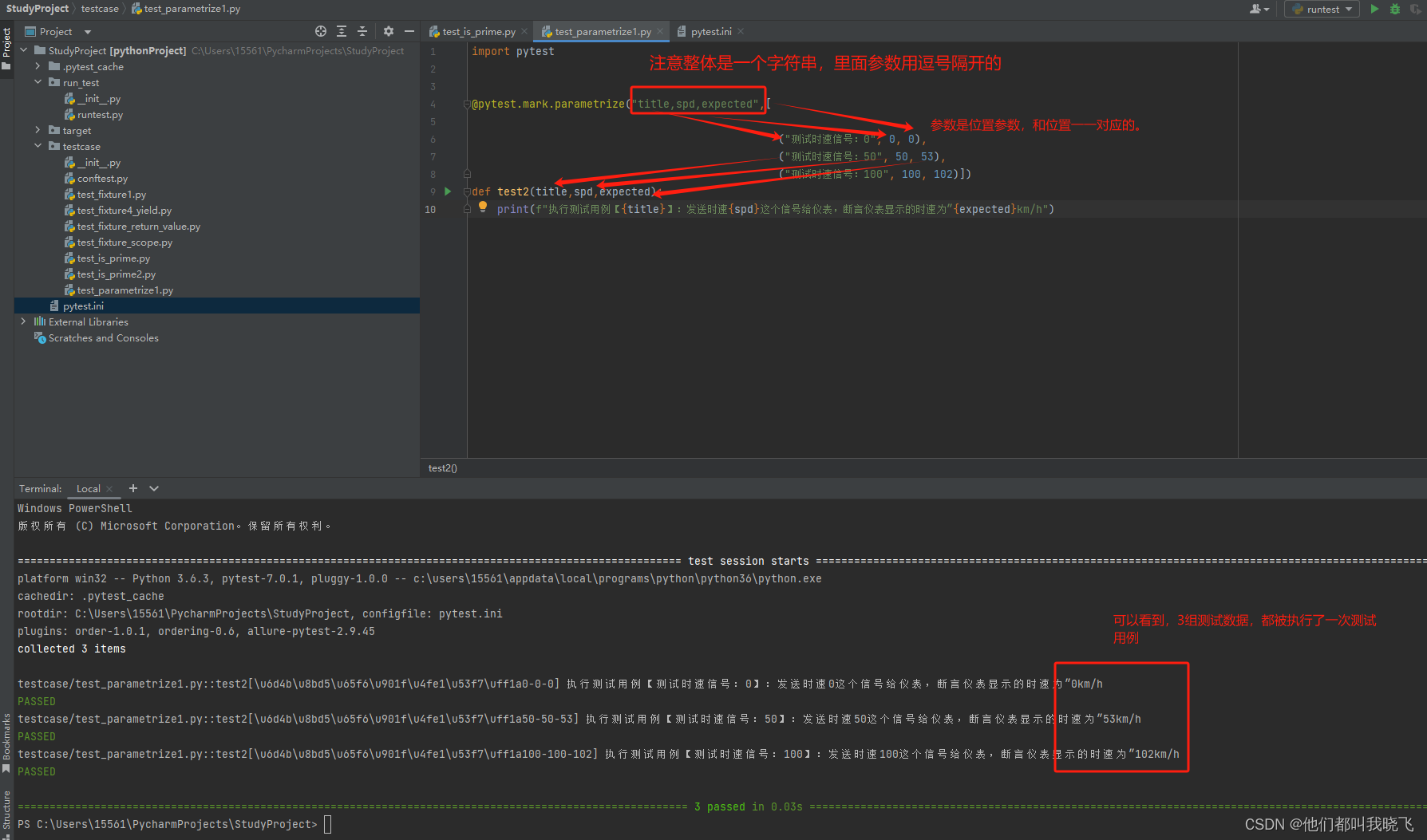
多个参数:为了整洁,使用字典数据。上面的用法产生一个问题,如果形参个数很多,写出来就很乱。这时可以采用“一个形参搭配字典数据”的方法,如下图
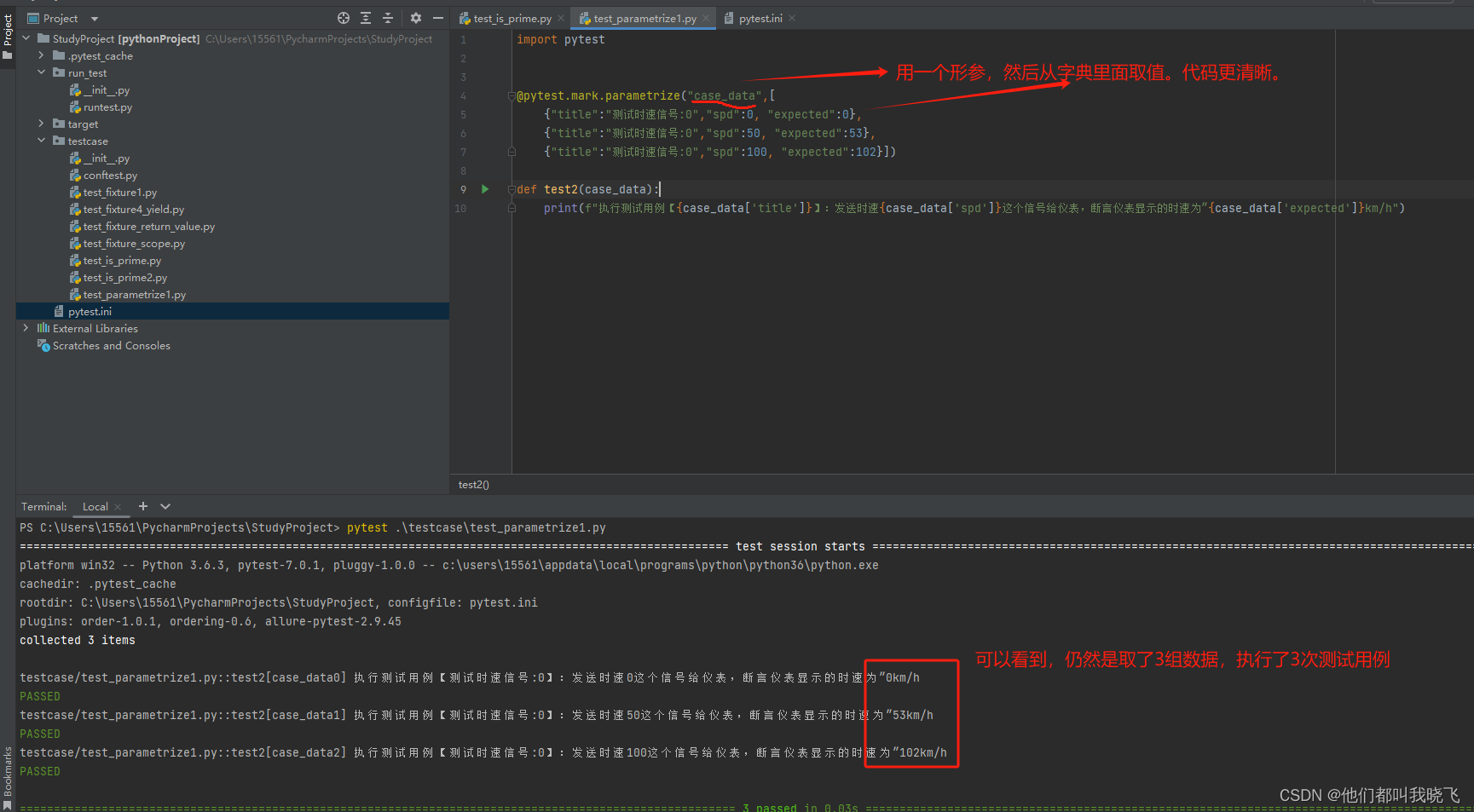
2.用例数据和测试函数分离—将用例数据存放在独立的python文件中
目的:测试函数和测试数据分开存放。
步骤:1.创建独立的testdata数据文件夹,变量拿出来。2.测试函数模块import,然后使用数据。
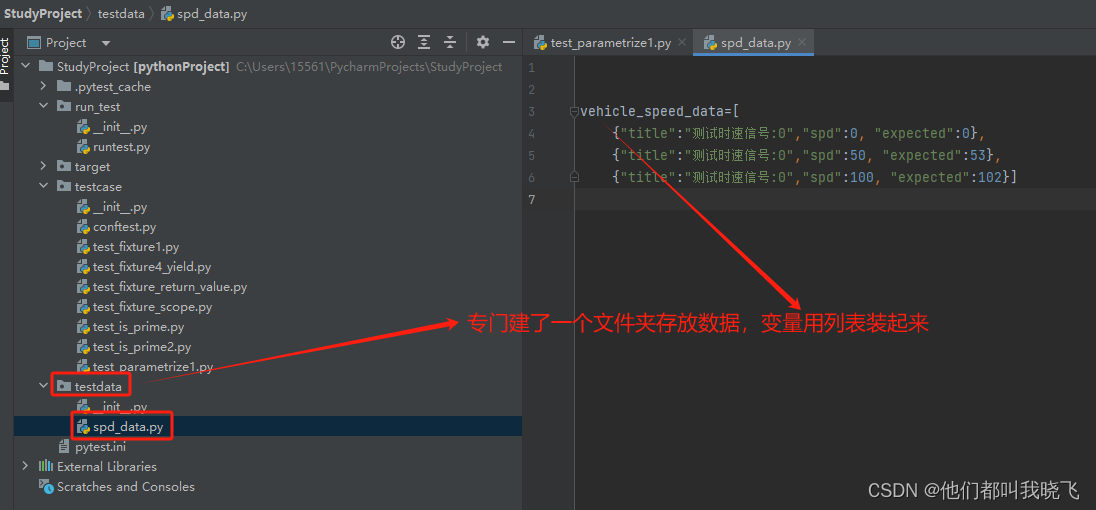
 3.更彻底的分离—将用例数据定义在外部的Excel(/xlsx)文件中
3.更彻底的分离—将用例数据定义在外部的Excel(/xlsx)文件中
目的:使用openpyxl第三方包来读取Excel文件(.xlsx格式的)文件的测试数据,传给测试函数使用。
测试数据文件“仪表测试用例.xlsx”存放在\testdata下,表格如下

步骤:
1.需要先安装,使用pip命令--pip install - i Simple IndexSimple Index
 2.根据sheet页名字,和第一列的关键字名字读取测试数据。
2.根据sheet页名字,和第一列的关键字名字读取测试数据。
函数传入2个参数,sheet_name是sheet页标签名,例如上图的“量表”页。function_name是“用例编号”列的用例编号。函数会找到该sheet页下,包含用例名字的测试数据。返回的数据是一个大列表,里面包含测试数据的字典数据。
from os.path import dirname
from openpyxl import load_workbook
def load_case_data(sheet_name, function_name):
"""从仪表测试用例的excel文件中,读取指定“表"中的指定”功能"的用例数据"""
case_datas = [] # 建一个列表用来装测试数据
wb = load_workbook(dirname(__file__)+"/仪表测试用例.xlsx") #加载Excel文件,返回文件对象:wb
# 遍历wb文件中的指定sheet表中的所有值:逐行遍历,每行数据是一个元祖(元祖中的每个元素就是一个单元格的值)
for row in wb[sheet_name].values:
if function_name in row[0]: #仅在当前行的第一列(“用例编号”列)的值包含指定的"功能“名时
print(row) # ('IP_VehicleSpeed_01', '测试时速信号:0', 0, '0km/h')
data = {"case_id":row[0],
"title": row[1],
"signal": row[2],
"expected": row[3]}
case_datas.append(data)
return case_datas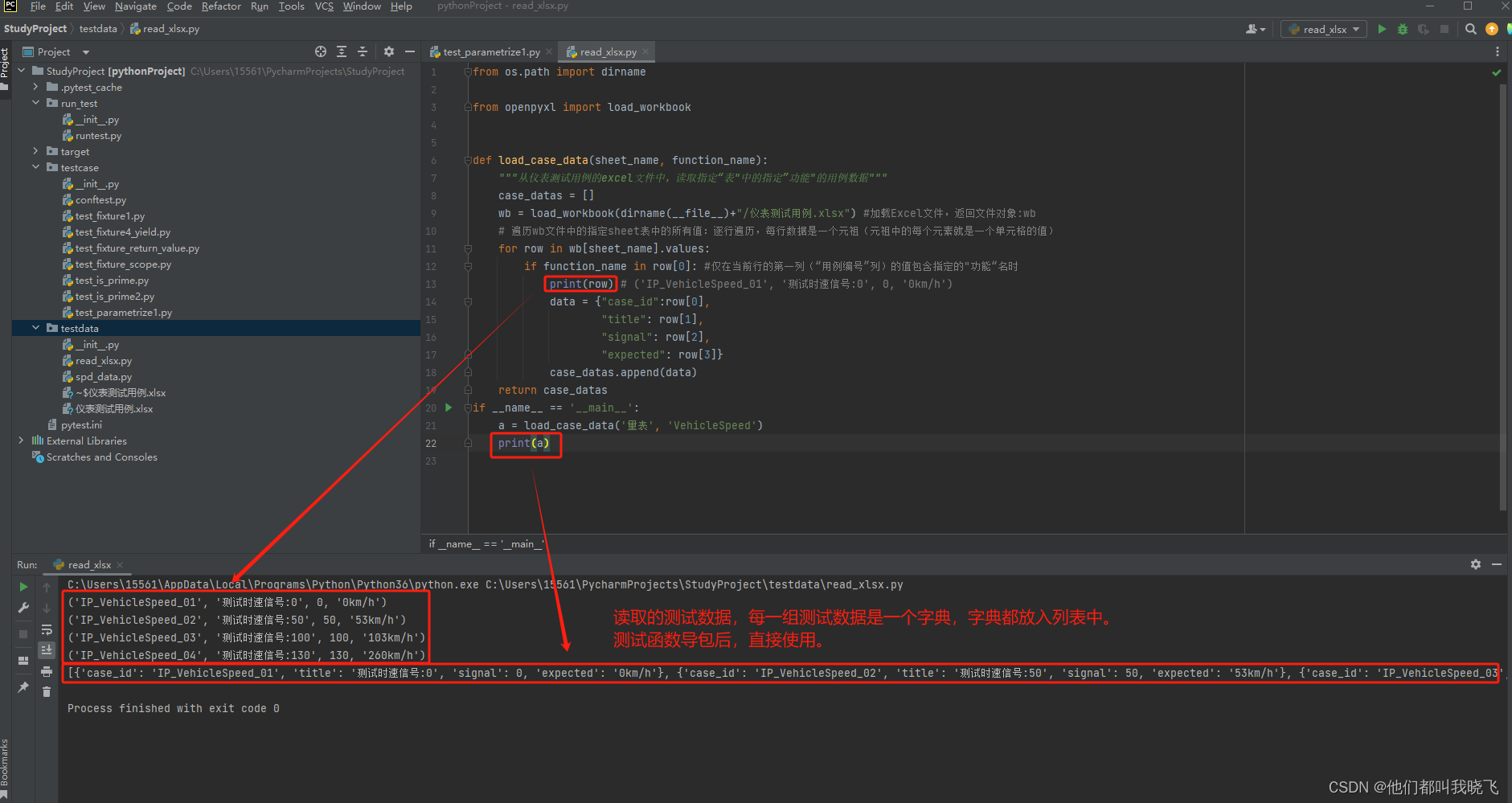 需要解释的是:
需要解释的是:
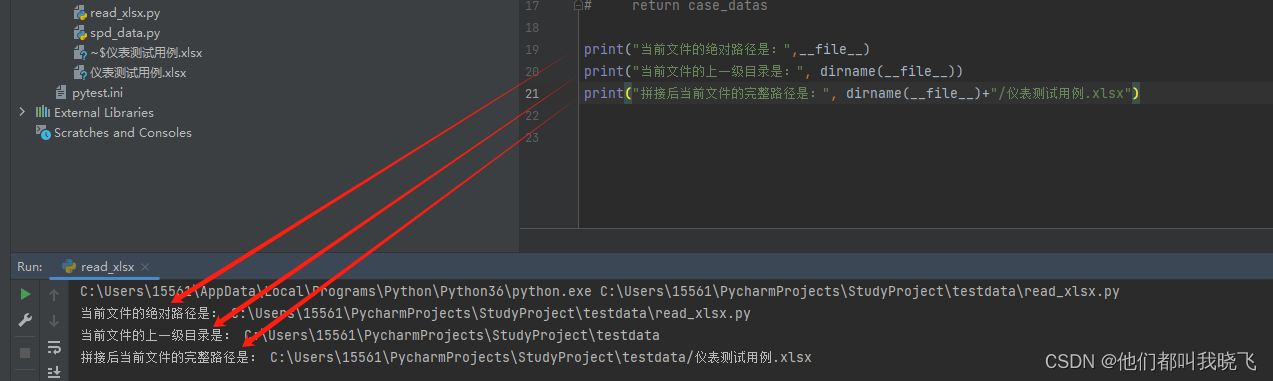
为了使代码在不同的电脑都能运行,所以需要找到本文件在任何一台电脑上的绝对路径。
__file__表示当前文件的绝对路径。
dirname是取文件所在的目录
类推==》dirname(__file__)就表示当前文件的目录绝对路径。再拼接excel文件名,就得到了excel文件在任意电脑的绝对路径。
运行示例如下:
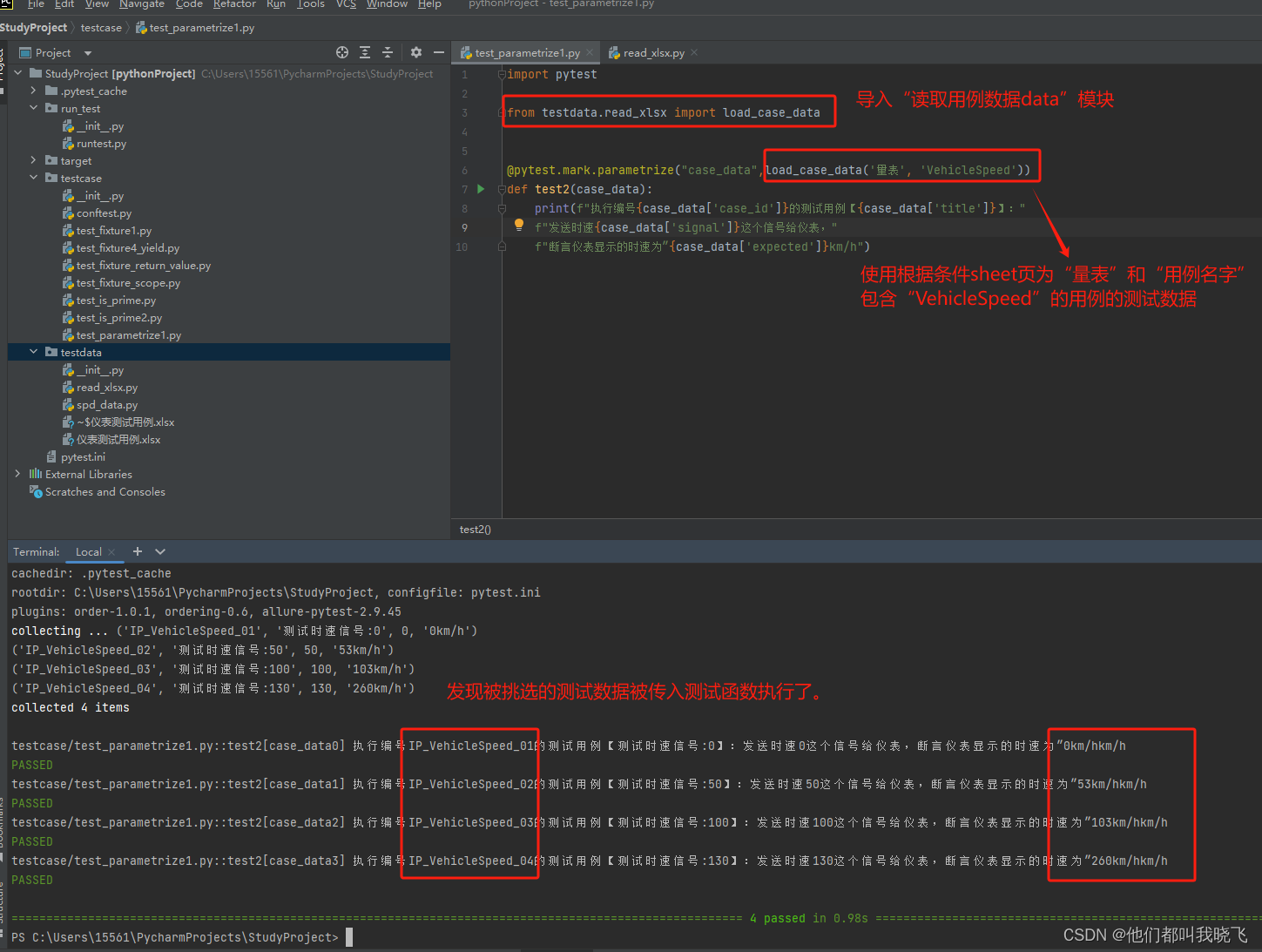
3.在测试函数模块,导入读取数据模块,并使用读取的测试数据执行测试函数
还剩一个pytest-html插件的使用,明天续上















 894
894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









