







回归问题的目标是在给定N维输入变量
x
的情况下,预测一个或多个连续目标变量的值。回归问题中最简单的就是线性回归,即目标变量和输入参数之间的关系是线性关系,许多非线性回归问题可以通过在线性回归的基础上引入层级结构或高维映射得到,因此线性回归是许多回归问题的基础,函数模型为:
hθ(x)=θ0+θ1x1+θ2x2+......θnxn
h(x)
即为我们的目标函数,也称为假设。使用向量可以表示为:
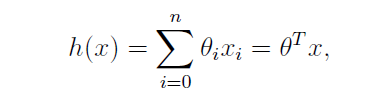
线性回归要解决的问题就是选择合适的参数使得 h(x) 和实际值越接近越好。通常,选择一个函数来衡量这种接近程度,也就是参数的好坏程度,这个函数称为损失函数,回归问题最常用的性能度量方法是均方误差方法,基于均方误差最小化来进行模型求解的方法又叫最小二乘法,在线性回归中,最小二乘法就是试图找到一条直线,使得所有样本到直线的欧氏距离之和最小:
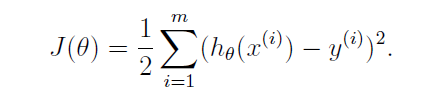
线性回归的目标就是要寻找使得损失函数最小的参数值,通常有两种方法:
一、梯度下降法
梯度下降法的思想是,考虑你站在山顶的某个位置,环顾四周,往哪个方向上走一步能让你下降得最快,这个方向就是梯度方向。算法描述为:给定一个参数的初始值,按下式不断循环更新参数直至收敛。
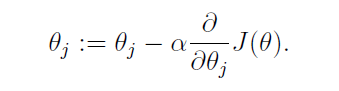
公式中的α称为学习速率,可以理解为你往山下走时每走一步的大小。
当训练集中只有一个样本时,上式中的偏导数一项可以简化为:
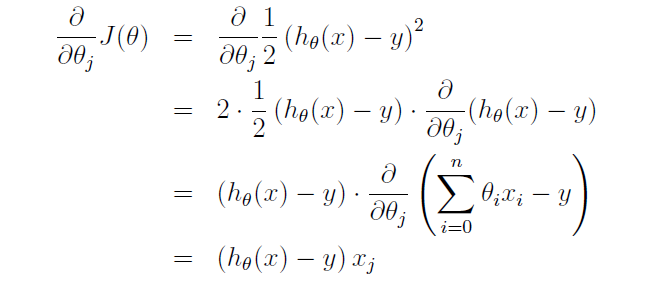
此时,参数更新表达式变为:
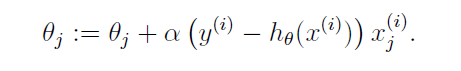
上式为只有一个训练集样本时的参数更新,扩展到训练集中有m个样本时的参数更新为:
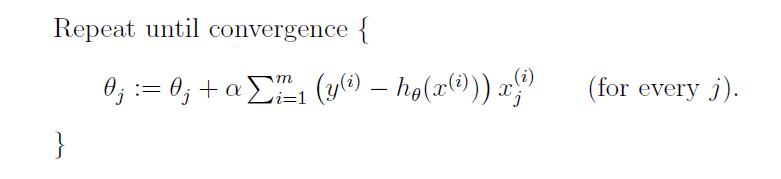
这个算法称为批梯度下降算法,因为循环的每一步都需要遍历整个训练集,当训练集很大时,这会导致算法运行非常缓慢,一种替代的算法称为随机梯度算法或增量梯度算法:
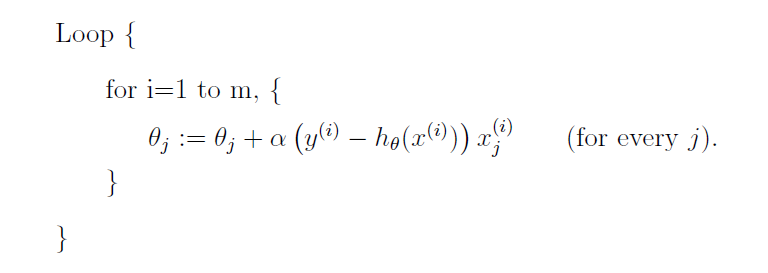
通常随机梯度算法比批梯度算法能更快达到最小值,但是随机梯度算法存在的问题是可能永远不会收敛,而是会在最小值附近振荡,但是这通常不会成为问题,因为实际中随机梯度算法在最小值附近产生的振荡值也是最小值的合理近似,可以合理认为其就是最小值。
二、The Normal Equations
将输入变量和目标变量分别表示为矩阵形式为:
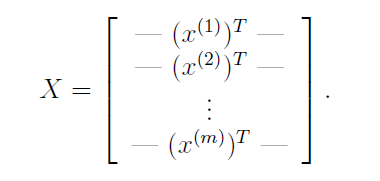
其中: (x(i))T=θ0x(i)0+θ1x(i)1+θ2x(i)2+......+θnx(i)n
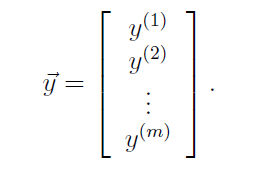
由此可以得到:
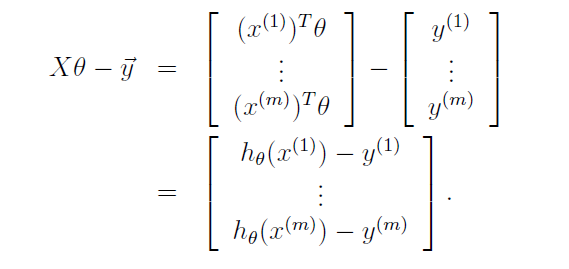
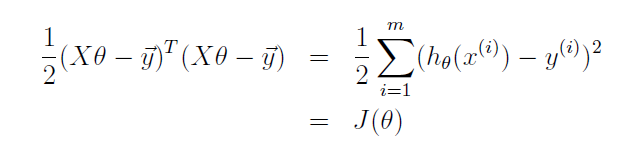
对 J(θ) 求导:
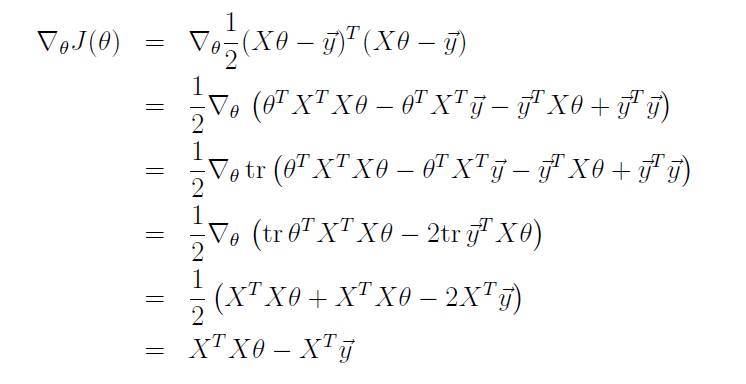
令其导数等于0,则可得到:
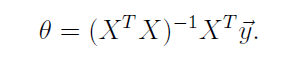
示例:
假设有如下的训练集,简单起见,输入变量假设只有一维。
| X | Y |
|---|---|
| 1 | 2 |
| 2 | 4 |
| 3 | 6 |
| 4 | 5 |
| 5 | 7 |
| 6 | 6 |
| 7 | 9 |
| 8 | 11 |
| 9 | 13 |
| 10 | 12 |
则目标函数为: hθ(x)=θ0+θ1x1 , ( x0=1 )
输入变量和目标变量矩阵为:
X=⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢111111111112345678910⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥
Y=⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢2465769111312⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥
#-*- coding: utf-8 -*-
import numpy as np
from matplotlib import pyplot as plt
plt.figure(figsize=(9,6))
#训练集较小,这里直接写出。通常应写一个函数从文件或数据库中读取训练集
x = [[1,1],[1,2],[1,3],[1,4],[1,5],[1,6],[1,7],[1,8],[1,9],[1,10]]
y = [[2],[4],[6],[5],[7],[6],[9],[11],[13],[12]]
#转换成矩阵
xMat = np.mat(x)
yMat = np.mat(y)
theta = (xMat.T * xMat).I * xMat.T * yMat
print "theta = ",theta
fig = plt.figure()
ax = fig.add_subplot(111)
x = xMat[:,1].flatten().A[0]
y = yMat[:].flatten().A[0]
xr = xMat.copy()
yr = xr * theta
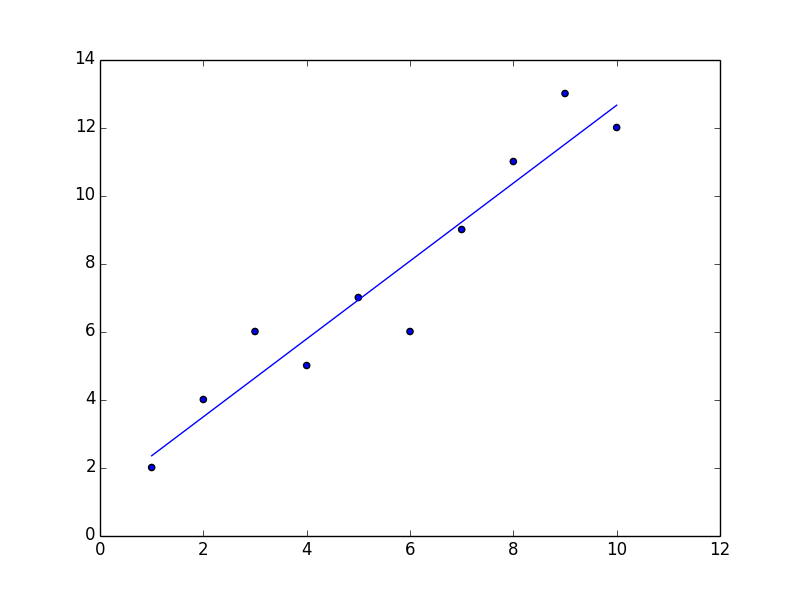
ax.scatter(x,y)
ax.plot(xr[:,1].flatten().A[0],yr.flatten().A[0])
plt.show()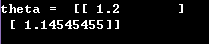















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









