









概述
虽然在n个元素的有序数组上折半查找所需要的时间为
o
(
log
n
)
o(\log n)
o(logn),但是在有序链表上查找所需要的时间为
o
(
n
)
o(n)
o(n)。为了提高有序链表的查找性能,可以在全部或部分节点上增加额外的指针。
跳表(skip list):增加了额外的向前指针的链表。
散列 :用来查找、插入、删除的另一种随机方法。
如果经常需要按序输出所有元素或按序查找元素,跳表的执行效率将优于散列。
字典(dictionary)
形如
(
k
,
v
)
(k,v)
(k,v)的数对所组成的集合,k是关键字,v是与关键字k对应的值。
有关字典的操作有:
- 确定字典是否为空
- 确定字典有多少数对
- 寻找一个指定了关键字的数对
- 插入一个数对
- 删除一个指定了关键字的数对
template<class K, class E>
class dictionary
{
public:
virtual ~dictionary() {}
virtual bool empty() const = 0;
virtual int size() const = 0;
virtual pair<const K,E>* find(const K&) const = 0;
virtual void erase(const K&) = 0;
virtual void insert(const pair<const K, E>&) = 0;
}
字典可以保存在线性表中,按关键字递增次序排列。可以用数组实现,也可以用链表实现。【本质还是线性表的插入删除查找】
跳表
理想情况
思想类似于折半查找。在折半的地方增加一个指针。
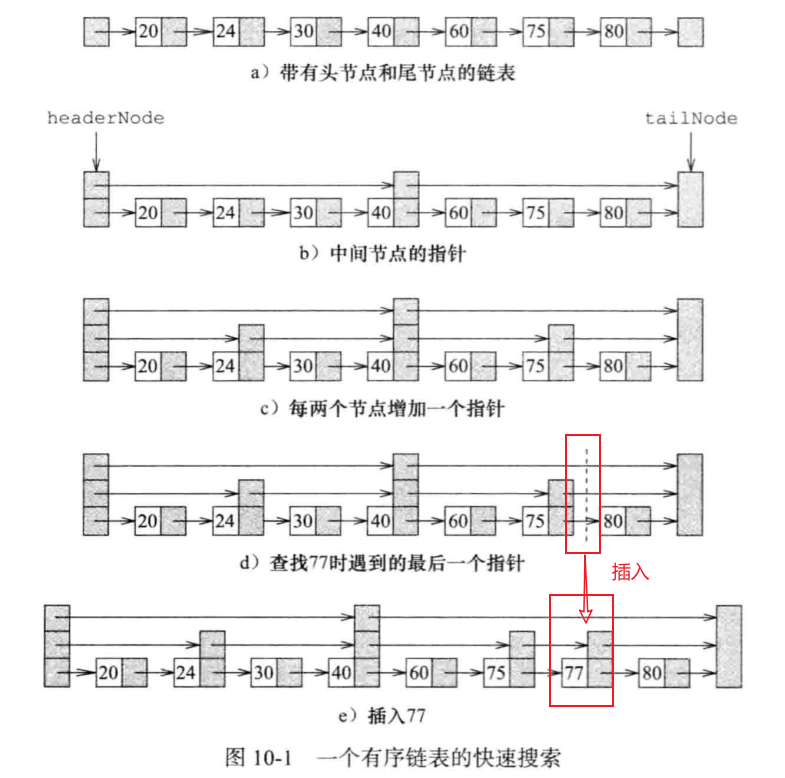
0级链表包括所有数对,1级链表每2个数对取一个,2级链表每4个数对取一个,i级链表每
2
i
2^i
2i个数对取一个。一个数对属于i级链表,当且仅当它属于0~i级链表,但不属于i+1级链表。
插入和删除
插入和删除时,要保持跳表的规则结构,需要耗时
o
(
n
)
o(n)
o(n)。
插入时要为新数对分配一个级(即确定它属于哪一级链表),分配过程由随机数生成器来完成。对一般的p,链表的级数为
⌊
log
1
p
n
⌋
+
1
\left \lfloor \log_{\frac{1}{p}}n \right \rfloor \quad+1
⌊logp1n⌋+1
删除操作,无法控制结构。
级的分配
p
=
i
−
1
级
链
表
的
数
对
个
数
i
级
链
表
的
数
对
个
数
p=\frac{i-1级链表的数对个数}{i级链表的数对个数}
p=i级链表的数对个数i−1级链表的数对个数
设定级数上限maxLevel,避免被随机分配到的级数特别大。
m
a
x
L
e
v
e
l
=
⌊
log
1
p
N
⌋
−
1
maxLevel=\left \lfloor \log_{\frac{1}{p}N} \right \rfloor \quad-1
maxLevel=⌊logp1N⌋−1
散列
字典的另一种表示方法。
散列函数和散列表
桶:散列表的每一个位置叫一个桶bucket。 f ( k ) f(k) f(k)是起始桶(home bucket)
线性探查
删除一个记录要保证搜索过程可以正常进行。不能仅仅把要删除的位置置空。删除需要移动若干个数对。从删除位置的下一个桶开始,逐个检查每个桶,以确定要移动的元素,直至到达一个空桶或回到删除位置位置。
跳表vs散列
- 均使用随机过程来提高字典操作的性能。
- 跳表的平均复杂度是对数级,散列的平均复杂度是常数级
- 跳表比散列更灵活
- 最坏时间复杂度,跳表 o ( n + m a x L e v e l ) o(n+maxLevel) o(n+maxLevel),散列 o ( n ) o(n) o(n)
- 最坏情况的空间需求,跳表大于链式散列
应用——文本压缩
——LZW压缩
把文本字符串映射为数字编码。
首先,该文本串中所有可能出现的字母都被分配一个代码。字符串和编码的映射关系存储在一个数对字典中。
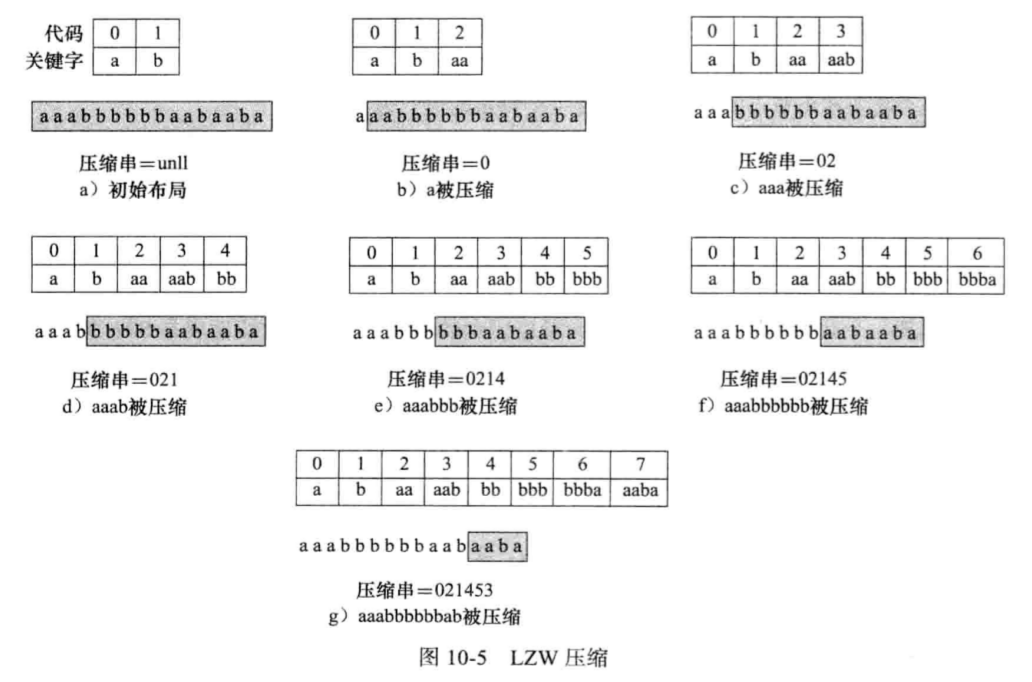
LZWrule:压缩器不断在文本串S的未编码部分(阴影部分)中寻找与字典中一个字符串相匹配的最长的字符串,并输出它的代码。这个字符串称前缀。
字典组织:将很长的字符串key压缩为固定长度的串。aaa可以表示为3a。















 776
776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









