







| 作者 | 版本 | 时间 | 内容 | 备注 |
| Allen | V0.0.1 | 2025/03/13 | 初期作成 | |
| Allen | V1.0.0 | 2025/03/14 | 完成制作、使用指南 | 章节1、2、3、4、5 |
| Allen | V1.0.1 | 2025/03/14 | 添加WanJuan2.0使用建议 | 章节6 |
1.OpenXLab
浦源-人工智能开源开放体系
1.1 开放项目
OpenMMLab 浦视 视觉智能开源平台
OpenGVLab 通用视觉开源平台
OpenDILab 浦策 开源决策智能平台
OpenXDLab 浦画 高质量数字内容平台
OpenXRLab 浦实 扩展现实开源平台
OpenDataLab 浦数 人工智能数据开源开放平台
DeepLink 浦算 人工智能开放计算体系
OpenEGLab 蒲公英 人工智能治理开放平台
OpenInnoLab 浦育 青少年人工智能开放创新平台
OpenMEDLab 浦医 医疗多模态基础模型开源平台
OpenDriveLab 浦驾 自动驾驶开放平台
OpenRobotLab 浦器 具身智能开放平台
1.2 应用中心
探秘 AIGC 精彩应用,开启 AI 无限可能
AIGC/计算机视觉/自然语言处理/多模态技术/其他
1.3 模型中心
模型一键托管,高速下载模型,快捷部署推理服务
1.4 数据集中心
为国产大模型提供高质量的开放数据集
2.OpenDataLab
为大模型提供高质量的开放数据集
2.1 平台简介
OpenDataLab 团队致力于构建 AI 开放数据生态,推动数据要素对大模型领域全面赋能。
OpenDataLab 是上海人工智能实验室的大模型数据基座团队打造的数据开放平台,现已成为中国大模型语料数据联盟开源数据服务指定平台,为开发者提供全链条的 AI 数据支持,应对和解决数据处理中的风险与挑战,推动 AI 研究及应用。
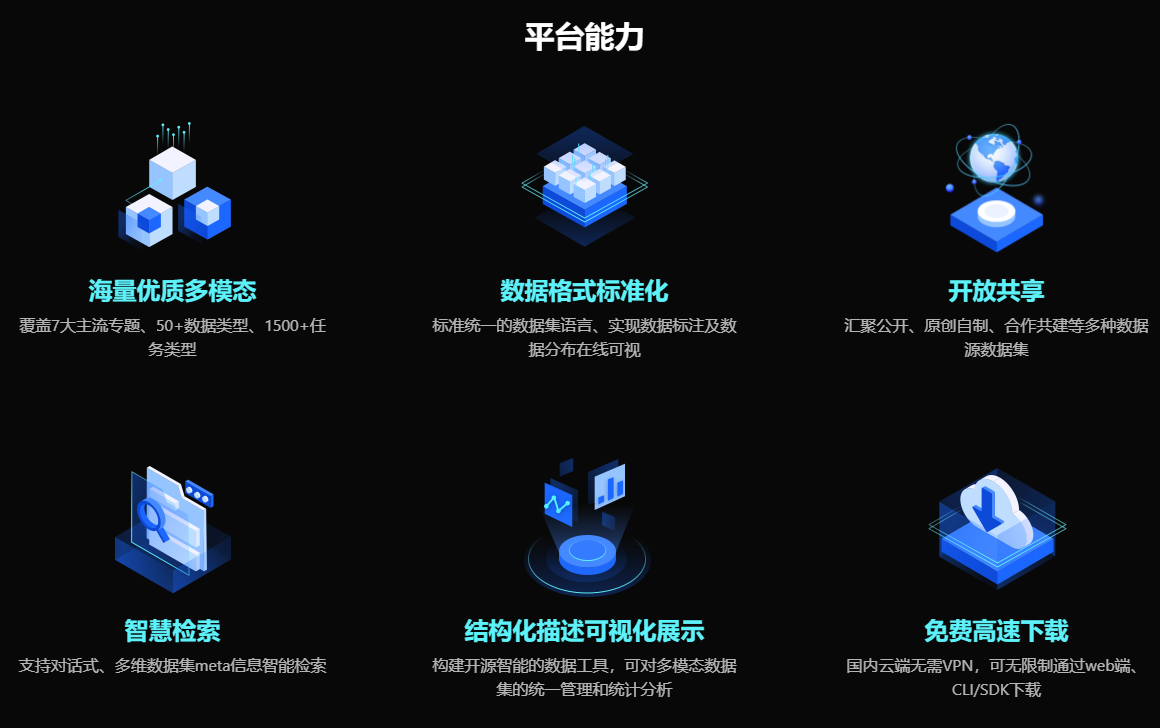
2.2 数据处理全流程工具箱
赋能大模型的预训练、微调和评测
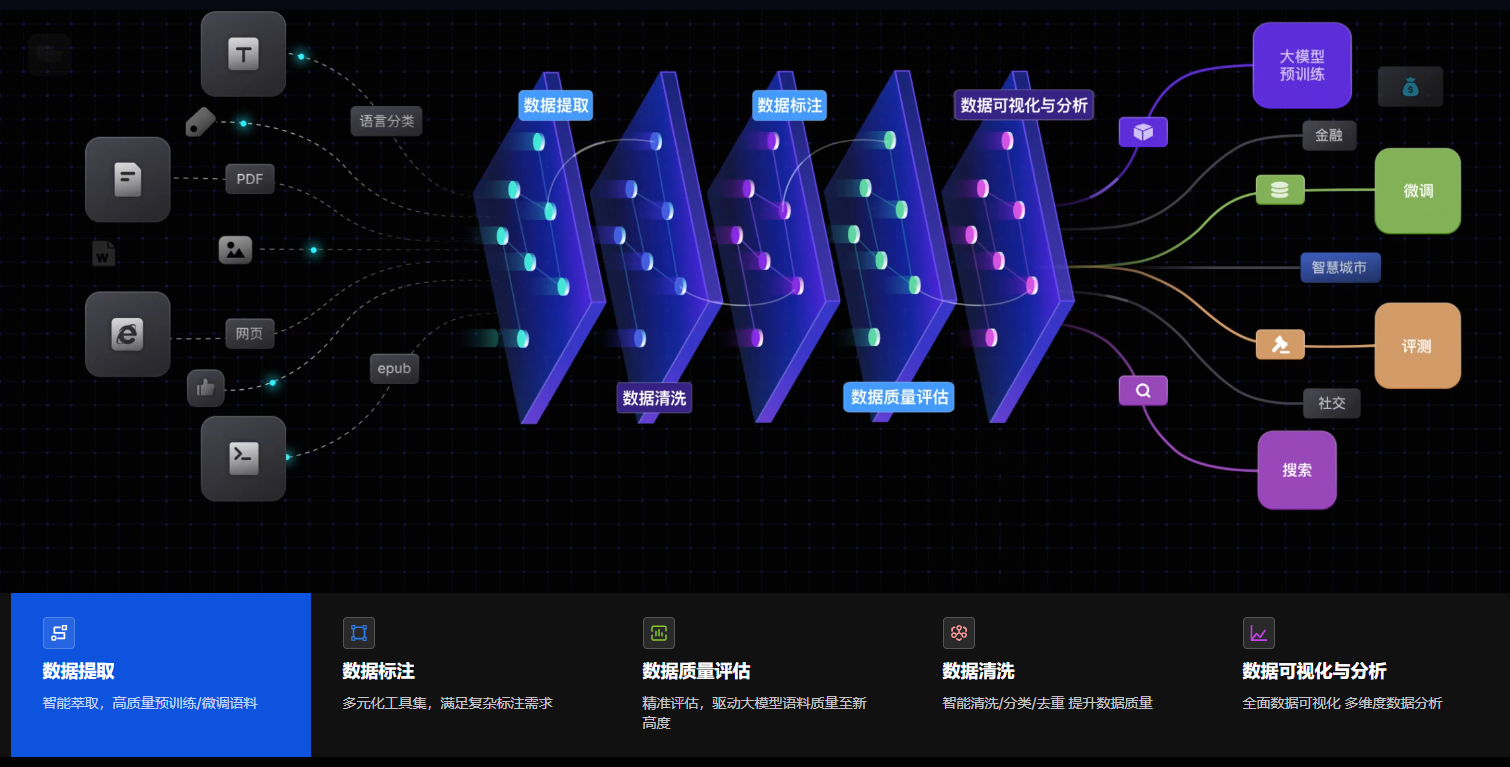
2.2.1 数据提取
智能萃取,高质量预训练/微调语料
MinerU
PDF文档提取
网页提取
2.2.2 数据标注
多元化工具集,满足复杂标注需求
LabelU 灵活的标注工具
LabelLLM 大模型标注平台
2.2.3 数据质量评估
精准评估,驱动大模型语料质量至新高度
2.2.4 数据清洗
智能清洗/分类/去重 提升数据质量
2.2.5 数据可视化与分析
全面数据可视化 多维度数据分析
2.3 数据集中心介绍
数据集中心支持多元数据管理,数据中心提供公开数据集的展示、检索和下载等,同时提供私有数据集的上传、管理和发布功能,支持用户自建数据集的开放共享。数据集中心为人工智能研究者提供免费开源的数据集,通过数据集中心,研究者可以获得格式统一的各领域经典数据集。通过平台的搜索功能,研究者可以迅速便捷地找到自己所需数据集;通过平台的统一格式,研究者可以便捷地对跨数据集任务进行开发。
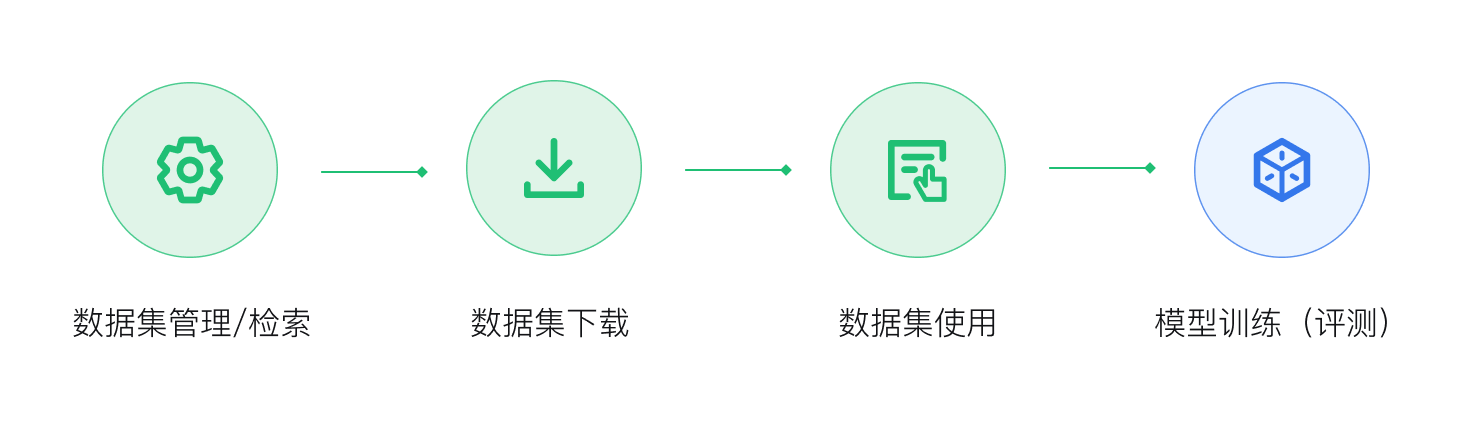
2.3.1 数据集创建流程
2.3.2 上传数据集
2.3.3 下载数据集
2.3.4 数据集卡片
2.3.5 数据集维护
2.3.6 数据集CLI(命令行工具)
数据集CLI(命令行工具) | OpenXLab浦源 - 文档中心
2.3.7 数据集Python SDK
数据集Python SDK | OpenXLab浦源 - 文档中心
3.制作数据集
3.1 创建数据集
3.2 上传数据集
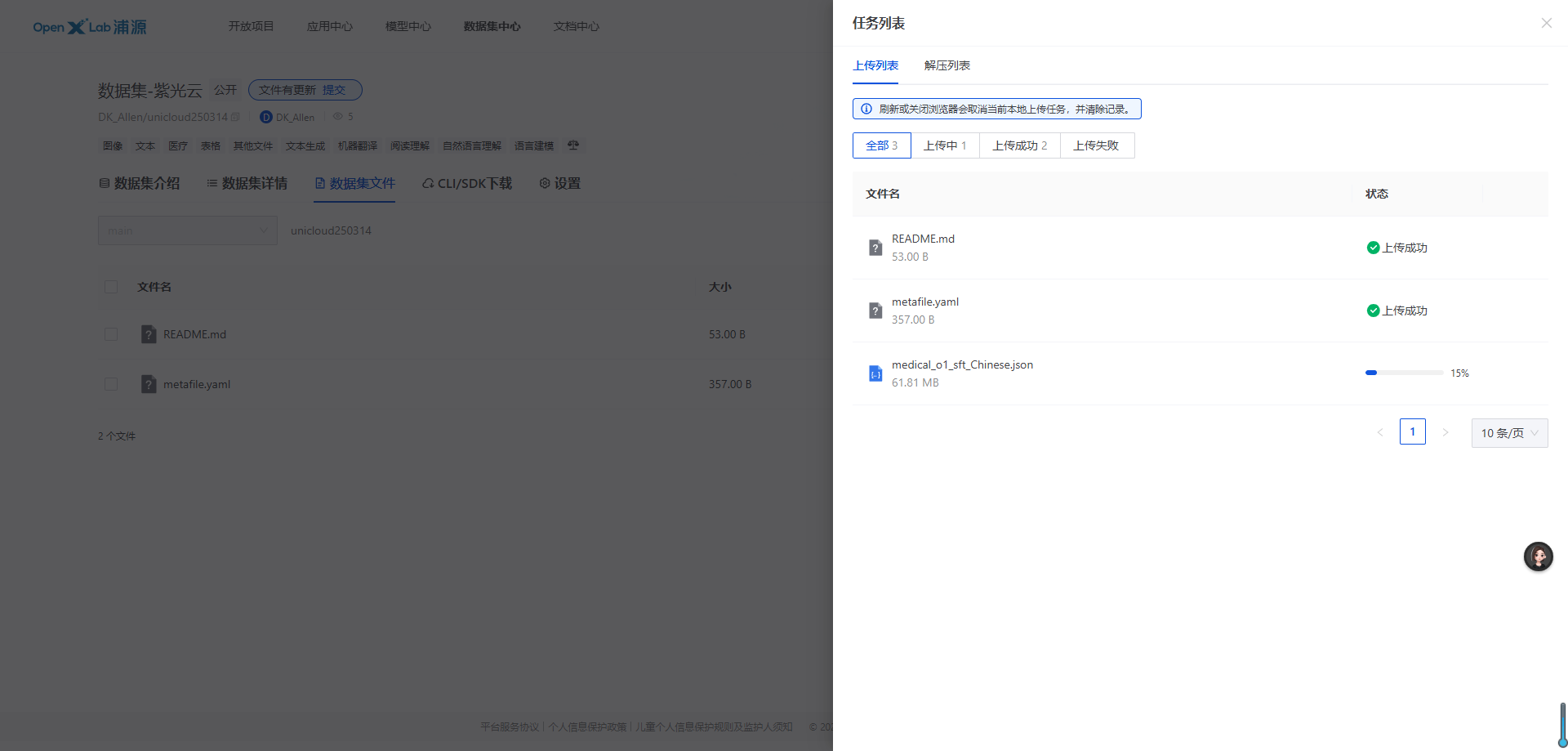
3.2.1 样例数据
该数据集用于微调HuatuoGPT-o1,这是一种专为高级医学推理设计的医学LLM。该数据集是使用GPT-4o构建的,该数据集搜索可验证医疗问题的解决方案,并通过医疗验证器进行验证。
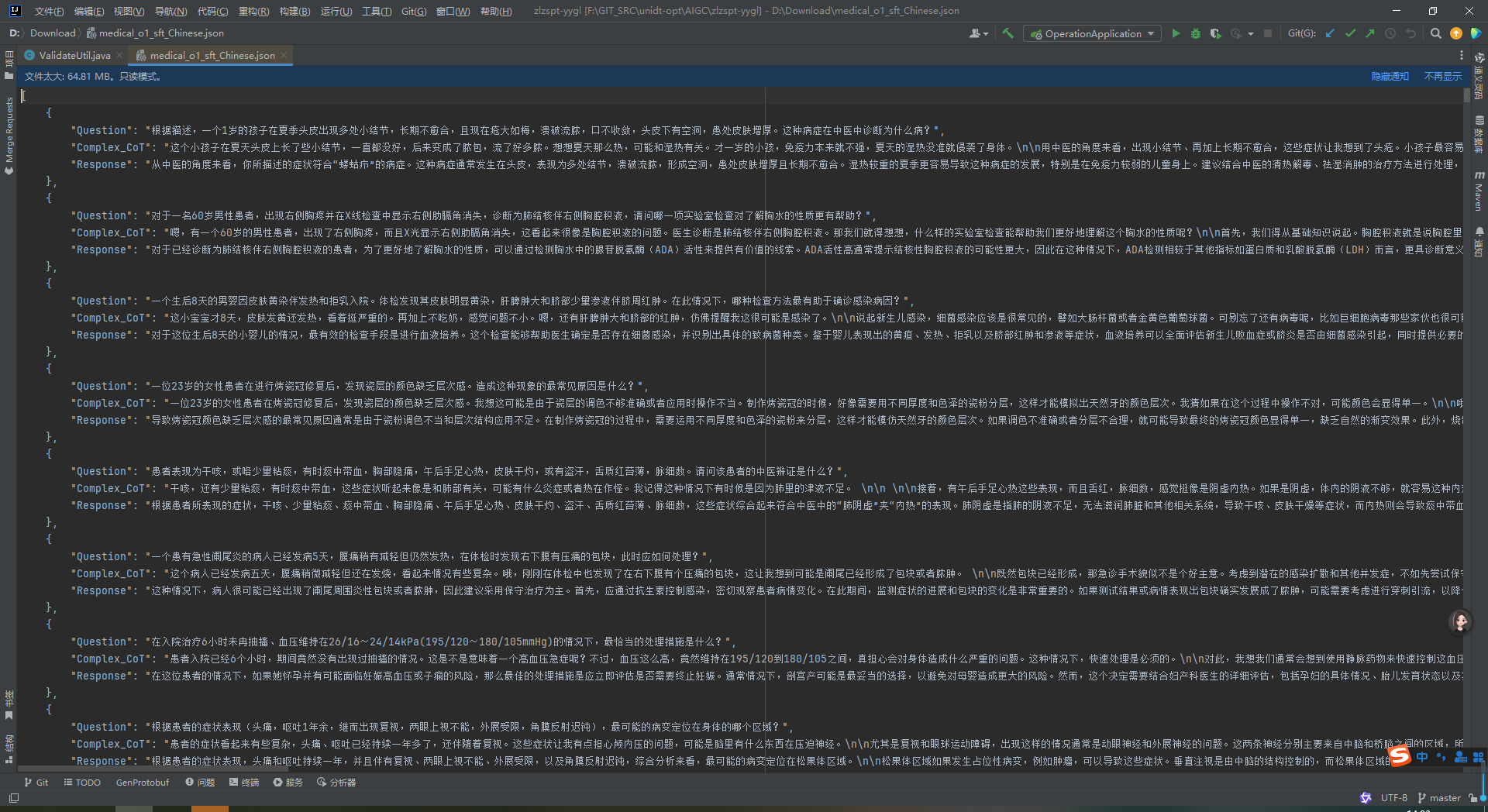
3.2.2 上传方式
本地上传/Github 导入/URL 导入
3.3 发布数据集

4.使用数据集
4.1 数据类型
4.2 专题类型

4.3 任务类型
4.4 标注类型

4.5 使用方式
4.5.1 CLI 下载
pip install openxlab #安装
pip install -U openxlab #版本升级
openxlab login #进行登录,输入对应的AK/SK
openxlab dataset info --dataset-repo DK_Allen/unicloud250314 #数据集信息及文件列表查看
openxlab dataset get --dataset-repo DK_Allen/unicloud250314 #数据集下载
openxlab dataset download --dataset-repo DK_Allen/unicloud250314 --source-path /README.md --target-path /path/to/local/folder #数据集文件下载4.5.2 SDK 下载
pip install openxlab #安装
pip install -U openxlab #版本升级
import openxlab
openxlab.login(ak=<Access Key>, sk=<Secret Key>) #进行登录,输入对应的AK/SK
from openxlab.dataset import info
info(dataset_repo='DK_Allen/unicloud250314') #数据集信息及文件列表查看
from openxlab.dataset import get
get(dataset_repo='DK_Allen/unicloud250314', target_path='/path/to/local/folder/') # 数据集下载
from openxlab.dataset import download
download(dataset_repo='DK_Allen/unicloud250314',source_path='/README.md', target_path='/path/to/local/folder') #数据集文件下载4.6 使用类型

5.最佳实践
5.1 WanJuan2.0(万卷-CC)
5.1.1 数据处理
为充分体现多语言特色、全面提升数据质量与适用性,我们设计了一套精细化的数据处理流程。该流程有效融合多语言特点与行业通识技术,为多语言模型训练提供了高质量、安全可靠的数据基础。
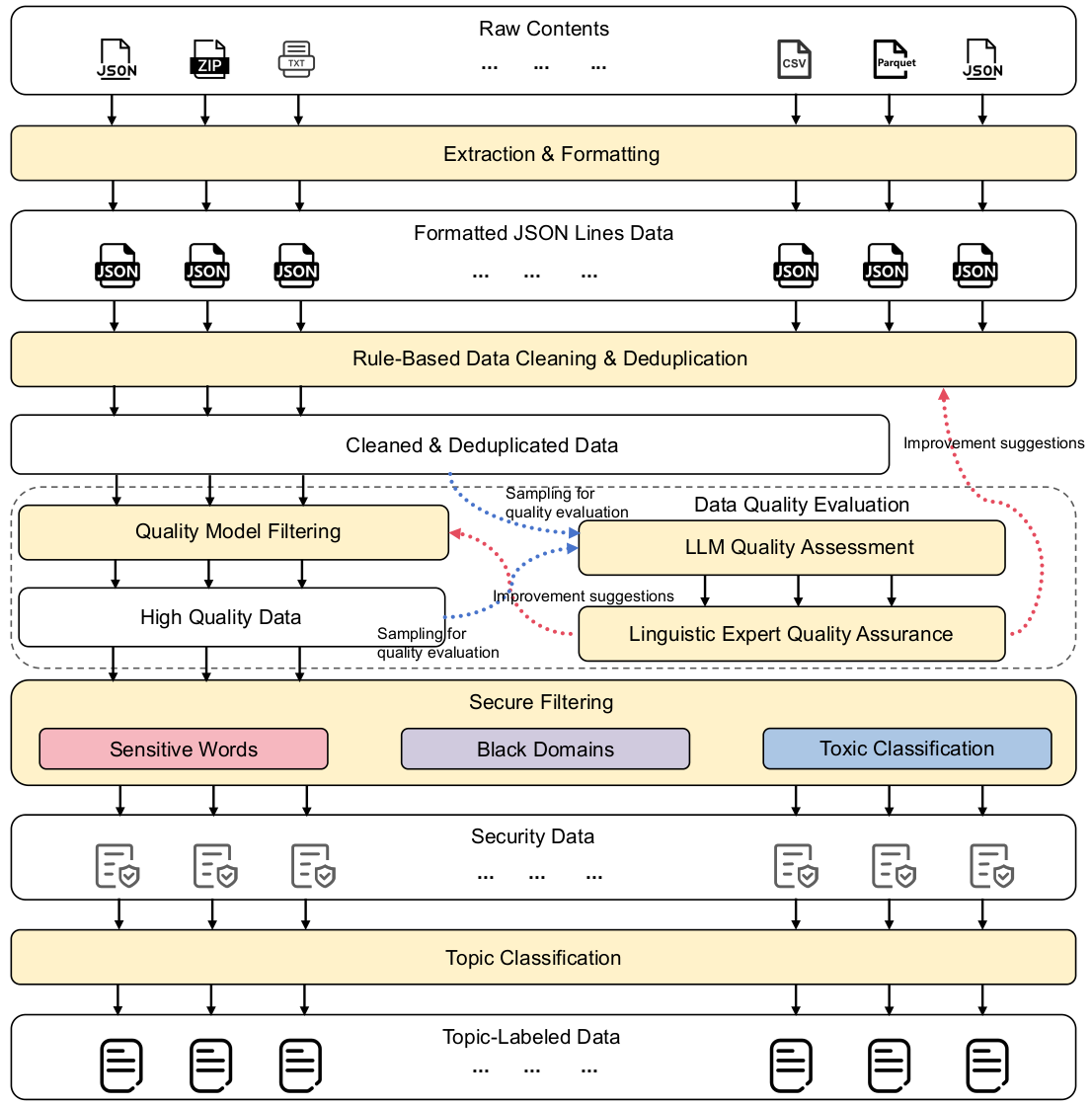
WanJuan3.0数据处理流程图
5.1.1.1 数据抽取与格式化
采用自主研发的文本提取工具从原始网页中抽取核心内容,并规范化为标准的 JSON Lines 格式,然后使用语言检测模型进行语种识别,保留目标语言的数据。
5.1.1.2 数据清洗与去重
采用多维度的启发式规则对数据进行系统性清洗,重点解决多类典型噪声问题,并针对多语言语料的特殊性,处理了特定语言中异常噪声等问题。
5.1.1.3 数据质量
通过基于困惑度(Perplexity, PPL)进行初步筛选和基于 multilingual-BERT 的质量评分模型,对数据进行两阶段的质量筛选,并通过大模型和语言专家评估数据质量。
5.1.1.4 数据安全
建立域名黑名单筛除不良网页数据,构建多语言特色敏感词表并结合语境评估,精准过滤有害内容,同时训练语言安全模型,进行多维度不良内容检测和筛选。
5.1.1.5 主题分类
采用 FastText 模型作为核心分类器, 基于多语言数据标签体系,对数据进行主题分类,优化知识域分布。
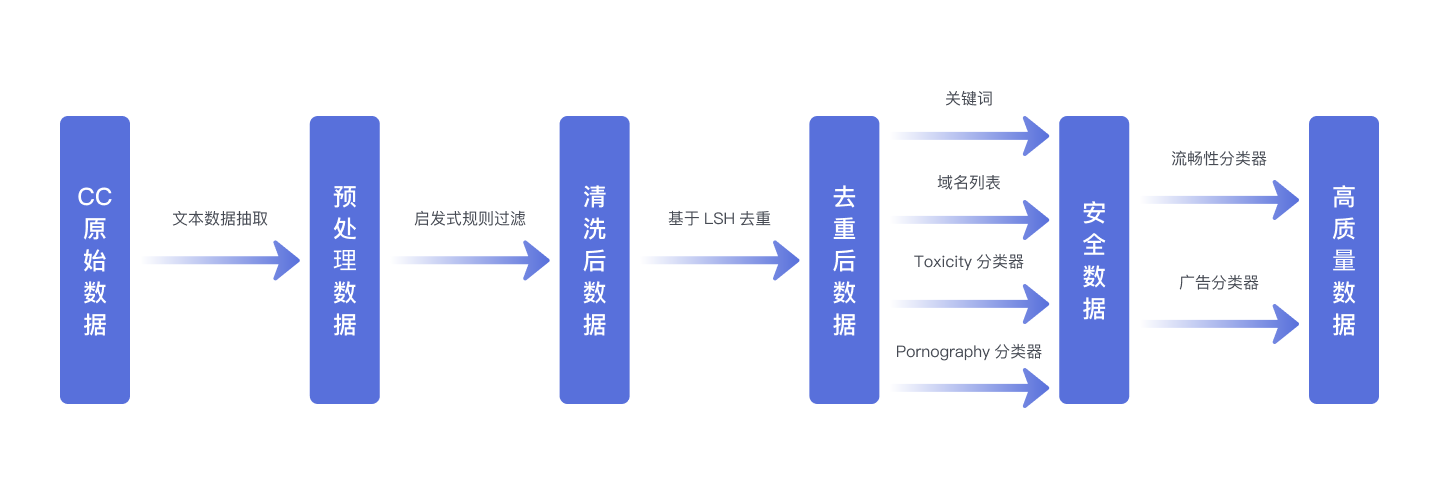
5.1.1.6 数据处理流程图
- 从Common Crawl的WARC格式数据中提取文本,得到"原始数据"(Raw data)。
- 通过启发式规则对原始数据进行过滤,生成"清洗数据"(Clean data)。
- 利用基于LSH的去重方法对清洗数据进行处理,得到"无重复数据"(Dedup data)。
- 使用基于关键词和域名列表的过滤方法,以及基于Bert的有害内容分类器和淫秽内容分类器对无重复数据进行过滤,产生"安全数据"(Safe data)。
- 采用基于Bert的广告分类器和流畅性分类器对安全数据进行进一步过滤,得到"高质量数据"(High-Quality data)。
5.1.2 数据信息
5.1.2.1 基本信息
- 数据模态:纯文本数据;
- 主要语言:英文;
- 数据量:约 100B Tokens;
- 数据格式:以Jsonlines形式存储的语料文本与附加信息。
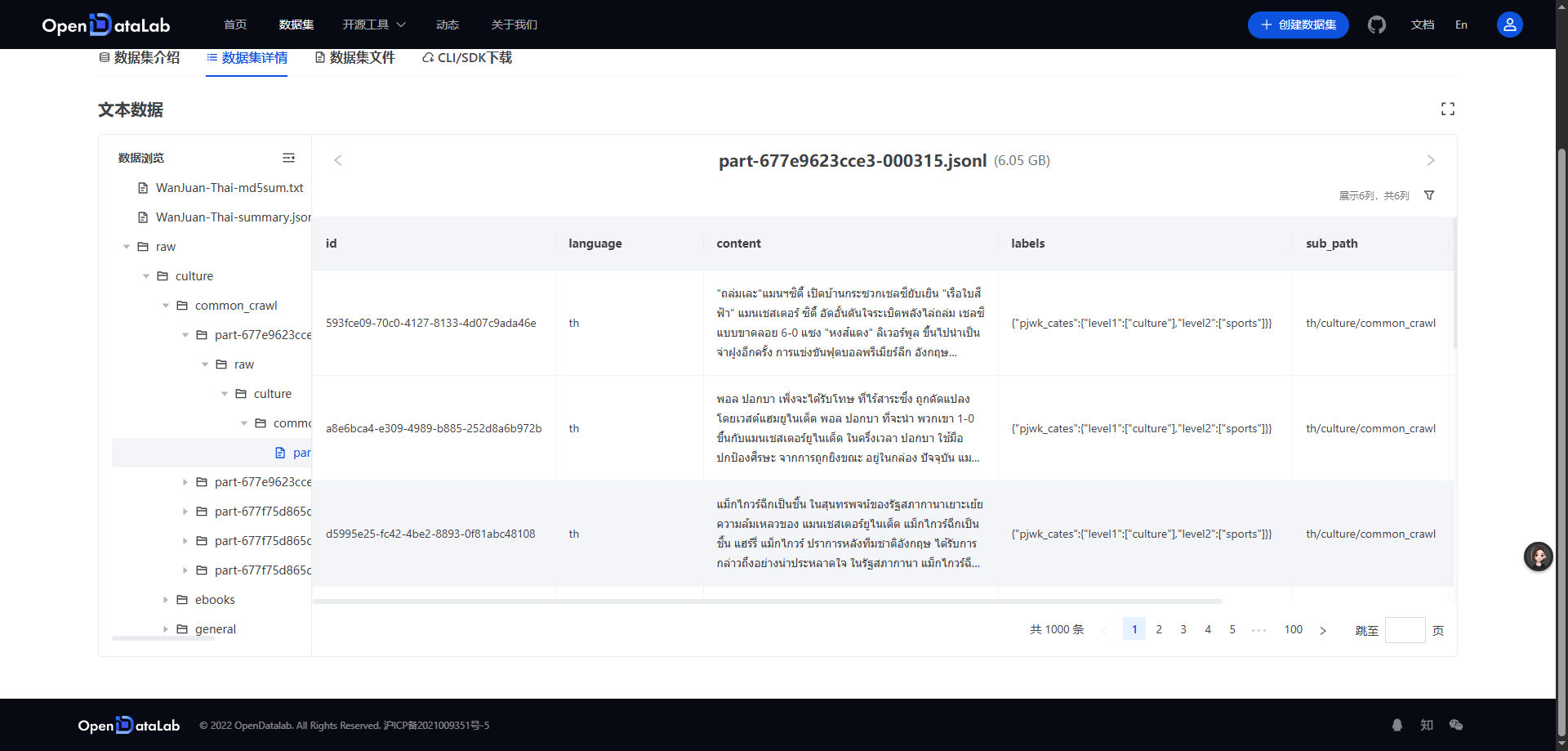
5.1.2.2 数据样例
{
"id": "Bk3aTI85qrqB0ZWjQ26l",
"content": "This year I have been overwhelmed by moving house. The planning and organising has dominated my life: packing and unpacking boxes, trying to keep the family fed and watered, being there 100% for my children to settle in. My life - my aims and goals - have taken second place to the family chaos.\nYesterday, for the first time in ages, I sat down and thought: I want to write my book. I want to get this back into my time schedule. I want to make this space for me, for expressing myself, for being creative.\nSo what happens as of 3.15pm tomorrow? School holidays. Am I really likely to get a moment's peace?\nNow I'm planning: take the laptop on holiday. Work out how to blog from mobile (have to confess this is highly unlikely to work!) Consider booking children into holiday camps for entire 5 weeks. (Would Grannie like them?) Insist on a couple of hours a day, uninterrupted, simply to write.\nOr ... accept the reality. Enjoy the children while they are still prepared to tolerate me. Plan for a solid routine when term starts in September.\nWhich do you think will win?",
"title": "Withenay Wanders: July 2009",
"language": "en",
"date": "2018-06-18T18: 54: 52Z",
"token_num": 244,
"cbytes_num": 1073,
"line_num": 6,
"char_num": 1073,
"toxic_score": 0.001661,
"porn_score": 0.003416,
"fluency_score": 0.998535,
"not_ad_score": 0.981934
}
5.1.2.3 数据字段格式
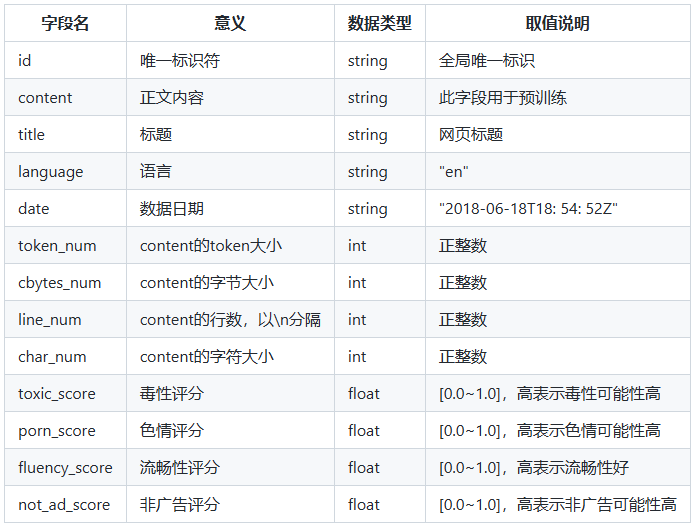
以下表格记录了数据各字段的字段名,意义,数据类型和取值说明:
5.1.3 评估体系
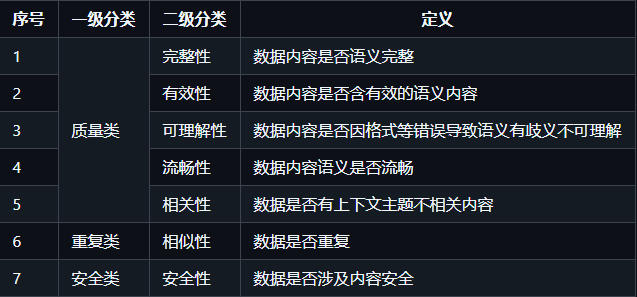
为建立科学的评估体系,我们构建了一个多层级的质量分类框架,将语料问题系统地划分为质量类、重复类和安全类三大维度。质量类问题由于其内在复杂性,进一步细分为相关性、完整性、可理解性、有效性和流畅性五个评估子维度,如下表所示。
5.1.4 许可
WanJuan3.0(万卷·丝路)整体采用 CC BY 4.0 许可协议。您可以自由共享、改编该数据集,唯需遵循以下条件:
署名:您必须适当地标明作者、提供指向本协议的链接,以及指明是否(对原始数据集)做了修改。您可以以任何合理的方式这样做,但不能以任何方式暗示许可人同意您或您的使用。 没有附加限制:您不得使用法律条款或技术措施来限制他人执行许可证允许的任何操作。 完整协议内容,请访问 CC BY 4.0 协议全文。
5.2 紫光云医疗数据处理训练流程
此处为语雀内容卡片,点击链接查看:登录 · 数字化产品部
6.使用WanJuan2.0(万卷-CC)
6.1 数据集核心优势
- 高质量文本:通过多层过滤(安全、流畅性、广告),确保数据无毒性、高流畅性。
- 结构化元数据:包含毒性评分、色情评分、流畅性评分等,支持精细化数据筛选。
- 规模与多样性:100B Tokens,覆盖 2013-2023 年多领域英文网页文本,提升模型泛化能力。
6.2 适用场景
- 大模型预训练:适用于英文基座模型的训练,尤其适合需要高安全性和高效训练的场景。
- 领域适配:支持跨领域知识学习(如学术、新闻、技术文档),通过混合多源数据增强模型泛化能力。
6.3 大模型预训练使用方式
6.3.1 数据预处理
Tokenization:使用主流英文分词工具(如 GPT-2 BPE、SentencePiece),结合token_num字段优化分块策略。
from transformers import GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
max_length = 512 # 根据模型需求调整
def process_text(text):
return tokenizer(
text,
max_length=max_length,
truncation=True,
padding="max_length",
return_tensors="pt"
)动态过滤:
- 根据
toxic_score < 0.1、porn_score < 0.1、fluency_score > 0.9筛选高质量样本。 - 结合
not_ad_score > 0.95排除广告内容。
6.3.2 训练策略
- 混合精度训练:
-
- 使用 PyTorch 的
torch.cuda.amp或 TensorFlow 的tf.keras.mixed_precision加速训练。
- 使用 PyTorch 的
- 分布式训练:
-
- 采用 DeepSpeed、Megatron-LM 等框架支持 100B+ Tokens 的高效处理。
- 学习率调度:
-
- 初始学习率设为
1e-4,使用余弦退火策略逐步衰减。
- 初始学习率设为
6.3.3 模型适配
- 基础架构:适配 Transformer、Llama、GPT 系列等主流模型。
- 增量预训练:对已预训练模型(如 Llama-2)在 WanJuan2.0 上进行增量训练,提升英文能力。
6.4 自然语言处理任务
6.4.1 下游任务微调
- 分类任务(如情感分析):保留
content字段,结合title增强语义理解。 - 生成任务(如文本补全):利用
fluency_score筛选高流畅性样本,提升生成质量。
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForSequenceClassification
dataset = load_dataset("json", data_files="wanjuan_cc.jsonl")
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
def tokenize_function(examples):
return tokenizer(examples["content"], truncation=True, max_length=128)
tokenized_datasets = dataset.map(tokenize_function, batched=True)6.4.2 检索增强生成(RAG)
- 构建向量索引:使用 Milvus 或 FAISS 存储
content的 Embedding,结合title和date优化检索。 - 动态检索:在生成时通过余弦相似度检索相关文档,增强模型上下文理解。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Milvus
embeddings = OpenAIEmbeddings()
vectorstore = Milvus.from_documents(documents, embeddings)6.4.3 安全能力强化
- 毒性过滤:结合
toxic_score和porn_score训练分类器,过滤不安全输出。 - 提示词优化:使用
fluency_score高的文本生成提示模板,提升输出流畅性。
6.5 大模型训练全流程
6.5.1 数据加载与清洗
- 使用
jq或 Python 读取 JSONL 文件,过滤低质量样本。
6.5.2 Tokenization 与分块
- 按
max_length=4096(如 Llama-3)分块,保留token_num字段验证。
6.5.3 训练配置
- 批量大小:2048(根据 GPU 显存调整)。
- 训练轮数:100-200 epochs(根据任务需求)。
6.5.4 评估与验证
- 使用
PPL(困惑度)评估语言模型性能,对比tiny-stories等验证集。
6.5.5 模型保存与微调
- 保存中间 Checkpoint,用于领域特定任务(如法律、医疗)的二次训练。


















 252
252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









