







失踪博主前来打卡啦?
最近看了一些CVPR2019上关于三维人体姿态估计(3D human pose estimation)的文章,3D human pose estimation的任务简单来说是,给定一段RGB视频或者RGB图片,估计它在三维空间的姿态。
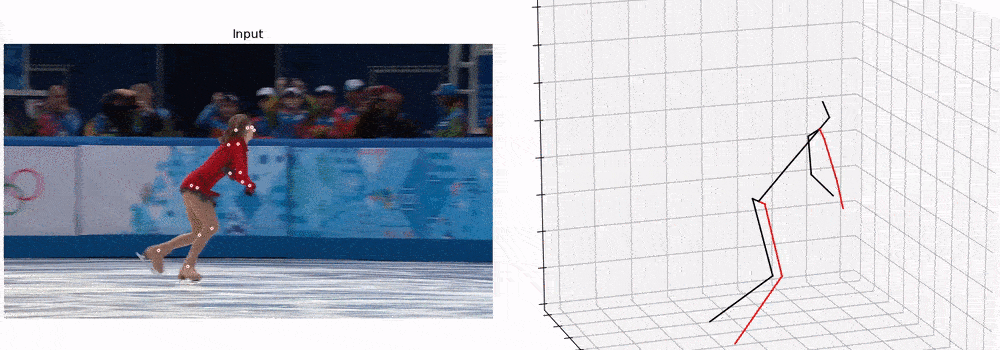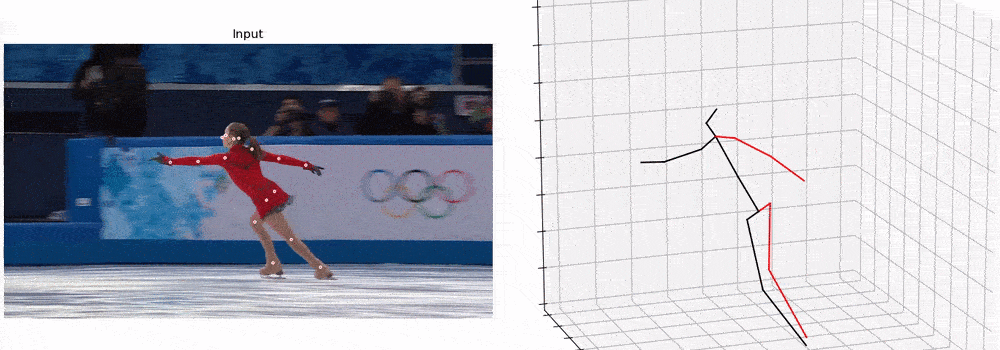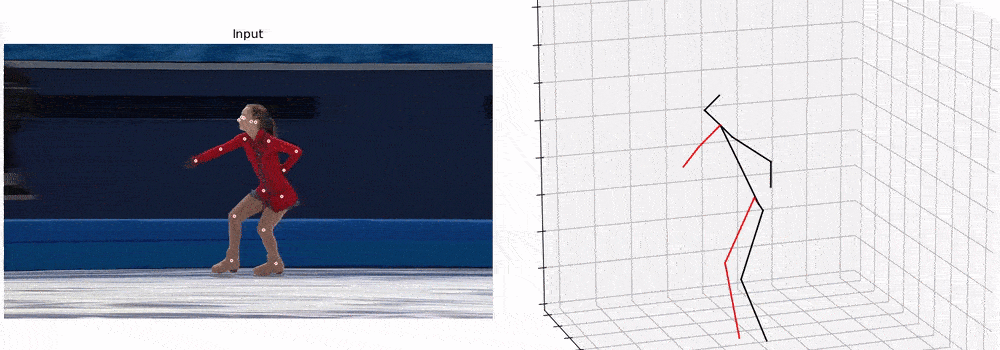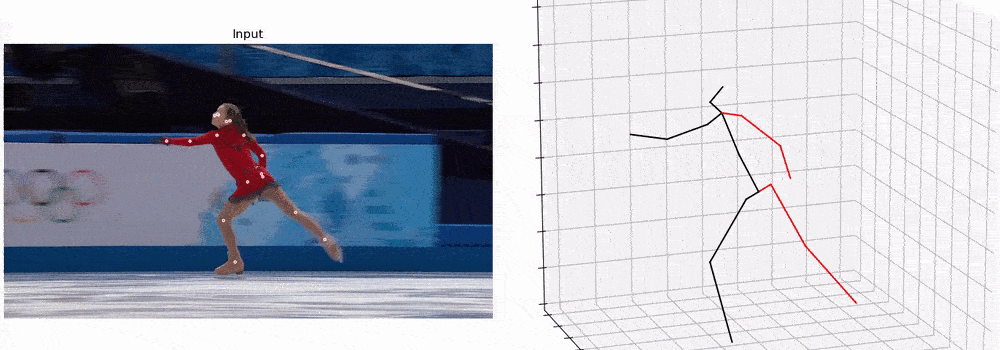
后续也可以做这样一些任务,包括虚拟现实和行为识别等。

现在从场景可以分为室内(indoor)和野外(in the wild),还可以分为single view(单一视角)和multi-view(多视角)。现在几种主要的研究方法包括以下几种:
(1)3D pose from 2D keypoint detection:
这种方法也可以称为两阶段检测(two step pose estimation):
- 先从图像空间(image space)中检测二维关键点(2D keypoints)
- 再从2D 提升到 (lift to) 3D,这一步还是比较简单的,用一个简单的神经网络就能学习2D 到3D 的表示
这一方法需要用全监督或者其他的信息,包括相机的内外参等。
(2)Direct 3D pose estimation
现在用半监督,无监督,弱监督(这算一个类别吗?感觉它就是半监督?。。。),还有自监督(这不就是无监督吗?)用English就是我们在CVPR2019看到的semi-supervised, weakly or unsupervised learning, and self-supervised learning.
这些方法总的来说,就是用了encoder-decoder结构,主要是为了学习一个3D 结构化表示,给一个视角下的一张照片,能够预测出来在另一个视角下的图片(predict one image seen from one viewpoint from one image captured from a different viewpoint)
最近,Middle East Technical University 在CVPR2019发表了一篇关于自监督学习的3D HPE的文章《Self-Supervised Learning of 3D Human Pose using Multi-view Geometry》,在这里分享一些阅读笔记,帮助自己理解,欢迎大家多多交流~
主要方法–训练
这篇文章主要提出了EpipolarPose, 能直接从单张图片预测3D 人体姿态。训练时,不需要任何3D 监督或者相机外参,它利用对极几何(Epipolar Geometry)和2D 的姿态信息来得到3D 姿态。
它的训练过程如下:
有n个相机(n>=2)同时对场景中的某个人拍照,相机能同时产生
I
1
,
I
2
,
.
.
.
,
I
n
I_1, I_2, ... , I_n
I1,I2,...,In张图片,下标代表相机的编号。
训练的流程图如下所示:

从图中可以看出来,有两个分支(上分支是3D branch,下分支是2D branch),他们有一样的姿态估计网络(结构一样),都是先用ResNet 做backbone,再接上一个反卷积网络。当n=2,也就是2个相机时,每个训练样例包括了两张图片(
I
1
,
I
2
I_1, I_2
I1,I2), 这两张图片再被送进两个网络(也就是上下两个分支)分别得到volumetric heatmaps (
H
^
,
H
∈
R
w
×
h
×
d
\widehat{H}, H\in\mathbb{R^{w\times h \times d}}
H
,H∈Rw×h×d ),经过soft argmax activation
φ
(
⋅
)
\varphi(\cdot)
φ(⋅) 后得到了一个3D pose
V
^
\widehat{V}
V
和2D pose
U
U
U。文章说,对于任何一个volumetric heatmap,我们都能得到3D pose
V
^
\widehat{V}
V
和2D pose
U
U
U。
文章一开始就说他们是self-supervision,体现在哪里呢?作者说是 “It creates its own 3D supervision by uti- lizing epipolar geometry and 2D ground-truth poses”。也就是说,这里的
U
U
U就被认为是2D ground truth,所以他们接下来引入了一些几何知识,通过triangulation,得到在全局坐标系中的3D ground truth —>
V
V
V, 然后就在
V
V
V和
V
^
\widehat{V}
V
计算Loss,进行监督训练等等等。
这个triangulation的计算流程又是什么样呢?用到了一些相机模型的知识,采用的是针孔相机模型。第 i i i 张图片里的第 j j j 个关键点的2D坐标为 U ( i , j ) = ( x i , j , y i , j ) U(i, j) = (x_{i, j}, y_{i, j}) U(i,j)=(xi,j,yi,j),它的3D坐标为 ( X j , Y j , Z j ) (X_j,Y_j, Z_j) (Xj,Yj,Zj)。用针孔相机模型描述它们之间的关系为:
[
x
i
,
j
y
i
,
j
w
i
,
j
]
=
K
[
R
∣
R
T
]
[
X
j
Y
j
Z
j
1
]
\left[ \begin{matrix} x_{i, j} \\ y_{i, j} \\ w_{i, j} \end{matrix} \right] = K[R|RT] \left[ \begin{matrix} X_j \\ Y_j \\ Z_j \\ 1 \end{matrix} \right]
⎣⎡xi,jyi,jwi,j⎦⎤=K[R∣RT]⎣⎢⎢⎡XjYjZj1⎦⎥⎥⎤
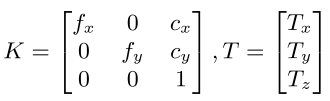
K代表相机内参,R是旋转矩阵,T是平移矩阵。
在动态捕捉的环境中,相机的外参矩阵(R, T)通常是不可知的。假设第一个相机位于坐标系的中心。对于
U
i
U_i
Ui和
U
i
+
1
U_{i+1}
Ui+1中对应的关键点
j
j
j。
对任意一个j,矩阵F都能满足
U
i
,
j
F
U
j
+
1
,
j
=
0
U_{i, j}FU_{j+1, j} = 0
Ui,jFUj+1,j=0。F通过RANSAC算法(随机抽样一致算法,采用迭代的方式从一组包含离群的被观测数据中估算出数学模型的参数)计算得到。我们再通过矩阵F计算E:
E
=
K
T
F
K
E=K^TFK
E=KTFK。再通过SVD对矩阵E进行分解,能得到旋转矩阵R的四个近似解。作者通过手性检查(cheirality check,一种对称特点)来确定近似的解。
对合成的2D图像,为了得到它的3D pose,作者采用对极几何求解。因为(
I
i
,
I
i
+
1
I_i, I_{i+1}
Ii,Ii+1)里的关键点都没有被遮挡,所有使用polynomial triangulation对3维坐标点(
X
j
,
Y
j
,
Z
j
X_j, Y_j, Z_j
Xj,Yj,Zj)进行triangulation。
为了计算由在相机空间中的3D pose
V
^
\widehat{V}
V
间的损失,作者把
V
V
V投影到相应的相机空间,这样就可以最小化(
V
V
V,
V
^
\widehat{V}
V
)间的损失。
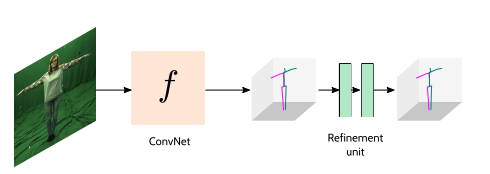
Inference推理
上图所示橙色的部分即为推理的部分。输入是单张图片,输出是3D姿态( V ^ \widehat{V} V )
整个自监督模型还加入了修正单元(Refinement Unit),它的输入层能够从EpipolarPose中得到的含有噪声(不那么理想)的3D 姿态。下图所示是整个推理流程,RU 是一个可选的步骤来修正训练模型产生的预测结果。这里的训练的 f f f正是图1中橙色的部分。
Pose Structure Score
作者认为本文的另外一个贡献是提出了一个新的评价指标
P
S
S
PSS
PSS,他们认为可以在今后的研究中也采用这个指标。
为什么要提出PSS呢?如下图所示,作者认为传统的距离评价指标(MPJPE和PCK)将每个关节点独立地看待,例如,有些姿势和Reference Pose间有相同的MPJPE,但是他们在结构上完全不同。中间的姿态1和右边的姿态看起来完全不一样,但用传统的评价指标评判时,它们是一样的。
所以作者提出了一个新的评价标准姿态结构得分( Pose Structure Score),不光去计算各关键点之间的距离,还去衡量整个姿态的结构合理性。

如何计算PSS?
计算PSS需要ground-truth姿态的一个参考分布(reference distribution)。假设有
n
n
n个pose
q
i
,
(
i
∈
1
,
.
.
.
,
n
)
q_i, (i \in {1, ... , n})
qi,(i∈1,...,n)。作者将每个姿态向量都进行标准化
q
i
^
=
q
i
∣
∣
q
i
∣
∣
\widehat{q_i} =\frac{q_i}{||q_i||}
qi
=∣∣qi∣∣qi。作者再利用K-means聚类计算了
k
k
k个聚类中心
μ
j
,
(
j
∈
1
,
.
.
.
,
k
)
\mu_j, (j \in {1, ... , k})
μj,(j∈1,...,k)。文章采用如下公式计算预测的姿态p和ground-truth q之间的PSS:
P
S
S
(
p
,
q
)
=
δ
(
C
(
p
)
,
C
(
q
)
)
C
(
p
)
=
arg
min
k
∣
∣
p
−
μ
k
∣
∣
2
2
δ
(
i
,
j
)
=
{
1
,
i
=
j
0
,
i
≠
j
PSS(p, q) = \delta(C(p), C(q)) \\ C(p) = \mathop{\arg\min}_k||p-\mu_k||_2^2\\ \delta(i, j)=\begin{cases}1,& i = j \\ 0,& i \neq j \end{cases}
PSS(p,q)=δ(C(p),C(q))C(p)=argmink∣∣p−μk∣∣22δ(i,j)={1,0,i=ji=j
下图展示了姿势和聚类的t-SNE图。每一个颜色代表一个聚类(pose),这里展示了10个聚类。
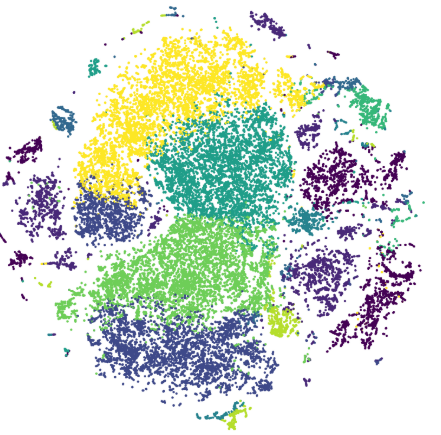
下图展示的是Human3.6M中的一些经典姿势的聚类中心,k=50。

实验细节
作者采用ECCV2018的IntegralPose为代码框架,并且采用ResNet-50为backbone。输入图像和输出heatmap的尺寸大小分别为:
256
×
256
256\times256
256×256,
J
×
64
×
64
×
64
J \times64\times64\times64
J×64×64×64。
J
是
关
键
点
数
量
J是关键点数量
J是关键点数量。
对于两个相机,batch-size为32,每个包含
I
i
,
I
i
+
1
I_i, I_{i+1}
Ii,Ii+1的图像对。网络训练140,优化器采用Adam,初始学习率为0.001,在第90步和120步的时候调整学习率。采用随机旋转和尺度变化来做数据增强。
实验结果
- 数据库: Human 3.6M, MPI-INF-3DHP
- Metrics: MPJPE, PCK, PSS
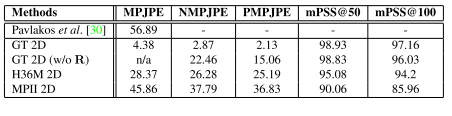
Can we rely on the labels from multi view images?
表1 H36M的triangulation的结果
GT表示用H36M中的2D标签,GT 2D (w/o R)表示不用camera geometry(旋转矩阵R) H36M 2D 和MPII 2D表示在这些数据集上训练的姿态估计模型。我们可以看到,用GT 2D的效果最好,其次是H36M 2D,而在MPII数据集上训练的2D keypoints 检测器有轻微的效果下降。作者认为是因为H36M中的数据是用marker得到的,更准确(H36M中数据集中的试验者在身上贴有小亮片(传感器))。而MPII中人的关键点是由人工标记的,一些关键点定位不准。
Comparison to State-of-the-art
在H36M上和其他SOTA比较的结果如下表所示:


EpipolarPose在H36M上最好的结果能达到60.56mm(MPJPE)。
Weakly/Self Supervised Methods
下表展示的是文献中一些关于weakly or self supervised方法在Human 3.6M上的结果。
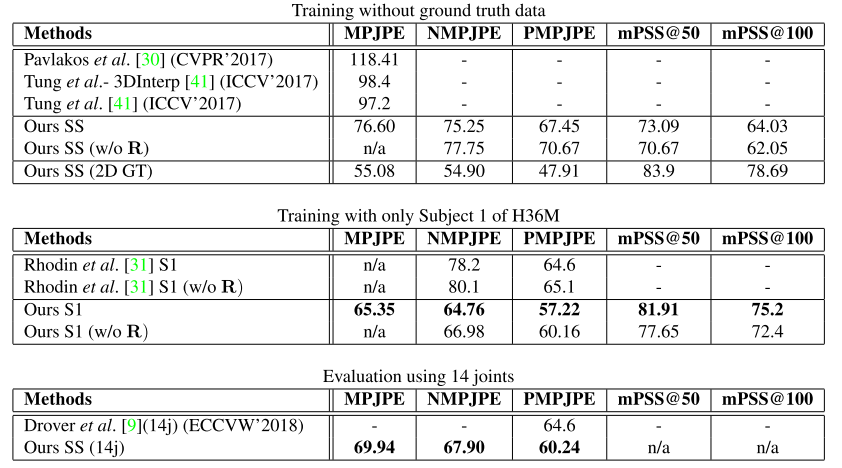
可以观察到GT2D训练和MPII预训练之间存在很大差异(76.60 - 55.08 = 21mm)。这个差距表明2D关键点的估计质量对于3D pose estimation取得更好的性能至关重要。
底下的两个表展示的是和参考文献31与9更公平和细致的比较。
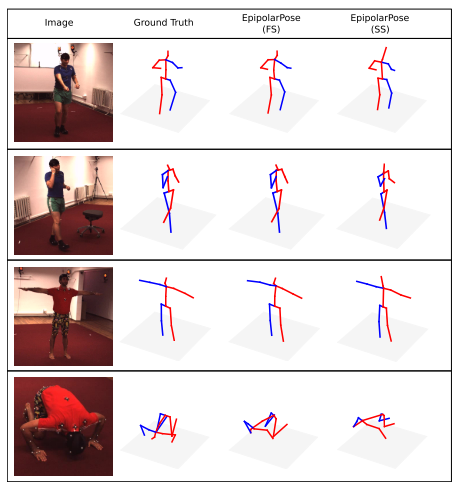
定性结果展示
总结
在这个工作中,作者展示了就算没有ground-truth和相机外参,多视角的图像能被利用来做自监督。这个方法的核心就是利用了多视角的2D pose + 对极几何来推理出3D姿态。作者还提出了一个新的评价标准PSS,以后可以在文章中采用。
思考
我现在看的文章还不多,也就是把近几年的各方面的文章看了一点,还是要多读paper,看顶会上的文章还是能带给我很大的启发。
我发现 现在的文章大都是semi,un,weakly supervised,我觉得还是auto encoder和decoder比较有趣。另外,现在这些几何知识也是我最近需要着重去学的,我还没自己实现过epipolar geometry,相机空间变换等,cry?…















 985
985











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









