







弱监督任务就是原本没有标签,所以通过一定的方法构造出伪标签作为Ground Truth来监管训练,通常是交替迭代训练,即一边训练网络完成预测,一边又用该预测结果作为新的Ground Truth来训练网络.
1.《Learning to Detect Salient Objects with Image-level Supervision》
网络结构图如下:
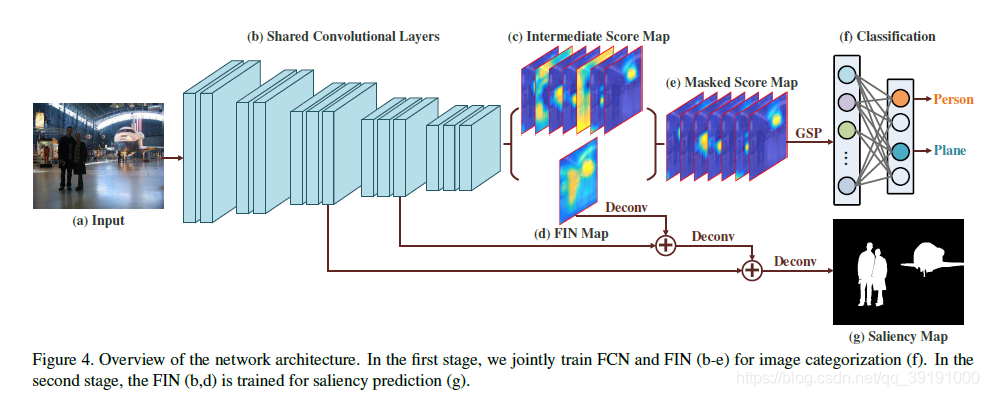
(1)第一阶段,训练FCN网络完成分类任务,同时得到初始Saliency map 作为第二阶段的初始Ground Truth.
在这一阶段的关键创新点就是Intermediate Score map 与 FIN Map(Foreground Saliency map) 作 element-wise multiplication
该步骤巧妙的将image classification任务和salience detection 任务结合起来。image classification 可以得到每个类别的响应图,而saliency map 应该是多个显著类别的响应图集合。所以,作者将这两者相乘,得到masked score map, 经过gsp 得到分类概率,实现多分类任务,通过不断的训练(image-classification label 的监管),相乘的F map 逐渐学会响应图片中出现的多个类别,这样相乘后的Masked Score Map 的正确类别才会继续保持响应甚至得到增强,不相干类别继续不响应甚至被抑制,多分类任务才得以正确完成。换句话说,经过image-classification 分支的训练,F map逐渐学会对图片中显著物体的响应。
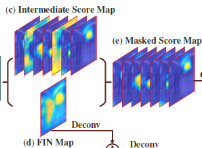
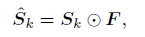
the foreground saliency map F ∈ Rn×n and score map S ∈ Rn×n×C ,Sk denotes the k-th channel of score map S. 通过相乘,得到masked score map. 后接global smooth pooling, 得到概率预测,实现多分类预测任务。(不同于global max pooling 和 global average pooling, 详情见论文)
注意:在分类任务训练过程中,F会很容易学会一种投机取巧的方式,就是对所以位置全部施加响应,这样F就形同虚设了,为了杜绝该现象产生,施加额外的稀疏正则项限制,如下所示:第一项鼓励F对显著前景高响应,第二项抑制F对不显著背景响应。
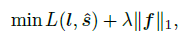
(2)第二阶段:self-training
交替执行 saliency map(FIN map) 估计 和 用估计的map作为ground truth 训练FIN 推断网络。 为了得到更准确的saliency map. 使用新的CRF机制来迭代refine和bootstrapping loss来train,详情见论文。
2.《Multi-source weak supervision for saliency detection》-----CVPR2019
网络结构图如下:
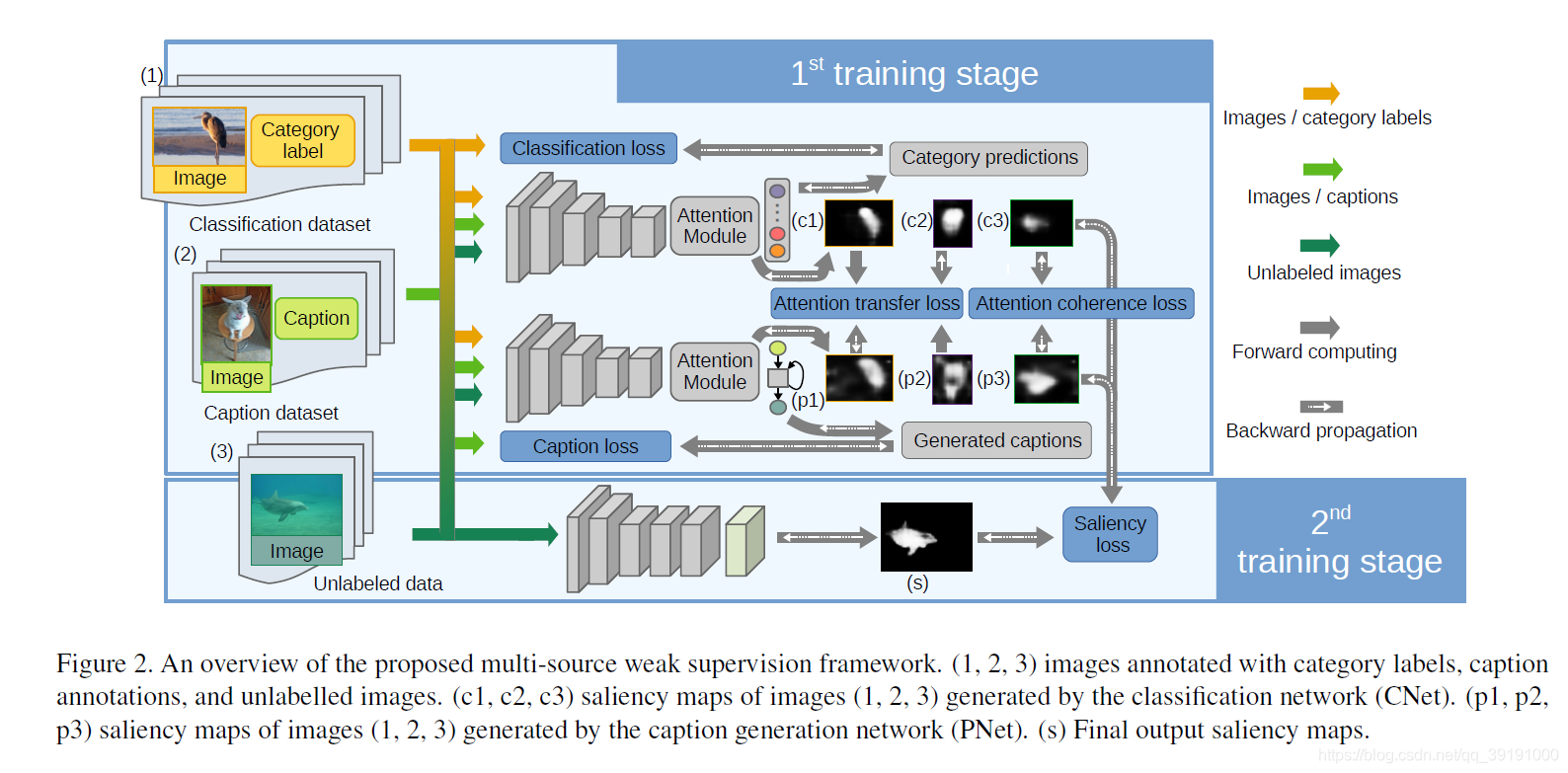
CNet, PNet, SNet三大模块分别针对image classification, image caption, saliency map prediction 任务,3种weak-source 输入数据(category label data,caption label data,unlabeled data)互相辅助完成显著物体预测。
Training第一阶段:使用以下4个loss 训练CNet, PNet. 输入包括三种weak-sorce data.
(1)classification loss: 主要针对分类任务及其给出的预测图。
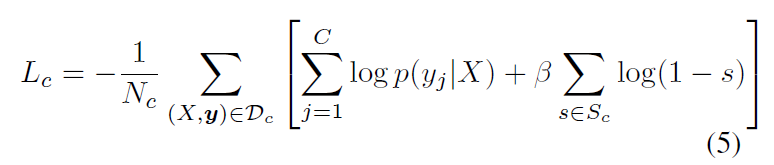
(2)cation loss: 主要针对标题任务及其给出的预测图。
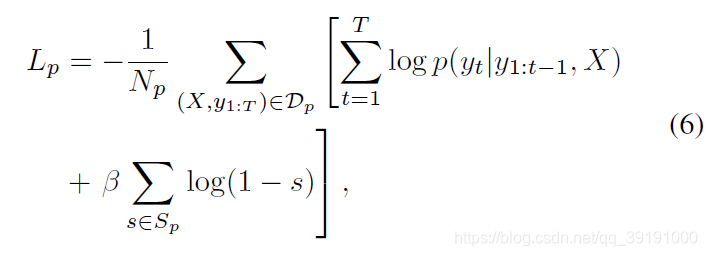
(3)attention transfer loss: 主要使两个网络互相利用对方的salience map当做自己的监督信息。这样两个网络可更好的相互扶持,提升整体效果。
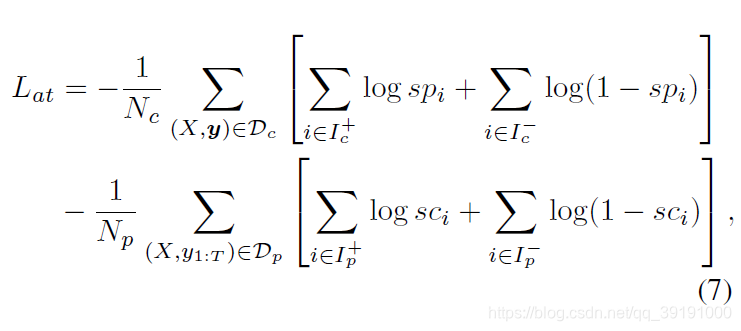
(4)attention coherence loss:针对unlabeled data, 使用该loss 用于使CNet, PNet 生成更general的 显著预测图,而非task-specific 的预测图。具体参考论文。
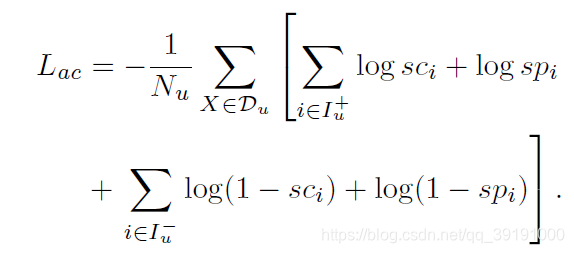
第一阶段整体loss如下:
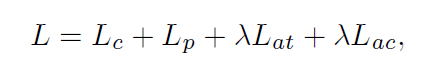
Training第二阶段:输入为unlabeled data, 使用第一阶段训练好的CNet, PNet给出相应pseudo ground truth 用于监管训练SNet。
具体给出pseudo ground truth 的方法为使用crf average CNet,PNet的限制图,然后使用双线性插值resize 到原图尺寸。
S为SNet 预测,Y为伪标签。
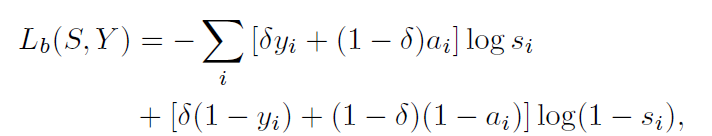
Test阶段:
只使用SNet 给出输入数据的显著预测图。
3.《Deep Unsupervised Saliency Detection: A Multiple Noisy Labeling Perspective》----CVPR2018
网络结构图如下:
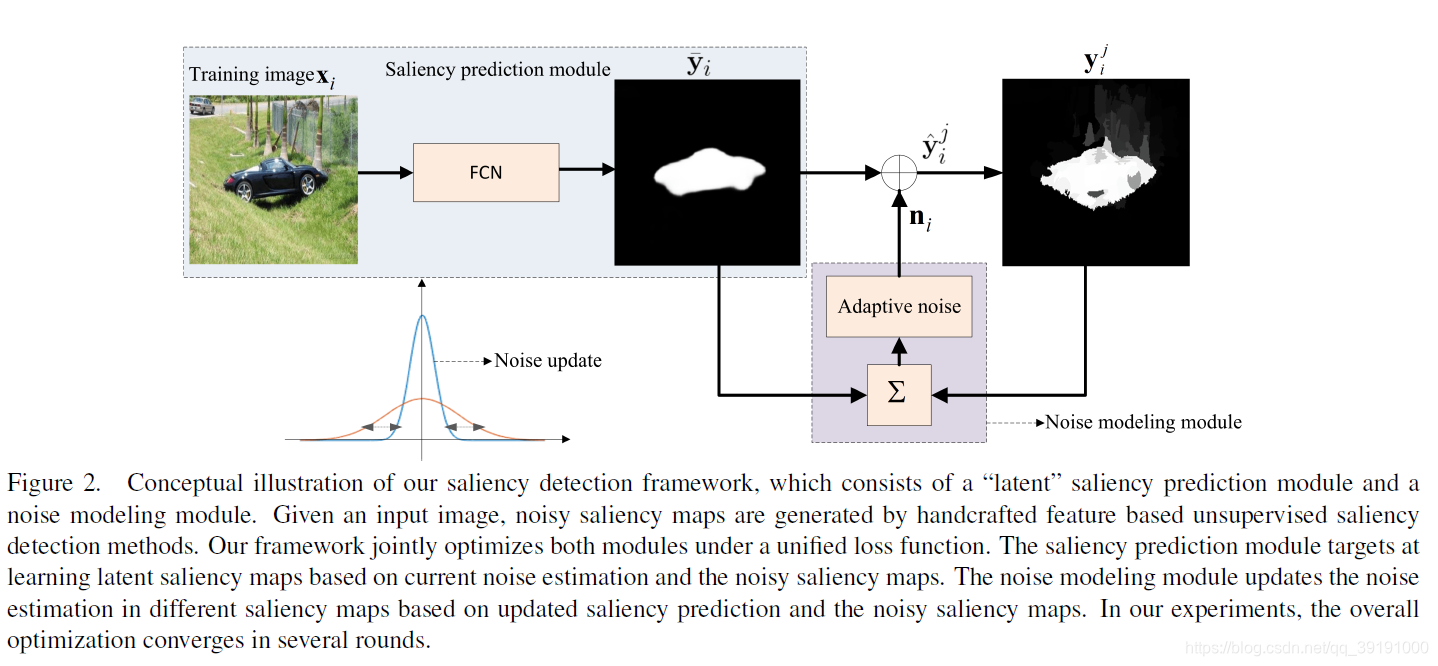
通过现有的unsupervised method 给出noisy saliency map. 将对noisy saliency map 的学习建模成
noisy saliency map=saliency prediction output + noisy
利用noisy saliency map 来训练优化prediction模块和noise distribution模块。最终测试阶段,prediction模块给出的预测即为最终的显著预测图。
该方法,将noise 拆分出来,可最大程度上利用unsupervised saliency map 信息,同时减轻其noise影响。















 2014
2014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









