







支持向量机
一 简介
支持向量机(SVM)有严格的数学基础和推导理论的模式识别方法,是针对小样本的的统计学理论,基于结构风险最小化原则,算法在优化过程中具有全局最优解,泛化能力也比较突出,是一套优秀的机器学习技术。
1 鸡汤在先
机器学习是一个不断学习发展加深的过程,正如一个读书人学习SVM的时候,他看书的境界分为三层,如先读
数据挖掘导论,而后他觉讲得太浅,于是去读
支持向量机导论,甚而,他觉还是不够,于是他去读数据挖掘中的
新方法:支持向量机,最后,他又会觉得纸上终觉浅,于是他会
尝试去证明它,再继续,他会去
写代码如何实现他,然后到了某一天,他还是觉得不够,他总觉得这个算法哪里
有缺陷,然后他想着怎么才能去优化他,他甚至会幻想某一天,他也能
发明创造出这样一个算法,就好了。
引用自CSDN博主JULY的原话
2 分类方法背景
随着机器学习时代的到来,越来越多的学习算法莺歌燕舞,在这样的一个大背景下,分类作为数据挖掘中一项必要的工作,对于其判别的方法,心中要有一个评判标准去衡量一套算法的优劣(追寻的4个标准):
(1)模式的
简洁度(一个好的算法,模式是最为重要的,是其深入下去并取得突破的基础)
(2)预测的
准确度(预测结果是我们最关心的问题,准确度保证是前提)
(3)计算的
复杂度(在时间和空间上计算复杂度)
(4)应用的
泛化度(在应用上的呈现)
在这样的背景下,对于机器学习领域分类方法的研究,我做了一下分类(根据监督在学习过程中参与方式):
(1)监督学习:
Logistic回归(LR)、反向传播的神经网络(BPNN)
(2)非监督学习:
Apriori算法、K-means算法
(3)半监督学习:
图论推理算法(Graph Inference)、拉普拉斯支持向量机(Laplacian SVM)
(4)强化学习:与环境的交互学习(QL)
本博客主要针对支持向量机的方法进行相关的阐述。
3 应用及意义
关于支持向量机的应用,一年前,最初接触支持向量机是为了解决打印字体的光学字符识别(OCR),分类类别包括:0-9、A-Z。下面主要针对应用介绍:
(1)手写字体数字识别
(2)文本分类:邮件过滤、Web挖掘、信息检索
(3)图像分类
(4)其他领域:语音信号、信息安全、时间序、核方法
二 logistic分类器
线性分类器:在高维的数据输入空间中,寻找到一个具有分类的超平面,使得高维输入数据分隔最大。
Logistic回归:简单的0/1分类模型,输入空间的取值范围为(-∞,+∞),对应映射到输出空间的取值范围为(0,1)。

通俗的可以认为:logistic可以将大范围高维度的输入数据表征为小范围低维度的输出分类,可以用下面的公式来表示特征被分类为:y=1的概率:
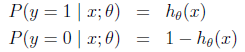

















 165
165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









