






1. 前置学习
- 在学习gcc的内嵌汇编语法前,建议先了解C语言函数的调用规范,达到能使用汇编写出可供C语言安全调用的函数 以及 使用汇编安全调用C语言,如下是arm架构的过程调用标准:
AAPCS(Procedure Call Standard for the Arm® Architecture) - 大致了解C语言的编译流程。
2. 官方手册的大致浏览
gcc的内嵌汇编是gcc扩展语法的一部分,应阅读gcc官方文档 第6.47章,下面是目录的截图。

如下是对各个目录的简要说明,建议先看一下官方手册:
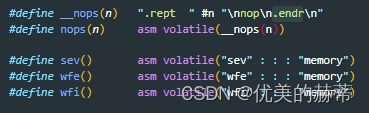
6.47.1 基本的内嵌汇编语法,不含操作数(operands),一般用于运行时对上下文没有影响的指令,如nop指令。
6.47.2 扩展的内嵌汇编语法,包含操作数(operands)。
6.47.3 扩展的内嵌汇编中操作数的约束条件。
6.47.4 控制变量/函数编译后(汇编文件中)符号命名的语法。
6.47.5 指定变量与固定寄存器绑定的方法及注意事项。
6.47.6 gcc在编译阶段获得内嵌汇编大小的机制。
3. gcc内嵌汇编语法速览
本章会提供一些内嵌汇编的示例,有兴趣可以先搜一些gcc内嵌汇编的语法学习一下,本文不会详细介绍基础语法。
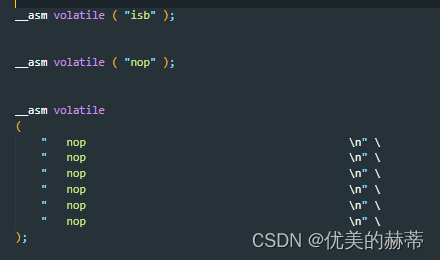
3.1 Basic Asm - 不带操作数的内嵌汇编语法
- 语法描述

- 示例

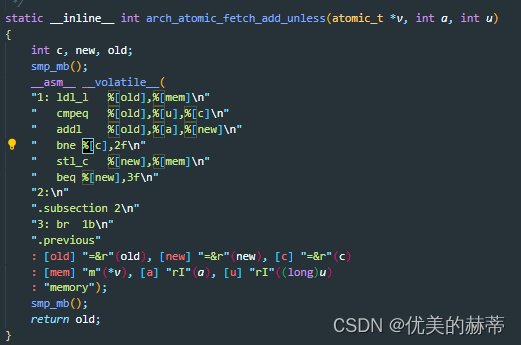
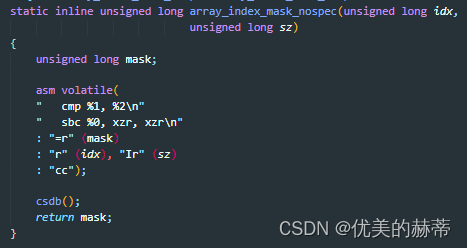
3.2 Extended Asm - 带有C表达式操作数的内嵌汇编指令
-
语法描述

-
示例
3.3 控制c语言中的符号编译为汇编代码后的名字
int foo asm ("myfoo") = 2;
int func (int x, int y) asm ("MYFUNC");
int func (int x, int y)
{
/* . . . */
}
3.4 为变量指定寄存器的语法
register int *foo asm ("r12");
register int *p1 asm ("r0") = ...;
register int *p2 asm ("r1") = ...;
4.核心 - gcc是如何处理内嵌汇编代码的?
在编译阶段(将C语言编译成汇编的阶段),编译器是不会解析内嵌汇编指令的,而是将内嵌汇编看做一个字符串直接传递下一个阶段,由汇编器解析。
编译阶段仅仅会解析“输出部”,“输入部”,“破坏部”, “GotoLabels”,程序员也是同步这四个部分告诉编译器执行这段内嵌汇编可能发生的情况,如可能破坏寄存器,或者修改内存。或者输出部输入部需要的参数类型。
基于这些理解,我们可以再次审视gcc内嵌汇编那些奇怪的语法,很多内容就能理解了。
5.volatile的理解
使用volatile的目的是为了防止gcc将内嵌汇编整体优化掉的,gcc在编译阶段并不解析汇编指令,那么再什么情况下,gcc可能会认为内嵌汇编是没有意义的呢?
- 没有输出部,如果没有输出部,gcc可能会认为内嵌汇编是没有意义的,从而可能会优化掉。
- 连续两次同一个内嵌汇编代码块,如果输入部的参数一样,gcc可能会认为第二次调用没有执行的必要从而会被优化掉。

- 一个主动让gcc优化的例子

注:关于编译器的优化问题,还没有能力分析的面面俱到,本部分也只是一个大致的理解,
6. inline 的理解
- 前提:gcc将内嵌汇编当做字符串处理直接复制到汇编文件中由汇编器处理。
- 我们知道,针对汇编器会有一些伪指令不会被翻译为机器码或者一条汇编伪指令会被汇编为多条机器码,内嵌汇编具体有多大在编译阶段是没办法知道的(经过汇编器处理才能最终得出),但编译阶段有时有事需要知道内嵌汇编究竟有多大(在一些相对跳转指令中,在编译阶段需要通过代码量知道能不能跳转过去),这个时候gcc会根据代码的行数和体系架构估算可能的代码量,但gcc的估算是按照最大的可能去估算的,如果这段指令用的内嵌指令过多,可能会导致gcc估算的偏差太大。
- 使用inline修饰,gcc在估算代码时会将这段内嵌汇编当做最小大小来处理。
注:关于inline的应用场景,我目前还没遇见过,理解的可能也有偏差。
7. goto 的理解
goto比较容易理解,目的是告诉gcc内嵌汇编中有跳转指令,并指示可能的跳转位置,便于gcc对程序进行优化。
使用 goto 修饰应注意以下两点:
- goto 隐含 volatile 属性; 理解:存在跳转指令,此段汇编必定不会是没有意义的,故gcc不会进行优化
- 不能有输出部
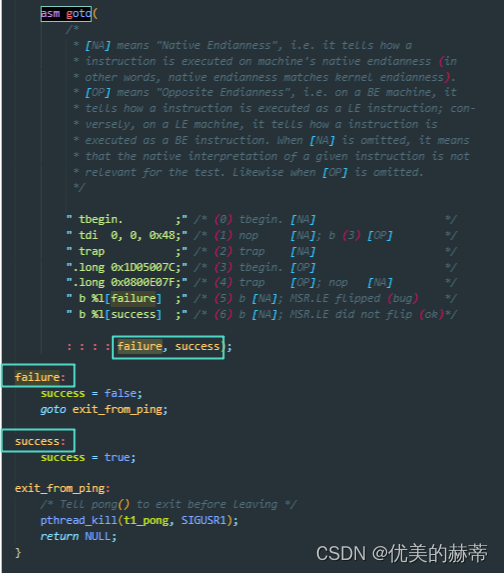
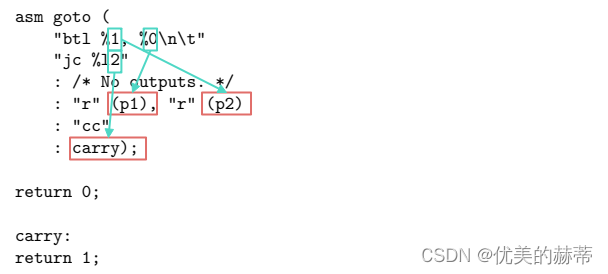
内嵌汇编中使用 GotoLabels 使用 %l(小写的L)进行索引,有两种索引方式: - 直接通过标签索引,直接看如下示例:
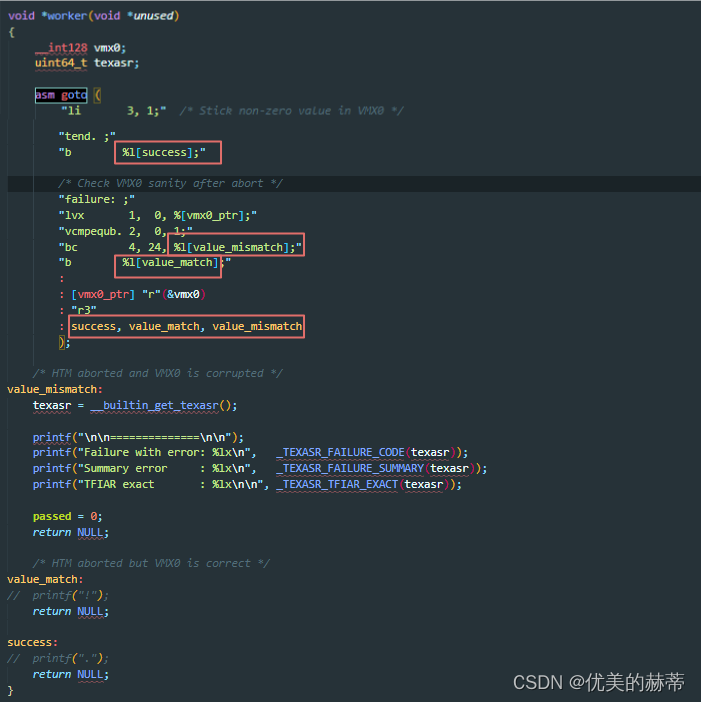
- 通过编号索引,方法是接着输出部和输入部的参数继续编号。如下示例:
8. 输出部 (OutputOperands)和 输入部(InputOperands)
8.1 输出部 (OutputOperands) 和输入部(InputOperands)的构成:
- c语言符号
- C语言中的变量,函数,表达式,常量等一切分配了存储空间的符号。
- 输出部 (OutputOperands) 的参数使用C语言中的 左值 ,具有可写的属性,使用 “=” 修饰,编译器则认为所修饰的符号是 只写 的,在汇编代码中是不会被读的,使用 “+” 修饰,则认为这个符号是可读可写的,“+r” 表示为所修饰的符号分配一个寄存器,且这个寄存器的值在汇编指令执行中是会被使用的。“=r” 表示为所修饰的符号分配一个寄存器,且这个寄存器的值在汇编指令执行中是不会被使用的,“+m” “=m”, 则是要求编译器为所修饰的符号分配内存进行存储。
- 输入部(InputOperands) 的参数使用C语言中的 右值, 编译器会认为输入部的参数在汇编代码执行前后是不会发生改变的(编译器会依据这一点进行程序优化),程序员应该在编程时保证这一点,
- 约束(Constraints)。
输出部 (OutputOperands) 的 “+r” ,“=r”,“+m”,“=m”, 输入部 (InputOperands) 的 “r”,“m”,目的是约束编译器为他所修饰的符号是一个什么类型的存储空间,“寄存器”?, “地址”?,“可读”?, “可写”? 。。。。。。
8.2 一个示例的分析
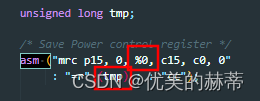
如下图示例:在下图红框中 “%0” 按汇编指令的要求需要一个普通寄存器,使用 “tmp” 作为输出部的参数,那么这个时候编译器会怎么作呢?
- 编译器并不会分析 “mrc p15, 0, %0, c15, c0,0” 这段汇编代码到底要干什么,
- 编译器会分析 :“=r” (tmp), 会知道 tmp 是需要一个寄存器存储的,且编译器会认为这个寄存器在汇编指令中是会被改变的,且汇编指令并不会使用这个寄存器的值。
- 假设编译器为 tmp分配了 R0, 编译器会将 %0 进行替换,然后将 “mrc p15, 0, r0, c15, c0,0” 作为一个字符串,原封不动的复制到汇编文件中。
8.3 输出部为什么需要 “=”,即为什么需要告诉编译器在内嵌汇编中不使用“=”所修饰符号的值。
简单来讲是gcc优化的需要,gcc只要保证一个符号在他使用前将其准备好就可以了,如果使用**“=”**修饰一个符号则是告诉编译器,内嵌汇编中不会用到这个值,所以gcc也不用在这段内嵌汇编前把这个值准备好,又因为gcc在编译阶段并不会分析内嵌汇编程序,所以即使在内嵌汇编中使用了这个值,编译器也不会报错,但这个值可能不是预期的。
8.4 为什么要有输出部 和 输入部,而不是程序员在内嵌汇编中自己分配
编译器会为定义的一些变量参数分配存储空间,如果在汇编程序中程序员在内嵌汇编中自己分配,则可能与编译器分配的产生冲突,当然如果程序员比较了解当前架构的ABI,明确知道编译器使用了哪些寄存器或者内存,在保证不冲突的情况下也可以自己分配。
8.5 其他的一些约束(Constraints)
这部分建议在用时在查手册,下面列出来一些,目的是大致有个印象,一些架构特定的约束可以约束到使用哪些寄存器。
| m | 内存变量 |
|---|---|
| o | 操作数为内存变量,但是其寻址方式是偏移量类型 |
| V | 操作数为内存变量,但寻址方式不是偏移量类型 |
| r | 通用寄存器 |
| i | 立即数 |
| p | 指针 |

9. 破坏部 (Clobbers)
- “cc”
告诉编译器汇编代码会修改标志寄存器,如 N Z C V
- “memory”
告诉编译器汇编代码会破坏内存,破坏部使用了“memory”,相当于一道内存屏障,可以用来防止编译时乱序。
考虑如下代码,他不会执行任何一条汇编指令,他其实也不会破坏内存,但编译器并不知道,编译器在看到"memory"后就认为他是可能破坏内存的,一般用来作为内存屏障,防止编译乱序。asm volatile ("":::"memory");
10 为C语言中的符号在编译为汇编后重新指定一个名字
此部分语法很简单,但目前我还没理解这种用法的应用场景。
在此不展开了,有兴趣可以看手册6.47.4章。
int foo asm ("myfoo") = 2;
int func (int x, int y) asm ("MYFUNC");
int func (int x, int y)
{
/* . . . */
}
11 指定变量与固定寄存器绑定的语法。
语法很简单,有兴趣可以看手册6.47.5章
12 示例 - arm32 系统调用内嵌汇编的实现
如下是linux内核中的示例,在此不展开分析系统调用,在理解了前面的知识后,应该能看懂下面代码。
arm的软中断指令:swi svc
arm系统调用的参数传递:R0-R6
arm系统调用号的传递:R7
返回值:R0
















 2374
2374











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









