







摘要
为了解决上述问题,本文提出了一种新的生成对抗渲染器(GAR),并针对一般拟合流水线对GAR的反向版本进行了修改。 具体来说,精心设计的神经渲染器以人脸法线图和表示其他因素的潜在代码为输入,渲染出逼真的人脸图像。 由于GAR学习对复杂的真实图像建模,不依赖于简化的图形规则,能够生成真实感的图像,从根本上抑制了训练和优化中的域移噪声。 在改进的GAR基础上,我们进一步提出了一种新的三维人脸参数预测方法,该方法首先通过渲染器反演获得精细的初始参数,然后使用基于梯度的优化器对初始参数进行优化。 大量的实验证明了所提出的生成对抗渲染器和新的基于优化的人脸重建框架的有效性。 我们的方法在多个人脸重建数据集上达到了最先进的性能。
相关研究介绍
目前的主流人脸三维重建技术大致分为两类方式,基于学习的方式与基于优化的方式。基于学习的方式,是借助CNN来回归控制人脸三维结构的3DMM系数,但是缺点便是依赖三维标注数据集,而3DMM的真实值其实是很难获取到的,这种三维数据集非常稀缺;基于优化的方式,是将所输入的二维人脸图像看做是一个生成的过程,由一系列的参数控制,如albedo(反照率,可以理解为人脸表面的不加光照的基础颜色)、纹理、光照、观察角度等,按照特定的渲染图像的法则最终计算出来二维人脸图像,而这样我们就可以通过比较渲染图像与输入图像的差异进行优化了,但是缺点是所使用的渲染图像法则决定了重建效果的上限,这种法则其实是简化了很多复杂过程的。
最近的可微分渲染应用优化了以上两种方法,比如我使用3DMM系数渲染后的图像,可以通过比较与输入图像的差异进行优化(相当于结合了两种方法的好处,不再依赖数据集,有篇参考文章《Accurate 3d face reconstruction with weakly-supervised learning: From single image to image set》CVPR Workshop 2019),当然可微分渲染也有两个缺点,一是渲染的过程是人为指定的,像基于优化的方法一样,渲染出的图像不是很真实,二是可微分渲染器很难优化,它只能将误差反向传播给局部顶点(个人理解为很难调控全局的信息,比如这个人的身份特征)。

如上图所示,文章将自己的方法渲染出的图像与最近的一些方法进行了比较,可以看到3DDFA使用的渲染(得到最终的3DMM系数后进行普通渲染)和GANFIT使用的渲染(通过可微渲染一步步优化3DMM系数)生成的图像都不是那么真实。这种所谓不真实的渲染方法文中称作graphics-based,就是图形学中通用的栅格化渲染,其实我们玩过很多的3A大作游戏,虽然图像很逼真,但是总是感觉和现实有那么一点差距,作者这里就认为是图形学里的渲染管线结构本身导致了这种不真实,如果替换成神经网络可能结果会更加逼真一点(可惜在图形学里是不可能用神经网络进行渲染的)。虽然有些文章对渲染过程做了优化,还是很难解决这种问题,如《Neural 3d mesh renderer》CVPR 2018、《Soft rasterizer: Differentiable rendering for unsupervised singleview mesh reconstruction》。那么既然普通渲染、可微渲染太假,那么我将其升级为神经网络渲染会如何呢,也不太行,如上图d的DFG方法《Disentangled and controllable face image generation via 3d imitative-contrastive learning》CVPR 2020所示,输入是3dmm系数,但是神经网络渲染器要理解3DMM系数这种抽象的东西实在太难了,以至于生成的人脸和我们想要的人脸根本不是一个人。
方法
工作的目标是从单幅图像中重建其相应的人脸几何参数。 给定一幅图像,1)通过GAR逆网络初始化潜在码和噪声;2)3DMM参数用拟合方法初始化。 通过从1)和2)初始化参数,然后通过反向传播来优化所有参数和潜在代码。
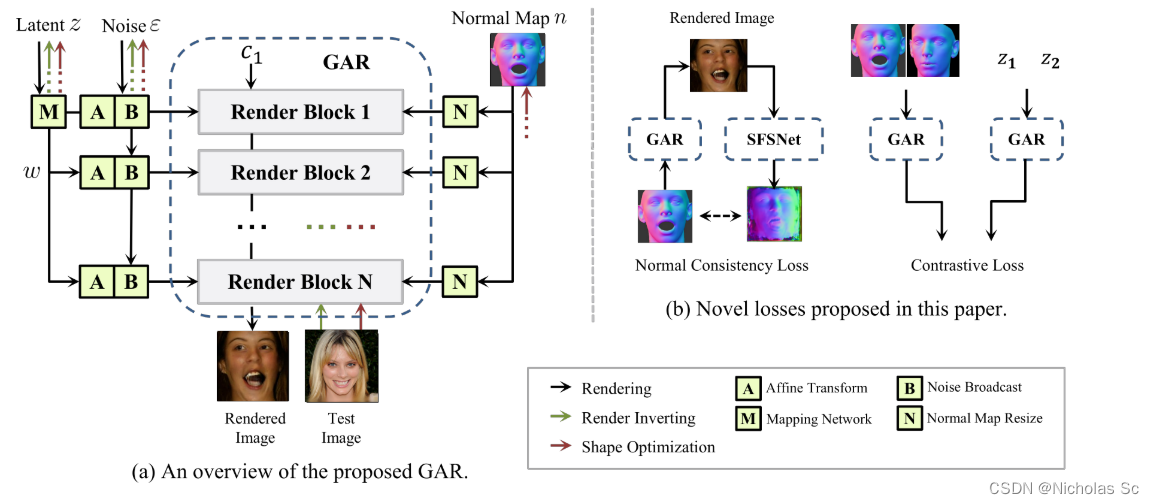
图中左边部分就是生成对抗渲染器(GAR)的结构图,整个渲染器的结构基于style GAN v2进行改进得到,在渲染的时候(黑线部分),接收z、noise、normal map三个输入,其中这三个输入在每一个渲染块都会产生作用(如果仅仅在输入渲染块产生作用的话,那么经过一层一层之后对最终结果就影响甚微了,这也是style GAN设计的核心思想),网络中的C1是一个固定的输入,相当于初始的特征图(4 ∗ 4 4*44∗4分辨率,512通道),每经过一层渲染块,分辨率会加倍,8 ∗ 8 8*88∗8到16 ∗ 16 16*1616∗16一直到1024 ∗ 1024 1024*10241024∗1024。而每一层渲染块的具体结构如下图所示:
之前的z经过8层MLP转换到了参数w,可以认为将z所蕴含的特征进行了展开(因为z的特征比较紧凑,关联也高,不解耦合的话模型很难学习到有用的东西),而w如何控制每一个渲染块呢,如下面公式所示:

每一个渲染块都有一个卷积核,w通过对卷积核进行仿射变换(按理说仿射变换是对数据进行缩放和平移操作的,style GAN就是这样,但是style GAN v2将平移给去掉了,只剩下缩放),其实就相当于变相地对特征图(每一层渲染块的输出,最开始是C1)进行仿射变换了,而这种仿射变换,在style GAN v2里面正是影响图像风格的关键因素。上面的公式,c代表卷积核的通道,i和j代表卷积核像素的坐标,整个分子是图中的Mod模块(调制,modulation),分母是图中的Dem模块(解调制,demodulation),其实可以理解为根据方差进行数据的归一化(毕竟训练神经网络一般也要进行batchnorm的嘛)其中的ϵ 是为了防止除以0。
之后就是进行简单的卷积了,如下面公式所示:
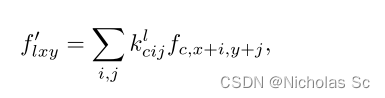
之后该如何将法线贴图作用到我们的网络中呢,作者提出的NIM(法线注入)模块做的是下面的操作:
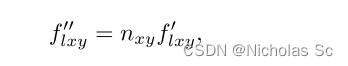
上面的f ff是个三维的向量,代表法线贴图(x,y)处的值,法线贴图的RGB通道就相当于该点法线的x,y,z值了,也是个三维向量,对应相乘,就完成所谓的法线注入了。
重建的过程中,肯能需要对参数进行初始化的,那么是随机初始化吗?这样的话,作者根据《 Seeing what a gan cannot generate》 ICCV 2019 这篇深入分析GAN本质的文章,认为这样会陷入一种局部极小值,所以设计了一种反转的方式,去较好地初始化输入参数。参数的初始化分为两部分,一部分是初始化z,通过设计了与渲染器对称的一种反转网络结构,用统计平均值和方差来估计z。















 2127
2127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









