





我于2017年5月开始在Confluent工作,担任技术传播者,专注于围绕开源框架Apache Kafka的主题。 我认为机器学习是当今最热门的流行语之一,因为它可以在任何行业中增加巨大的商业价值。 因此,您还会看到我的其他各种帖子,包括Apache Kafka(消息传递),Kafka Connect(集成),Kafka Streams(流处理),Confluent在Kafka之上的其他开源插件(Schema Registry,Replicator,Auto Balancer,等等。)。 我将解释在实际生产场景中如何将所有这些用于机器学习和其他大数据技术。
如果您想知道为什么对在大数据世界中迁移(返回)开源以便进行消息传递,集成和流处理感到非常兴奋,请阅读本文档。
在下面的博客文章中,我想分享一次代表Confluent的会议演讲的第一张幻灯片:位于德国莱比锡的软件体系结构用户组组织了为期2天的活动,以讨论实践中的大数据 。
Apache Kafka流+机器学习/深度学习
这是幻灯片的摘要:
大数据和机器学习是当今许多行业创新的关键。 大量的历史数据存储在Hadoop,Spark或其他群集中并进行分析,以找到模式和见解,例如用于预测性维护,欺诈检测或交叉销售。
本部分的第一部分将说明如何利用开源机器学习/深度学习框架(如Apache Spark , TensorFlow或H2O.ai) , 使用R,Python和Scala构建分析模型 。
第二部分讨论如何在自己的实时流应用程序或微服务中利用这些内置的分析模型。 它说明了如何利用Apache Kafka集群和Kafka Streams而不是构建自己的流处理集群。 该课程侧重于现场演示,并讲授以高度可扩展和高效的方式执行分析模型的经验教训。
最后一部分解释了Apache Kafka如何帮助从手动构建和部署分析模型转变为实时不断地在线改进模型 。
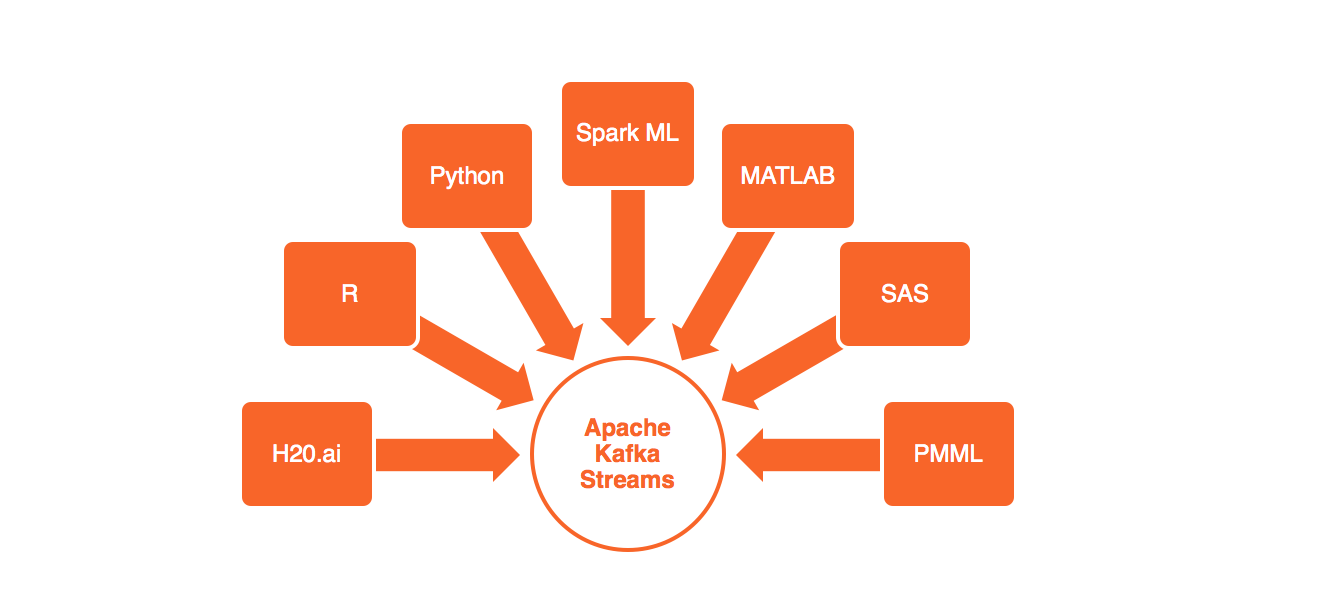
幻灯片:如何建立分析模型并将其部署到实时处理
这是幻灯片平台:
来自KaiWähner的 Apache Kafka流+机器学习/深度学习
接下来的几周将发布更多具有更多详细信息的博客文章和特定的代码示例。 我还将对此幻灯片平台进行网络记录,并将其发布到Youtube上。















 363
363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









