





 在上一篇文章中,我描述了执行PageRank计算的示例,该示例是使用Apache Hadoop进行Mining Massive Dataset课程的一部分。 在那篇文章中,我接受了Java中现有的Hadoop作业,并做了一些修改(添加了单元测试,并通过参数设置了文件路径)。 这篇文章展示了如何在现实的Hadoop集群上使用此作业。 该集群是一个由1个主节点和5个核心节点组成的AWS EMR集群 ,每个集群均由m3.xlarge实例支持。
在上一篇文章中,我描述了执行PageRank计算的示例,该示例是使用Apache Hadoop进行Mining Massive Dataset课程的一部分。 在那篇文章中,我接受了Java中现有的Hadoop作业,并做了一些修改(添加了单元测试,并通过参数设置了文件路径)。 这篇文章展示了如何在现实的Hadoop集群上使用此作业。 该集群是一个由1个主节点和5个核心节点组成的AWS EMR集群 ,每个集群均由m3.xlarge实例支持。
第一步是为集群准备输入。 我使用AWS S3是因为这是使用EMR时的便捷方式。 我创建了一个新存储桶'emr-pagerank-demo',并制作了以下子文件夹:
- in:包含作业输入文件的文件夹
- job:包含我的可执行Hadoop jar文件的文件夹
- 日志:EMR将放置其日志文件的文件夹
然后,在“ in”文件夹中,我复制了要排名的数据。 我用这个文件作为输入。 解压缩后,它变成了一个具有XML内容的5 GB文件,尽管不是很大,但对于此演示来说已经足够。 当您使用前一篇文章的源代码并运行“ mvn clean install”时,您将获得jar文件:“ hadoop-wiki-pageranking-0.2-SNAPSHOT.jar”。 我将此jar文件上传到“作业”文件夹。
就是为了准备。 现在我们可以启动集群了。 在此演示中,我使用了AWS管理控制台 :
- 命名集群
- 输入日志文件夹作为日志位置
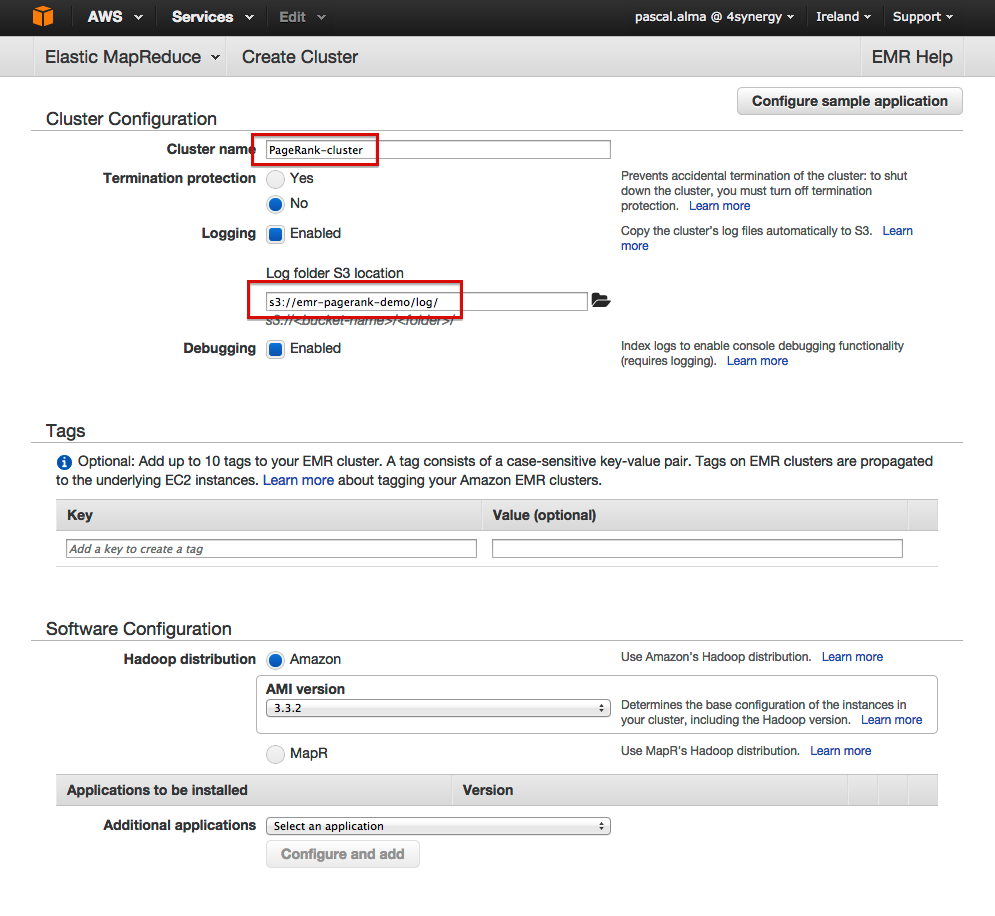
- 输入核心实例数
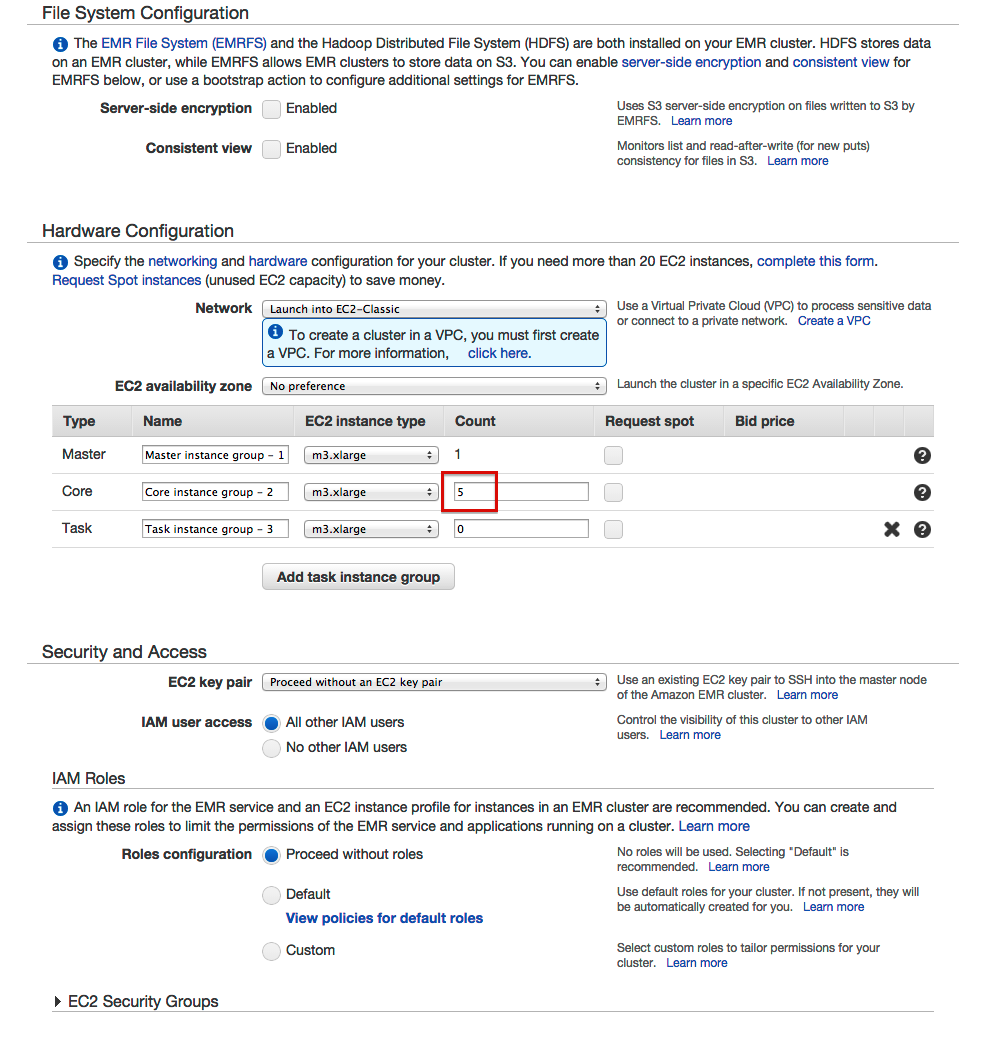
- 为我们的自定义罐添加一个步骤
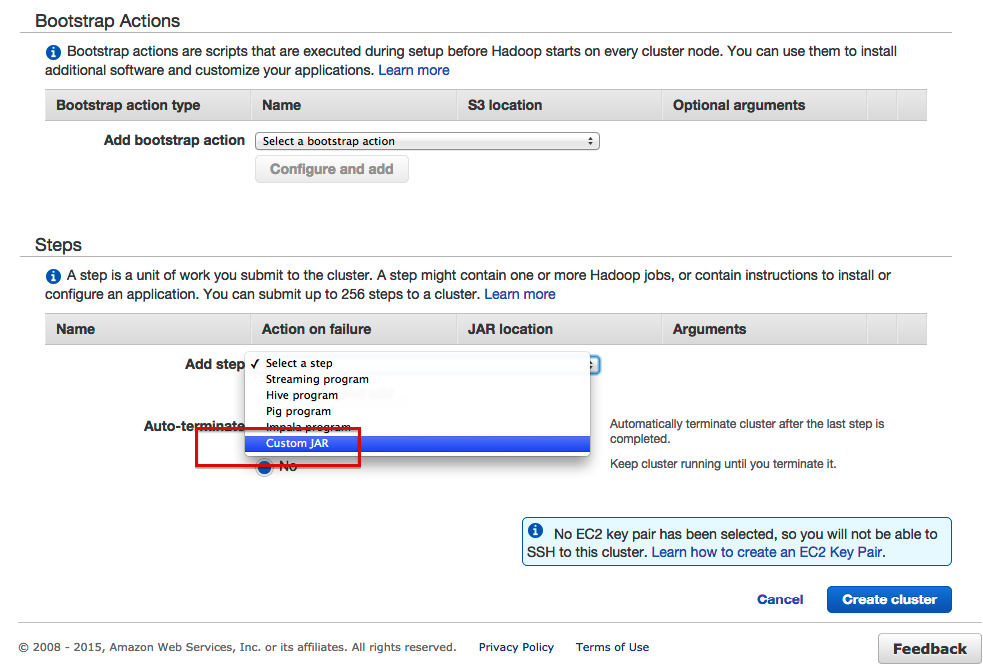
- 像这样配置步骤:
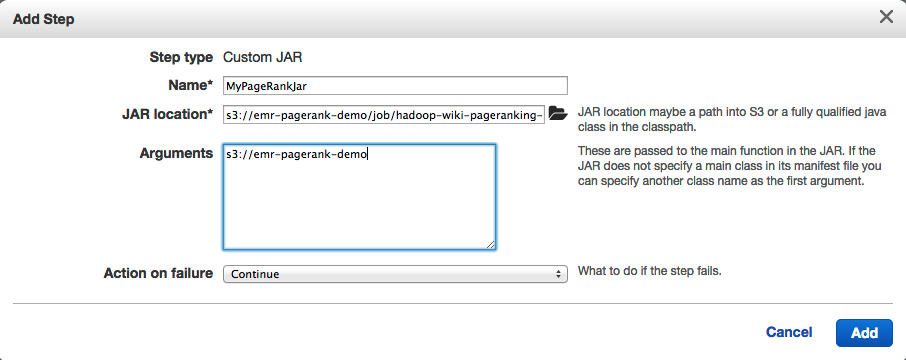
- 这将导致以下概述:
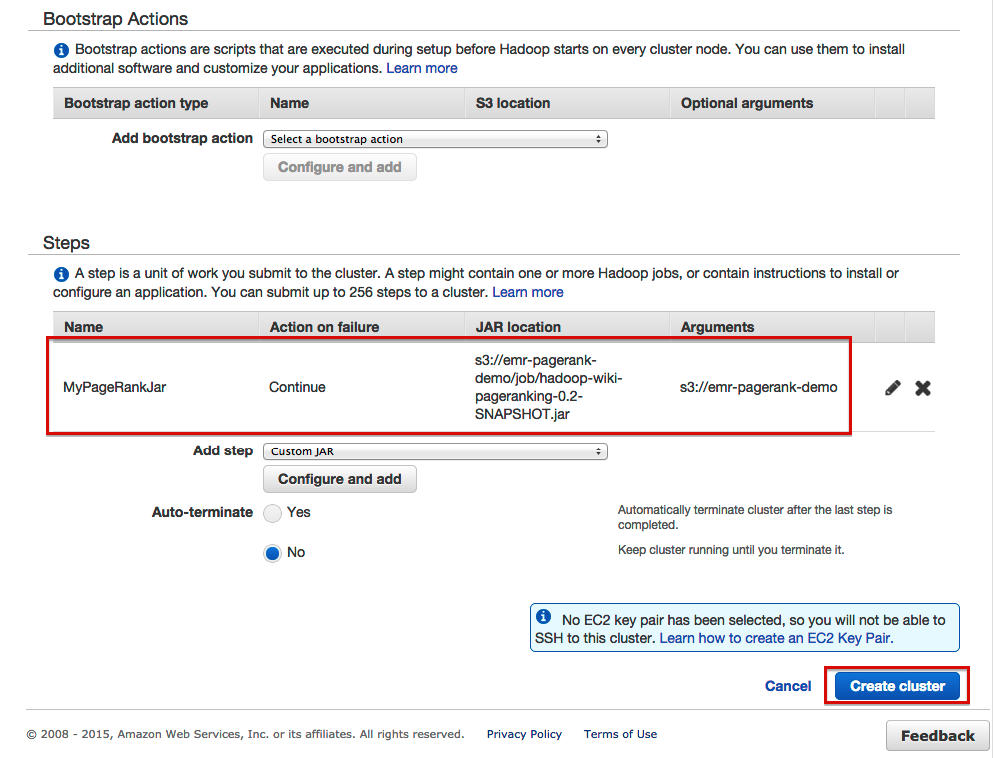
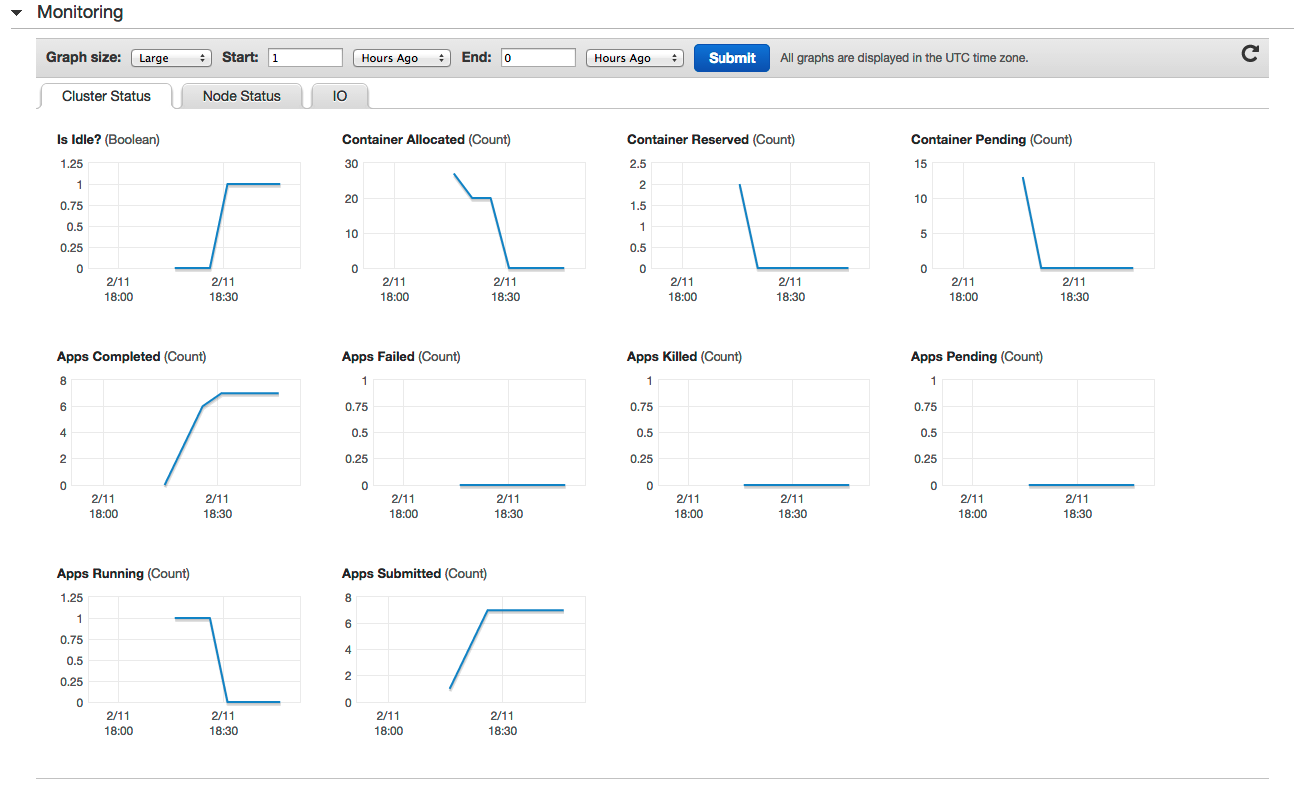
如果正确,则可以按“创建集群”按钮,并使EMR进行工作。 您可以在控制台的“监视”部分监视集群:
并在“步骤”部分中监视步骤的状态:
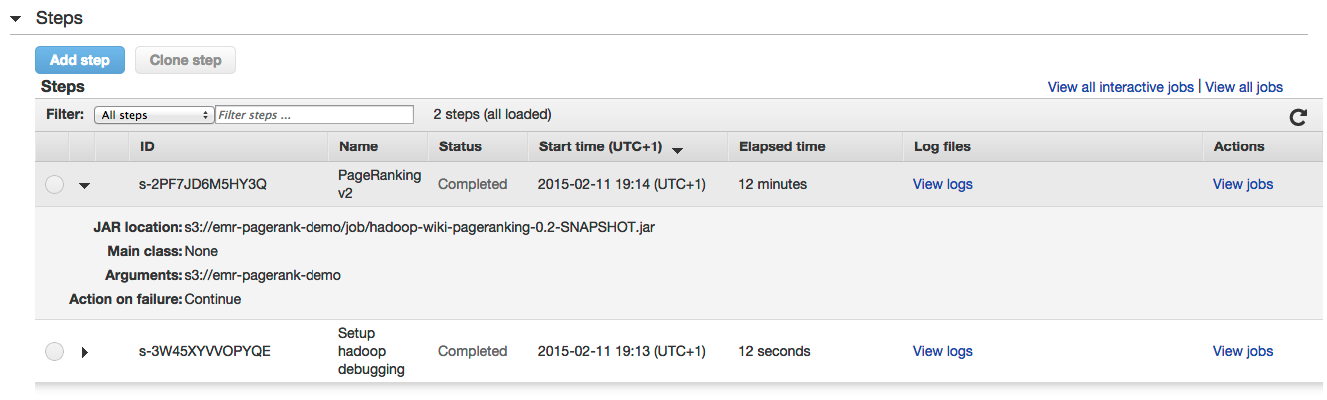
几分钟后,作业将完成(当然取决于输入文件的大小和使用的群集)。 在我们的S3存储桶中,我们可以看到在'log'文件夹中创建了日志文件:
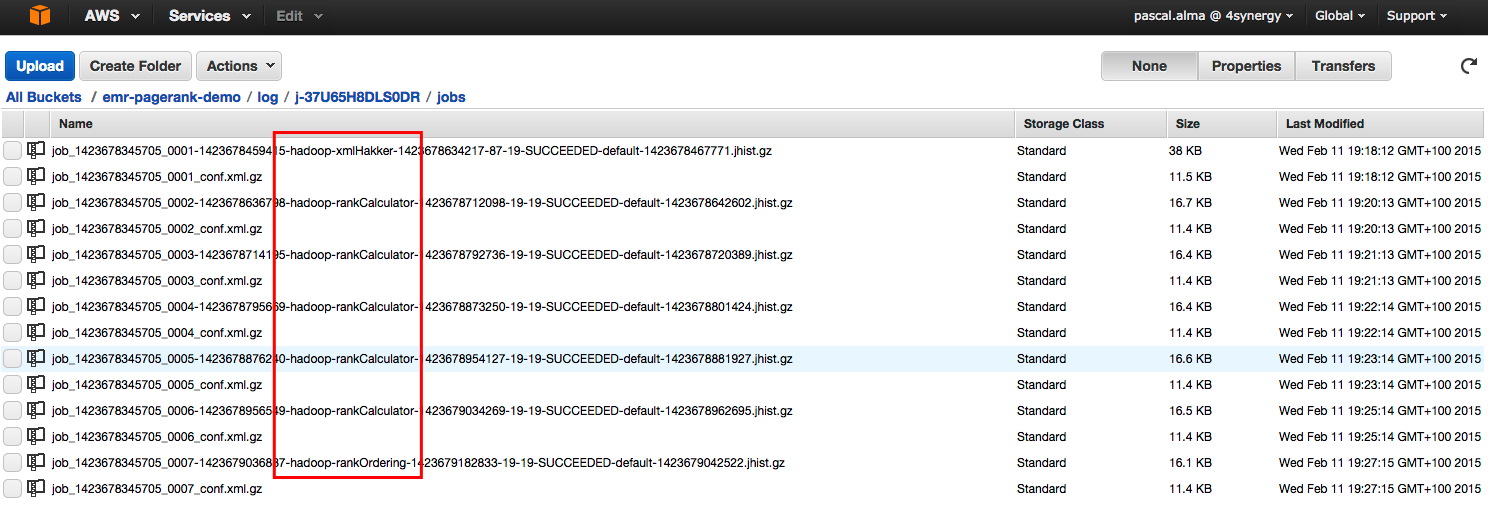
在这里,我们总共看到7个作业:1 x Xml准备步骤,5 x rankCalculator步骤和1 x rankOrdering步骤。
更重要的是,我们可以在“结果”文件夹中查看结果:
每个reducer都会创建自己的结果文件,因此我们在这里有多个文件。 我们对排名最高的网页感兴趣,因为其中的网页排名最高。 如果我们查看此文件,将看到以下结果排在前10位:
271.6686 Spaans
274.22974 Romeinse_Rijk
276.7207 1973
285.39502 Rondwormen
291.83002 Decapoda
319.89224 Brussel_(stad)
390.02606 2012
392.08563 Springspinnen
652.5087 2007
2241.2773 Boktorren请注意,当前的实现只运行5次计算(硬编码),因此实际上并没有如MMDS理论中所描述的那样进行幂次迭代(对软件的下一版进行了很好的修改:-)。
另请注意,使用默认设置时,作业完成后群集不会终止,因此在手动终止群集之前,群集的成本会增加。
翻译自: https://www.javacodegeeks.com/2015/03/running-pagerank-hadoop-job-on-aws-elastic-mapreduce.html















 2607
2607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









