





在使用Java编程语言时,我们将继续讨论与建议的实践有关的系列文章,我们将在四个具有相关语义的流行Queue实现类之间进行性能比较。 为了使事情变得更现实,我们将在多线程环境下进行测试,以讨论和演示如何将ArrayBlockingQueue , ConcurrentLinkedQueue , LinkedBlockingQueue和/或LinkedList用于高性能应用程序。
最后但并非最不重要的一点是,我们将提供自己的ConcurrentHashMap实现。 从ConcurrentLinkedHashMap实施不同的ConcurrentHashMap ,它维持于所有条目的运行双向链表。 此链表定义了迭代顺序,通常是将键插入映射中的顺序。 从组合的特点ConcurrentLinkedHashMap利益的ConcurrentHashMap和LinkedHashMap的实现业绩略低于该的ConcurrentHashMap的 ,由于增加了维护链接列表的额外费用。
所有讨论的主题均基于用例,这些用例来自于电信行业的关键任务超高性能生产系统的开发。
在阅读本文的每个部分之前,强烈建议您参考相关的Java API文档以获取详细信息和代码示例。
所有测试均针对具有以下特征的Sony Vaio进行:
- 系统:openSUSE 11.1(x86_64)
- 处理器(CPU):Intel(R)Core(TM)2 Duo CPU T6670 @ 2.20GHz
- 处理器速度:1,200.00 MHz
- 总内存(RAM):2.8 GB
- Java:OpenJDK 1.6.0_0 64位
应用以下测试配置:
- 并发工作线程数:50
- 每个工作人员测试重复次数:100
- 整体测试次数:100
ArrayBlockingQueue与ConcurrentLinkedQueue与LinkedBlockingQueue与LinkedList
Java开发人员必须执行的最常见任务之一是从Collections中存储和检索对象。 Java编程语言提供了一些具有重叠和独特特征的Collection实现类。 从Java 1.5开始, Queue实现类已成为在处理之前保存元素的事实上的标准。 除了基本的“ 收集”操作外,队列还提供其他插入,提取和检查操作。
但是,使用Queue实现类,尤其是在多线程环境中,可能会很棘手。 默认情况下,它们中的大多数提供并发访问,但是可以以阻塞或非阻塞方式来处理并发。 BlockingQueue实现类支持以下操作:在检索元素时等待队列变为非空,并在存储元素时等待队列中的空间变为可用。
这里将要讨论的案例场景是通过ConcurrentLinkedQueue和LinkedList Queue实现类以及ArrayBlockingQueue和LinkedBlockingQueue BlockingQueue实现类的元素来插入,缩回和迭代多个线程 。 我们将演示如何在多线程环境中正确利用上述集合实现类,并提供相关的性能比较表,以显示在每个测试用例中哪个性能更好。
为了进行票价比较,我们将假定不允许使用NULL元素,并且在适用的情况下限制每个队列的大小。 因此,我们的测试组的BlockingQueue实现类将被初始化,其最大大小为5000个元素–请记住,我们将使用50个工作线程来执行100次测试重复。 此外,由于LinkedList是我们测试组中唯一不默认提供并发访问的Queue实现类,因此将使用同步块访问列表来实现LinkedList的并发性。 在这一点上,我们必须明确指出LinkedList Collection实现类的Java文档建议使用Collections.synchronizedList静态方法来维护对列表的并发访问。 此方法提供指定Collection实现类的“包装”同步实例,如下所示:
列表syncList = Collections.synchronizedList(new LinkedList());
当您要将特定的实现类用作List而不是Queue时,此方法是合适的。 为了能够使用特定Collection实现类的“队列”功能,必须按原样使用它,或将其强制转换为Queue接口。
测试案例1 –在队列中添加元素
对于第一个测试用例,我们将有多个线程在每个Queue实现类中添加String元素。 为了保持String元素之间的唯一性,我们将如下所示构造它们:
- 静态的第一部分,例如“ helloWorld”
- 工作线程ID,请记住,我们有50个并发运行的工作线程
- worker线程测试重复次数,请记住,每个worker线程每次测试执行100次测试重复
对于每个测试运行,每个工作线程将插入100个String元素,如下所示:
- 对于第一次测试重复
- 工作线程1将插入String元素:“ helloWorld-1-1”
- 工作线程2将插入String元素:“ helloWorld-2-1”
- 工作线程3将插入String元素:“ helloWorld-3-1”
- 等等...
- 对于第二次测试重复
- 工作线程1将插入String元素:“ helloWorld-1-2”
- 工作线程2将插入String元素:“ helloWorld-2-2”
- 工作线程3将插入String元素:“ helloWorld-3-2”
- 等等...
- 等等...
在每次测试运行结束时,每个Queue实现类都将填充5000个不同的String元素。 为了添加元素,我们将使用BlockingQueue实现类的“ put()”操作和Queue实现类的“ offer()”操作,如下所示:
- arrayBlockingQueue.put(“ helloWorld-” + id +“-” + count);
- linkedBlockingQueue.put(“ helloWorld-” + id +“-” + count);
- parallelLinkedQueue.offer(“ helloWorld-” + id +“-” + count);
- 已同步(linkedList){
linkedList.offer(“ helloWorld-” + id +“-” + count);
}
下面我们提供了上述四个Queue实现类之间的性能比较表
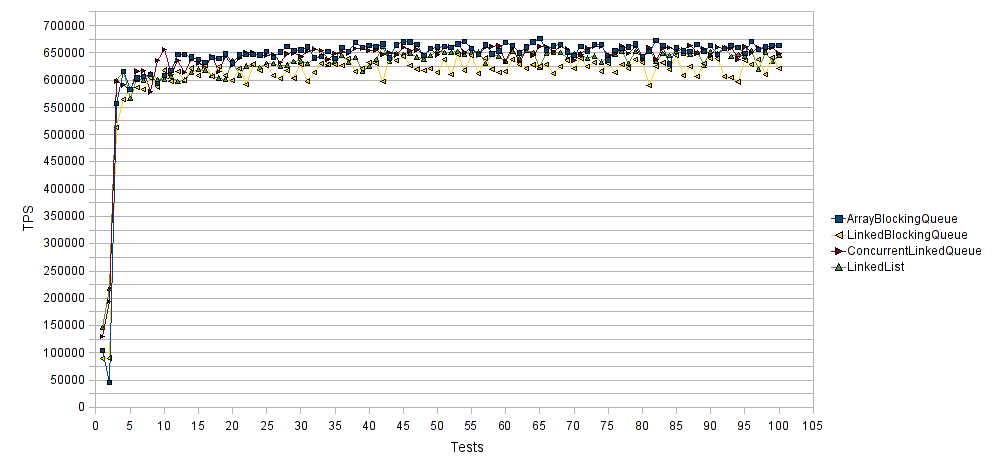
横轴表示测试运行的次数,纵轴表示每次测试运行的每秒平均事务数(TPS)。 因此,较高的值更好。 如您所见,向其添加元素时,所有Queue实现类的执行几乎相同。 与LinkedList和LinkedBlockingQueue相比, ArrayBlockingQueue和ConcurrentLinkedQueue的性能稍好。 后者表现最差,平均得分为625000 TPS。
测试案例2 –从队列中删除元素
对于第二个测试用例,我们将有多个线程从每个Queue实现类中删除String元素。 所有队列实现类都将使用来自先前测试用例的String元素进行预填充。 每个线程将从每个Queue实现类中删除单个元素,直到Queue为空。
为了删除元素,我们将对BlockingQueue实现类使用“ take()”操作,对Queue实现类使用“ poll()”操作,如下所示:
- arrayBlockingQueue.take();
- linkedBlockingQueue.take();
- concurrentLinkedQueue.poll();
- 已同步(linkedList){
linkedList.poll();
}
下面我们提供了上述四个Queue实现类之间的性能比较表
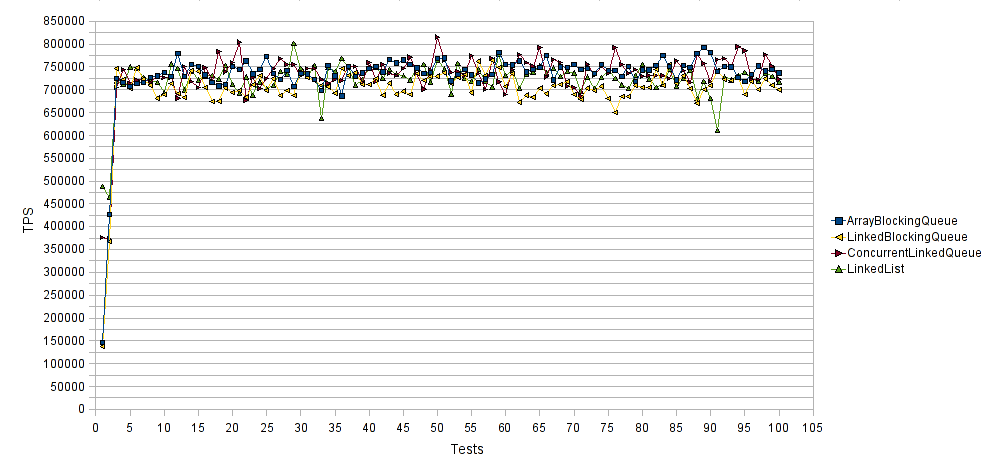
横轴表示测试运行的次数,纵轴表示每次测试运行的每秒平均事务数(TPS)。 因此,较高的值更好。 同样,从队列中删除String元素时,所有Queue实现类的性能几乎相同。 与LinkedList和LinkedBlockingQueue相比, ArrayBlockingQueue和ConcurrentLinkedQueue的性能稍好。 后者是最差的性能,平均得分为710000 TPS。
测试案例#3 –迭代器
对于第三个测试用例,我们将有多个工作线程在每个Queue实现类的元素上进行迭代。 每个工作线程将使用Queue的“ iterator()”操作检索对Iterator实例的引用,并使用Iterator的“ next()”操作遍历所有可用的Queue元素。 所有Queue实现类都将使用第一个测试用例的String值预先填充。 下面是上述测试用例的性能比较表。
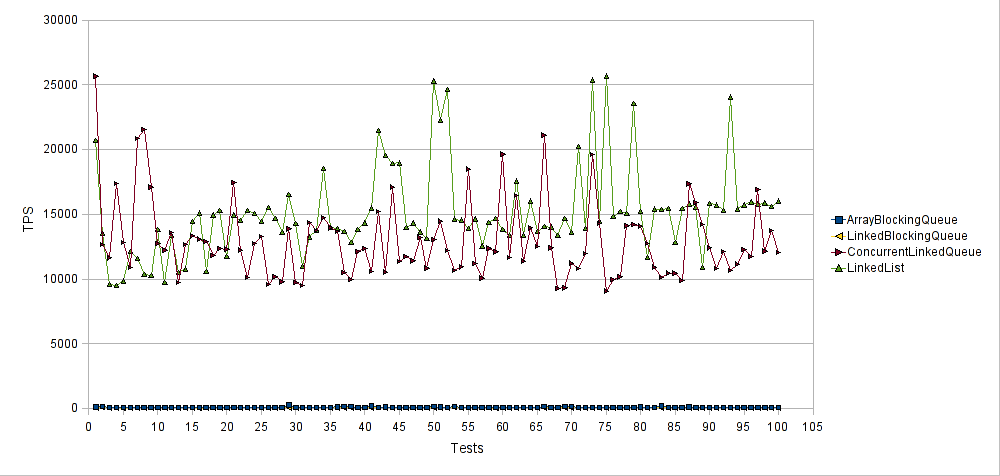
横轴表示测试运行的次数,纵轴表示每次测试运行的每秒平均事务数(TPS)。 因此,较高的值更好。 与ConcurrentLinkedQueue和LinkedList实现类相比, ArrayBlockingQueue和LinkedBlockingQueue实现类的性能均较差。 LinkedBlockingQueue平均得分为35 TPS,而ArrayBlockingQueue平均得分为81 TPS。 另一方面, LinkedList的性能优于ConcurrentLinkedQueue ,平均导致15000 TPS。
测试案例4 –添加和删除元素
对于我们的最终测试用例,我们将实现测试用例1和测试用例2场景的组合。 换句话说,我们将实现生产者-消费者测试用例。 一组辅助线程将向每个Queue实现类插入String元素,而另一组辅助线程将从其中撤回String元素。 每一个主题从“插入元素”组将会只有一个元素插入,而每一次的主题从“缩回元素”组是要收回一个元素。 因此,我们将从每个Queue实现类中同时插入和撤回5000个唯一的String元素。
要正确模拟上述测试情况下,我们必须启动所有工作线程是收回之前的元素开始工作者线程是插入的元素。 为了使“收回元素”组的工作线程能够收回单个元素,如果相关队列为空,它们必须等待并重试。 默认情况下, BlockingQueue实现类提供等待功能,而Queue实现类则不提供。 因此,为了删除元素,我们将对BlockingQueue实现类使用“ take()”操作,对Queue实现类使用“ poll()”操作,如下所示:
- arrayBlockingQueue.take();
- linkedBlockingQueue.take();
- while(结果== null)
结果= parallelLinkedQueue.poll(); - while(结果== null)
已同步(linkedList){
结果= linkedList.poll(); }
如您所见,我们实现了最低限度的while循环,以使ConcurrentLinkedQueue和LinkedList使用者能够在从空Queue撤回时执行重新连接。 当然,您可以尝试并实施更复杂的方法。 尽管如此,请记住,上述内容以及任何其他人工实现方法都不是建议的解决方案,应避免使用BlockingQueue “ take()”操作,如以下性能比较表所示。
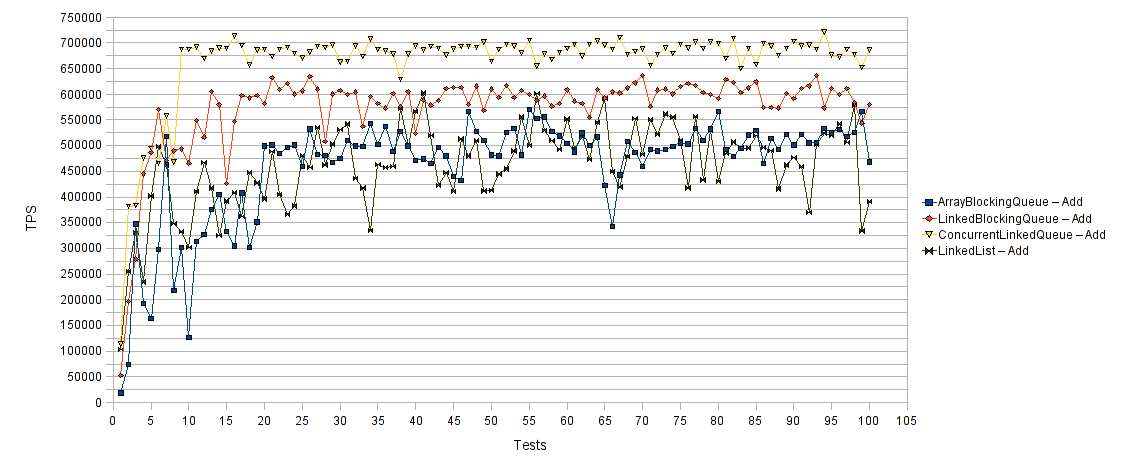
下面是上述测试用例的添加部分的性能比较表。
以下是上述测试案例的收回部分的性能比较表。

横轴表示测试运行的次数,纵轴表示每次测试运行的每秒平均事务数(TPS)。 因此,较高的值更好。 不出所料, ArrayBlockingQueue和LinkedBlockingQueue的表现均优于LinkedList和ConcurrentLinkedQueue 。 BlockingQueue实现被设计为主要用于生产者-消费者队列。 在这种情况下,特别是当生产者线程和使用者线程的数量相对较高时,它们的阻塞行为使它们具有无与伦比的性能和效率。 实际上,根据相关的性能比较,随着生产者线程和使用者线程数量的增加, Queue实现类和BlockingQueue实现类之间的性能相对增益会有所提高,而后者则有所提高。
从提供的性能结果中可以看出, LinkedBlockingQueue获得了最佳的组合(添加和删除元素)性能结果,并且应该是实施生产者(消费者)方案的第一候选人。
ConcurrentLinkedHashMap
我们的ConcurrentLinkedHashMap实现是最初由Doug Lea编码并在OpenJDK 1.6.0_0上发现的ConcurrentHashMap实现的调整版本。 我们提出了ConcurrentMap接口的并发哈希图和链表实现,并具有可预测的迭代顺序。 此实现与ConcurrentHashMap的不同之处在于,它维护一个遍历其所有条目的双向链接列表。 此链表定义了迭代顺序,通常是将键插入映射的顺序(插入顺序)。 请注意,如果将密钥重新插入到映射中,则插入顺序不会受到影响。
此实现使客户摆脱了ConcurrentHashMap和Hashtable提供的未指定的,通常混乱的排序,而不会增加与TreeMap相关的成本。 无论原始地图的实现如何,都可以使用它来生成与原始地图具有相同顺序的地图副本:
void foo(Map m){
地图副本=新的ConcurrentLinkedHashMap(m);
… }
如果模块在输入上获取映射,将其复制并随后返回结果(其顺序由副本的顺序确定),则此技术特别有用。 (客户通常喜欢按退货的顺序退货。)
提供了一个特殊的“ ConcurrentLinkedHashMap(int,float,int,boolean)”构造函数,以创建并发链接的哈希映射,该哈希映射的迭代顺序是其条目的最后访问顺序,即从最近访问到最近访问(访问-订购)。 这种映射非常适合构建LRU缓存。 调用put或get方法将导致对相应条目的访问(假设调用完成后该条目存在)。 “ putAll()”方法为指定映射中的每个映射生成一个条目访问,其顺序为指定映射的条目集迭代器提供键-值映射。 没有其他方法可以生成条目访问。 特别是,对集合视图的操作不会影响支持映射的迭代顺序。
可以重写“ removeEldestEntry(Map.Entry)”方法,以强加一个策略,以便在将新映射添加到地图时自动删除陈旧的映射。
由于维护链接列表会增加开销,因此性能可能会略低于ComcurrentHashMap,但有一个例外:对ConcurrentLinkedHashMap的集合视图进行迭代需要的时间与地图的大小成正比,而无论其容量如何。 在ConcurrentHashMap上进行迭代可能会更昂贵,所需的时间与其容量成正比。
您可以从此处下载最新版本的ConcurrentLinkedHashMap源代码和二进制代码
您可以从此处 , 此处和此处下载用于进行性能比较的所有“测试器”类的源代码。
快乐编码
贾斯汀
相关文章 :
- Java最佳实践–多线程环境中的DateFormat
- Java最佳实践–高性能序列化
- Java最佳实践– Vector vs ArrayList vs HashSet
- Java最佳实践–字符串性能和精确字符串匹配
- Java最佳实践– Char到Byte和Byte到Char的转换
翻译自: https://www.javacodegeeks.com/2010/09/java-best-practices-queue-battle-and.html















 3378
3378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









