





jvm高并发
在第一篇关于HTTP客户端的文章 (我将您重定向到JVM上的高效HTTP的介绍)之后,现在让我们来谈谈HTTP 服务器 。
有一些关于HTTP服务器的基准测试,但通常受到诸如以下缺点的阻碍:
- 没有有效地执行高并发方案,并且更普遍地考虑了不现实和不具有代表性的方案,例如:
- 纯开销方案,其中请求处理基本上为零(在实践中,总有一些处理需要完成)。
- 实际不连接,隔离和/或确定负载生成和负载目标过程的尺寸。
- 没有分配可比的系统资源来加载目标。
- 不包括足够广泛的方法(例如,仅专注于“同步”或“异步”服务器)。
- 不分析数据以产生结果 。
我们将分析新的基准,这些基准试图解决上述问题,并且产生了非常有趣的,有时甚至是意外的结果:
- 如果请求的寿命不是很长,同步的线程阻塞Jetty和Undertow服务器也可以有效地用于高并发情况。
- 当请求需要保持很长时间(例如,长轮询,服务器推送)时,异步服务器和使用Quasar光纤的服务器可以支持更多并发活动请求。
- 异步API相当复杂,而光纤则很简单(与传统的线程阻塞一样多),并且不仅在高并发情况下而且在各种情况下都表现出色。
基准和负载生成器
高并发方案已成为重要的使用和基准案例。 它们可能是由于特定功能(例如聊天)和/或有时是不需要的技术状况(例如“冥想”数据层)导致的长期请求所致。
和以前一样 ,使用的负载生成器是Pinterest的jbender ,后者又基于Quasar和Comsat的HTTP客户端 。 多亏Quasar光纤, jbender甚至支持来自单个节点的大量并发请求,一个不错的同步API,并且作为负载测试框架而不是单个工具,它提供了很多灵活性和便利性(包括例如响应验证)。
在基准测试特定的等待之后,加载目标提供最小的“ hello” HTTP响应1 ,这是测试并发性的非常简单的方法:等待时间越长,请求持续时间和加载目标必须支持的并发级别越高避免请求队列。
对于负载情况,只有第一个基准是最大并发基准,它的唯一目的是测量可以同时处理的实际最大请求数。 为此,它会启动尽可能多的请求,并让它们等待很长时间。 其余所有负载情况都是目标速率 ,这意味着它们衡量负载目标在某个目标请求频率下的行为方式,而不管它们是否可以(或不能)以足够快的速度分派请求2 。 更详细的描述如下:
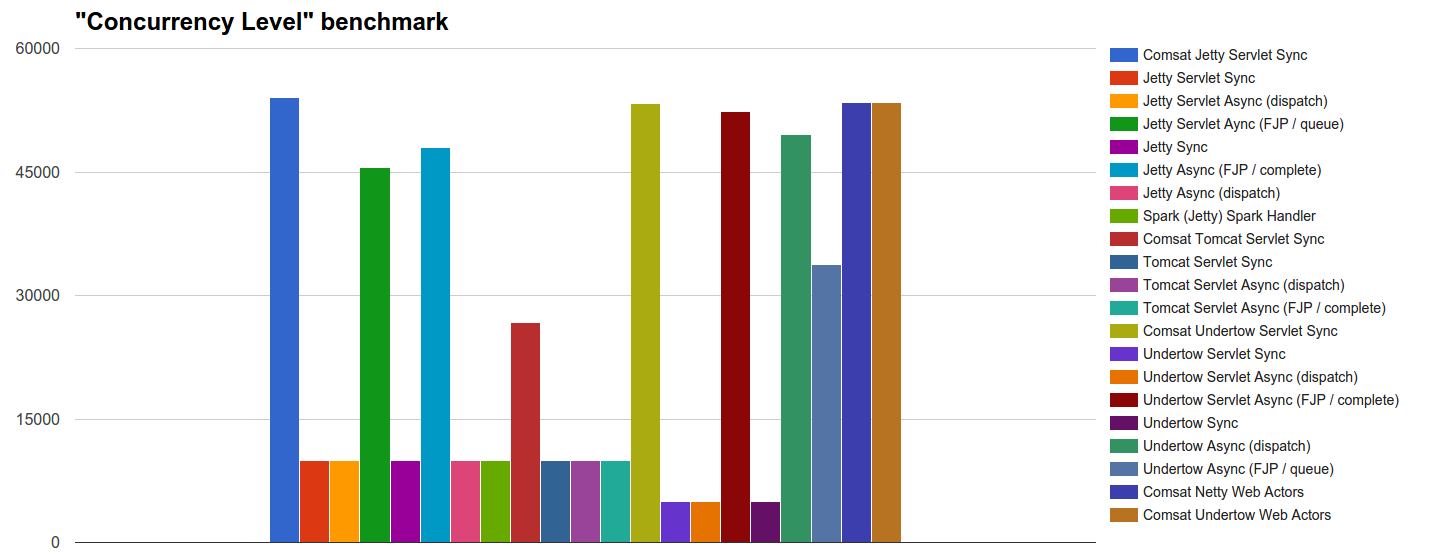
- 并发级别 :我们测试在54k个并发传入请求中,每个服务器可以开始处理多少个。
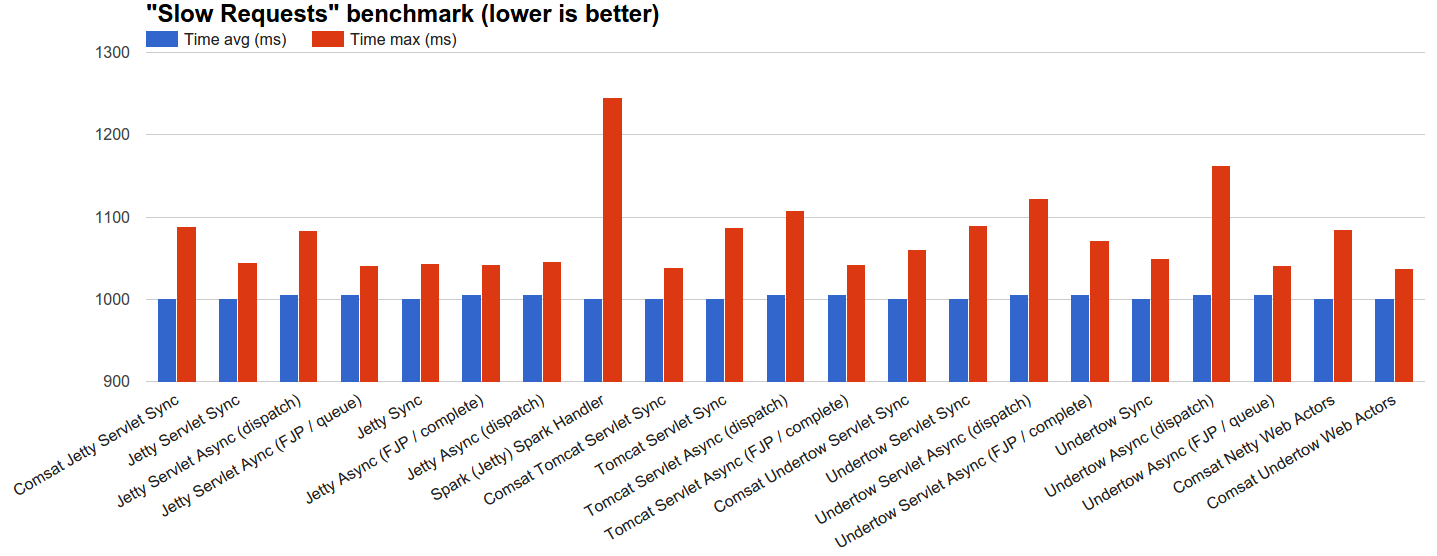
- 慢速请求 :我们让服务器处理使用JBender的指数间隔生成器分发的100k个请求,目标速率为1k rps,每个请求等待1s然后完成。 基本原理是查看每个服务器在合理的并发慢速请求负载下的行为。
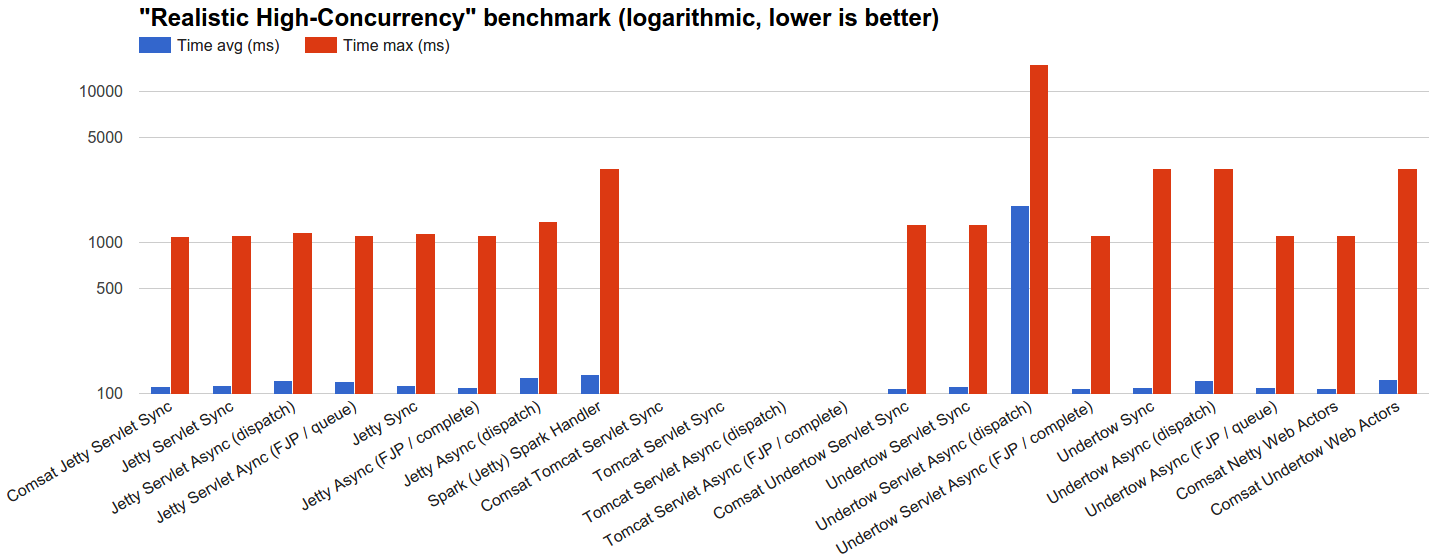
- 现实的高并发性 :我们让服务器处理10万个请求,这些请求使用JBender的指数间隔生成器分发,目标为10k rps,每个请求等待100ms然后完成。 基本原理是查看每台服务器在并发请求的高负载下的行为方式,其生存期可以合理地表示某些OLTP 。
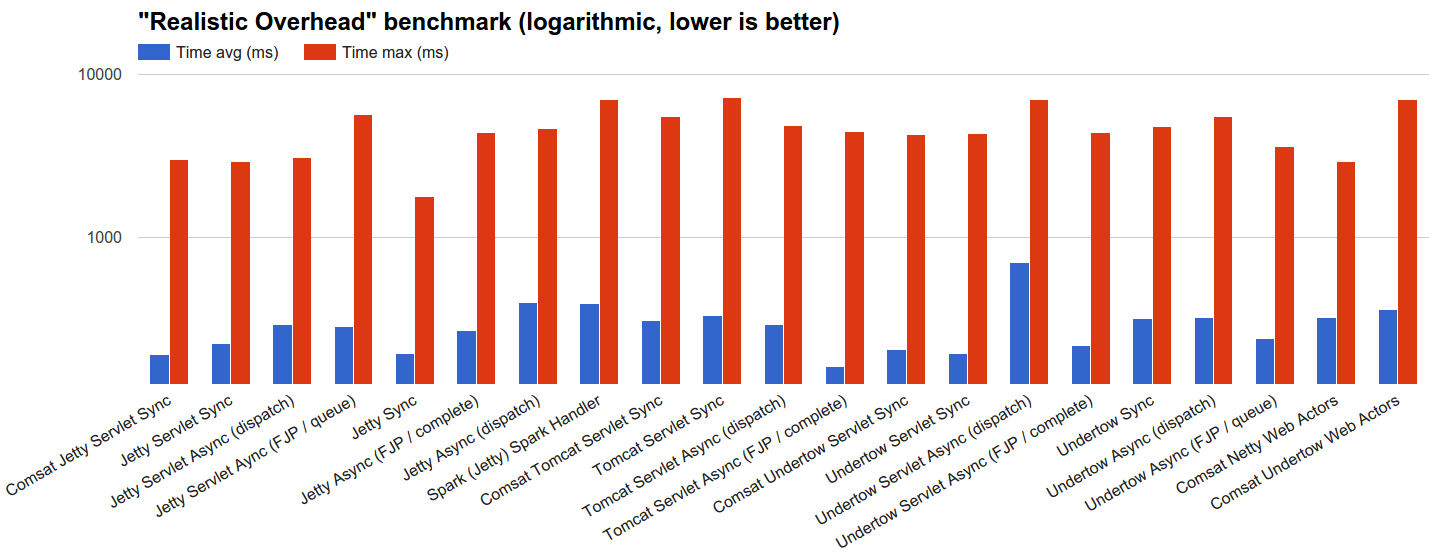
- (更多一点)实际开销 :我们让服务器处理使用JBender指数间隔生成器以100k rps为目标分发的10万个请求,其中每个请求立即完成:我们将看到每个服务器在输入请求严重泛滥的情况下的行为。根本没有处理时间。 由于网络速度尽可能快(请参阅下一部分),但实际上已经存在 (并且不是
localhostloopback ),因此该基准测试的基本原理是检查实际请求处理开销对性能的影响,该开销通常包括最好的情况)是快速的网络和快速的OS(当然还有服务器的软件堆栈)。
由于我们正在测试JVM服务器,并且HotSpot JVM包含JIT配置文件引导的优化编译器 ,因此在上述基准测试2-4之前,我始终以固定的并发级别1000个请求运行初步的100k请求预热。 每个图都是10次运行的最佳结果,在这10次运行中,既未停止装入目标也未停止装入生成器,以便为JVM提供最佳机会来优化代码路径。
基于comsat-httpclient JBender负载生成器(基于Apache的异步HTTP客户端 4.1 )已用于基准测试1、2和3以及预热测试,而comsat-okhttp (基于OkHttp 2.6异步) ,它对于短期请求的性能往往更好,已用于基准测试4。两者的设置如下:
- 没有重试。
- 1h读/写超时。
- 最大连接池。
- 工作线程的数量等于内核的数量。
- Cookie禁用,因此每个请求都属于一个新创建的会话3 。
系统篇
已采取一些系统预防措施:
- 我们不希望负载生成器和服务器进程相互窃取资源,因此必须将它们分开到足以实现资源隔离的程度。
- 我们不希望负载生成器成为瓶颈,因此让它使用大量资源(相对于服务器)和最佳JVM性能设置(当然,我们也希望使用服务器)是最安全的。
- 我们希望网络实际上在那儿,以便我们模拟一个现实的场景,但我们也希望它尽可能快,这样它也不会成为瓶颈。
考虑到上述注意事项,已设置以下基准测试AWS环境:
- 加载目标 :
- AWS EC2 Linux m4.large(8 GB,2 vcpus,具有增强的网络性能,网络性能中等)
-server
-XX:+AggressiveOpts
-XX:+DisableExplicitGC
-XX:+HeapDumpOnOutOfMemoryError
-Xms4G -Xmx4G- 负载生成器 :
- AWS EC2 Linux m4.xlarge(16 GB,4 vcpus,具有增强网络功能的高性能网络)
-server
-XX:+AggressiveOpts
-XX:+DisableExplicitGC
-XX:+HeapDumpOnOutOfMemoryError
-Xms12G -Xmx12G -XX:+UseG1GC -XX:MaxGCPauseMillis=10与“ t”等其他一些类型相比,AWS EC2“ m”个虚拟实例旨在提供更可预测的性能。
AWS内部网络承担基准负载,并且实例位于相同的区域和可用的区域中,以实现最佳连接。
有关JVM设置的一些注意事项:
- 负载生成器使用了12GB的堆内存。 G1垃圾收集器试图最大程度地减少暂停并保持高吞吐量,已成为6GB堆以上的可行选择,并且已被用来在负载生成期间最大程度地减少抖动。
- 加载目标使用了4GB的堆内存; 这是一个适中的数量,但不足以利用G1,因此改用了默认的吞吐量优化收集器。 基本原理是代表服务器环境,在该环境中内存可用性足够但仍然受到一定限制(例如,出于成本原因,例如基于云的服务器机群)。
基于JBender建议的一些细微变化,已经在负载生成器和服务器系统上执行了Linux OS调整。
负载目标和负载生成器代码
这些基准测试的代码最初是由nqzero的jempower派生的 ,该功能在最近的基准测试帖子中 jempower介绍,该帖子又来自TechEmpower的。 使用Capsule (而不是脚本)将其转换为完整的JVM,多模块Gradle项目。
为了使处理程序与服务器技术和负载目标分离,代码也进行了实质性的重构,每个处理程序都将处理程序与支持其API的技术集成在一起。 还对其进行了重构,以共享尽可能多的逻辑和设置。
我还为线程阻塞和Comsat(光纤阻塞)同步API以及有趣的异步变量添加了更多的加载目标,并且由于库似乎没有维护,我删除了Kilim目标。
匹配的API和服务器技术:加载目标
基准测试包含基于多种API和服务器技术的多个负载目标:
- 以下服务器技术上的标准同步JEE Servlet API:
- 未完成
1.3.15.Final
- 未完成
- 标准异步JEE Servlet API(
startAsync&friends,3.0 +),具有容器提供的执行器(dispatch)和用户提供的执行器(complete),它们都与上述服务器技术相同。 - 非标准化的Comsat Web Actors API
0.7.0-SNAPSHOT(0.6.0,进一步修复和改进了Web actor),它将传入(请求)和出站(响应)队列附加到接收传入请求的真正的轻量级顺序进程(光纤)并通过简单,同步和有效的(特别是光纤阻塞而不是线程阻塞)receive和send操作发送响应。 这些过程是成熟的Erlang风格的参与者 4 。 目前,Web Actor可以在servlet容器上运行,既可以作为Undertow处理程序 ,也可以作为本地Netty处理程序运行 ; 本机Netty和Undertow部署已包含在基准测试中。 Netty版本是4.0.34.Final和Undertow与上面相同。 - 与上述相同的Jetty上的非标准化Jetty嵌入式API (同步和异步5) 。
- 与上述相同的Undertow上的非标准化的Undertow处理程序API (同步和异步)。
- 使用Jetty
9.3.2.v20150730的非标准化Spark服务器/处理程序API2.3。
同步处理程序是最简单的处理程序:它们将在启动该请求的同一OS线程(或使用Comsat时使用fiber )中执行整个请求处理。 通过直接的线程(或光纤)睡眠来实现响应之前的等待。
异步处理程序更加复杂,因为它们推迟了请求的完成,并且需要执行其他簿记和调度工作。 所有这些都将通过立即将待处理的请求存储在静态数组中开始,以后每隔10毫秒安排一次的TimerTask从中提取它们以进行处理,这时策略会根据处理程序而有所不同:
- 使用
dispatch异步处理程序会将请求处理作业调度到服务器提供的执行程序。 当等待时间不为0时,将通过直接线程Hibernate来实现。 - 其他异步处理程序不依赖服务器提供的执行程序,而是使用以下不同策略开始处理请求。 但是,如果等待时间不为0,则所有这些对象都将进一步将完成作业分派给
ScheduledExecutorService:这将模拟一个完全非阻塞的实现,其中通过异步API执行外部(例如,DB,微服务等)调用也一样ScheduledExecutor的最大线程数将与服务器提供的执行器的最大线程数相同。- FJP :使用默认设置将请求处理作业分派到fork-join池。
“每个会话” Web Actor的目标是每个会话产生一个actor,并且由于cookie被禁用,这意味着每个请求都由由其自己的光纤6支持的不同actor处理。
HTTP服务器资源设置偏向于基于线程的同步技术,该技术可以使用比异步/光纤线程更多的OS线程:这是因为实际上,如果要以高并发性使用它们,将不得不这样做。场景。 除此之外,相同的HTTP服务器设置已尽可能统一地使用:
- 同步服务器和使用
dispatch异步服务器在进行区分的Undertow上最多使用5k I / O线程加5k工作者线程,在Tomcat,Jetty和Spark上最多使用10k通用处理线程。 - 在Tomcat,Jetty和Netty上运行的其他异步服务器最多使用100个处理线程。
- 在Undertow上运行的其他异步服务器最多可以使用50个I / O线程和50个工作线程。
- 套接字接受队列(又称积压)最多可以保持10k个连接。
- 会话有效期为1分钟。
- 对于Tomcat,Jetty,Netty和Undertow
TCP_NODELAY明确设置为true。 - 对于Jetty,Netty和Undertow
SO_REUSEADDR显式设置为true。
数据
您可以直接访问基准的电子表格,这是统计信息:
| HTTP服务器基准 | “并发级别” | “缓慢的请求” | “现实的高并发性” | “现实开销” | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 加载目标 | 最高 | 错误编号 | 时间平均(毫秒) | 最长时间(毫秒) | 错误(#) | 时间平均(毫秒) | 最长时间(毫秒) | 误差(%) | 时间平均(毫秒) | 最长时间(毫秒) | 错误(#) |
| Comsat Jetty Servlet同步 | 54001 | 0 | 1000.777 | 1088.422 | 0 | 110.509 | 1103.102 | 0 | 189.742 | 3015.705 | 0 |
| Jetty Servlet同步 | 9997 | 0 | 1000.643 | 1044.382 | 0 | 112.641 | 1114.636 | 0 | 222.452 | 2936.013 | 0 |
| Jetty Servlet异步(调度) | 9997 | 0 | 1005.828 | 1083.179 | 0 | 121.719 | 1173.357 | 0 | 289.229 | 3066.036 | 0 |
| Jetty Servlet Aync(FJP /队列) | 45601 | 4435 | 1005.769 | 1041.236 | 0 | 119.819 | 1120.928 | 0 | 281.602 | 5700.059 | 0 |
| 码头同步 | 9997 | 54 | 1000.645 | 1043.857 | 0 | 113.508 | 1143.996 | 0 | 193.487 | 1779.433 | 0 |
| 码头异步(FJP /完整) | 47970 | 1909年 | 1005.754 | 1041.76 | 0 | 109.067 | 1120.928 | 0 | 266.918 | 4408.214 | 0 |
| 码头异步(调度) | 9997 | 0 | 1005.773 | 1045.43 | 0 | 127.65 | 1385.169 | 0 | 397.948 | 4626.317 | 0 |
| Spark(码头)Spark Handler | 9997 | 58 | 1000.718 | 1245.708 | 0 | 134.482 | 3118.465 | 0 | 391.374 | 7021.265 | 0 |
| Comsat Tomcat Servlet同步 | 26682 | 13533 | 1000.636 | 1039.139 | 0 | 不适用 | 不适用 | 不适用 | 307.903 | 5523.898 | 0 |
| Tomcat Servlet同步 | 9999 | 0 | 1000.625 | 1087.373 | 0 | 不适用 | 不适用 | 不适用 | 329.06 | 7239.369 | 0 |
| Tomcat Servlet异步(调度) | 9999 | 0 | 1005.986 | 1108.345 | 0 | 不适用 | 不适用 | 不适用 | 289.703 | 4886.364 | 0 |
| Tomcat Servlet异步(FJP /完整) | 9999 | 29965 | 1005.891 | 1041.76 | 0 | 不适用 | 不适用 | 不适用 | 159.501 | 4483.711 | 0 |
| Comsat Undertow Servlet同步 | 53351 | 0 | 1000.648 | 1060.635 | 0 | 107.757 | 1309.671 | 0 | 204.795 | 4273.996 | 0 |
| Undertow Servlet同步 | 4999 | 7758 | 1000.723 | 1089.47 | 0 | 110.599 | 1319.109 | 0 | 193.436 | 4307.55 | 0 |
| Undertow Servlet异步(调度) | 4999 | 576 | 1006.011 | 1123.025 | 0 | 1756.198 | 15183.38 | 83 | 697.811 | 6996.099 | 0 |
| Undertow Servlet异步(FJP /完整) | 52312 | 1688 | 1005.81 | 1071.645 | 0 | 108.324 | 1113.588 | 0 | 214.423 | 4408.214 | 0 |
| 同步下 | 4999 | 0 | 1000.644 | 1049.625 | 0 | 108.843 | 3114.271 | 0 | 316.991 | 4789.895 | 0 |
| Undertow异步(调度) | 49499 | 4501 | 1005.742 | 1162.871 | 0 | 121.554 | 3116.368 | 0 | 318.306 | 5486.15 | 0 |
| Undertow异步(FJP /队列) | 33720 | 0 | 1005.656 | 1040.712 | 0 | 109.899 | 1113.588 | 0 | 236.558 | 3632.267 | 0 |
| Comsat Netty网络演员 | 53448 | 0 | 1000.701 | 1085.276 | 0 | 107.697 | 1106.248 | 0 | 320.986 | 2917.138 | 0 |
| Comsat Undertow网络演员 | 53436 | 0 | 1000.674 | 1037.042 | 0 | 123.791 | 3118.465 | 0 | 358.97 | 7046.431 | 0 |
这是图形:
结果
错误主要是“连接重置”(可能是由于接受时变慢),尽管在极端情况下,处理变慢导致并发超过了网络接口可用的端口数。
一些特定于基准的注意事项:
- 并发级别 :此基准清楚地显示了每个负载目标实际上可以同时处理多少个请求。 除了所有基于Tomcat的技术外 ,几乎所有非
dispatch异步处理程序以及Comsat处理程序都允许大多数请求立即启动。 其他技术允许启动的请求最多与其线程池的最大大小一样多:剩余的传入请求可能将由TCP接受器线程连接,但是直到该池中的某些线程变为空闲时才开始处理。 - 请求缓慢 :在这种情况下,很快就会达到平衡,在整个基准时间内平均有1000个线程(或光纤)同时执行。 在这里,同步服务器往往表现最佳,其中包括Comsat Servlet和Web Actor,而异步技术则为额外的簿记机制支付开销。
- 现实的高并发性 :在此基准测试中,负载目标承受着强大的高并发压力,这使异步和Comsat技术表现良好,而线程阻塞,
dispatch和Tomcat技术落后或什至存在严重问题,难以跟上步伐。 值得注意的例外是Jetty和Undertow同步处理程序,它们的性能非常好,这可能是由于明智的连接管理策略引起的,尽管原因还不完全清楚,需要进行更多调查。 Tomcat负载目标未能成功完成这些测试,因此在特定数量的已完成请求和大量错误之后,调查导致它们挂在0%CPU使用率上的原因是很有趣的。 - 实际开销 :负载目标只需要尽快发送回响应,因为没有等待时间。 在这种情况下,异步处理程序不使用
ScheduledExecutor,其吞吐量限制由总体技术开销确定。
请求完成时间的分布也有一些考虑因素:该基准测试的负载生成器使用了由JBender提供的基于Gil Tene的HDRHistogram的事件记录器。 您可以直接访问直方图数据。
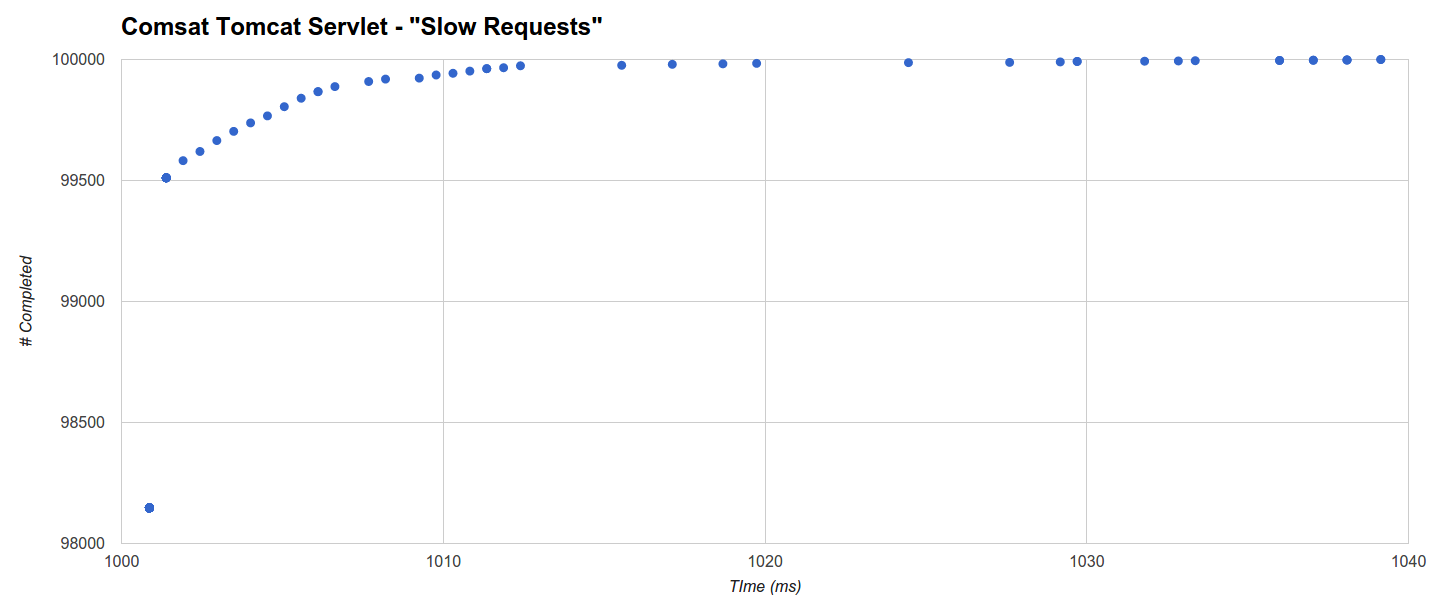
关于“慢请求”基准的最短最长时间的直方图显示,Comsat Tomcat Servlet(次优)在绝对最小的1秒(睡眠时间)的1毫秒内完成了100000个请求中的98147个请求,而其余请求的完成时间分布在1001.39毫秒和1039.139毫秒之间(最大值):
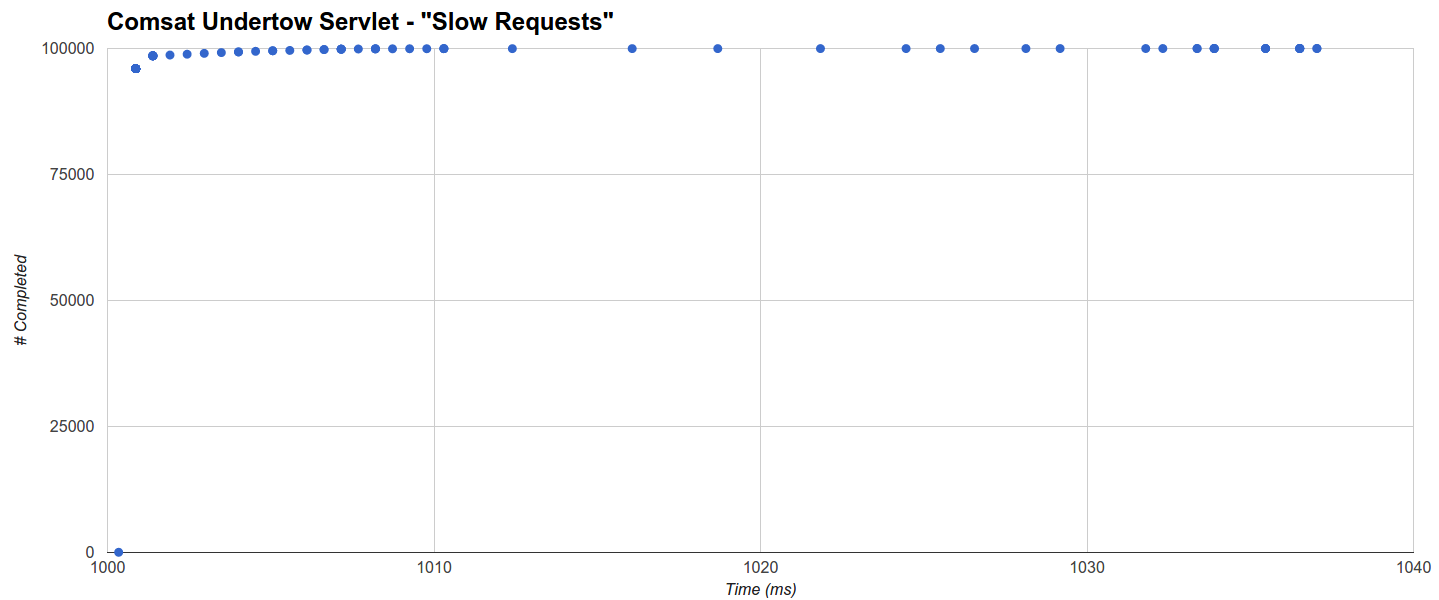
Comsat Undertow Servlet的最大延迟时间最短,但是平均延迟会稍差一些,因为它在1001毫秒内完成了约96%的请求,而其余的则均匀地分布到1037.042毫秒(最大):
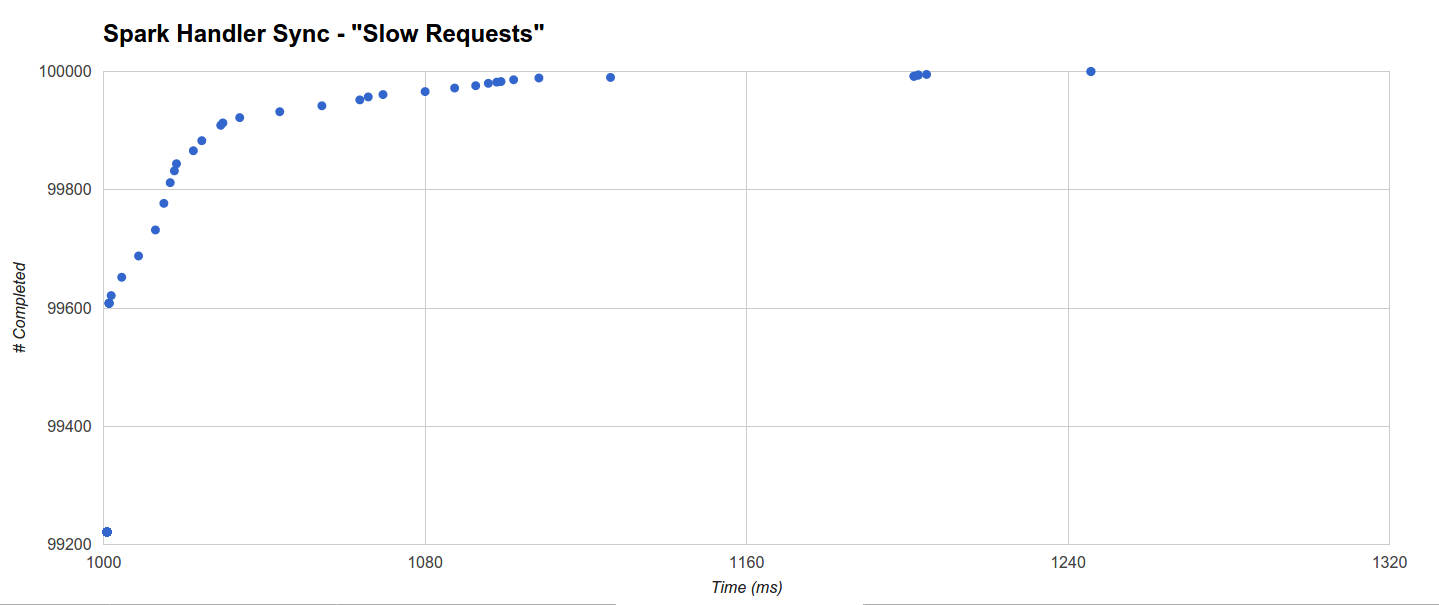
另一方面,Spark(最差)的分布不太均匀:它在1001ms(99221)内完成的工作更多,但很少有其他请求可以占用1245.708ms(最大):
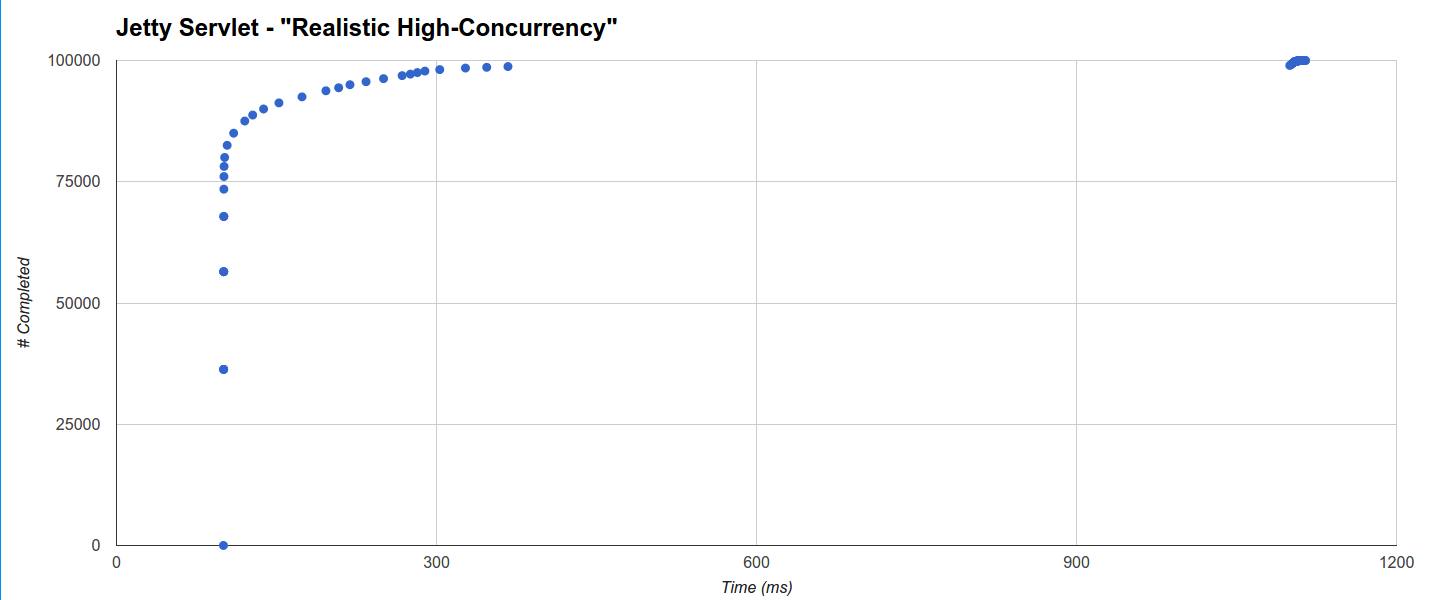
在“ Realistic High Concurrency”中,Comsat Jetty Servlet产生了最短的最大延迟,但是线程阻塞Jetty Servlet的目标紧随其后:它在101ms内完成了78152个请求(最小等于100ms的睡眠时间)并完成了其余的分布在两个不同的群集中,一个群集从100ms到367ms有规律地分布,另一个群集在1100ms到1114.636ms的最大值之间:
Comsat Jetty Servlet的目标行为非常相似:75303个请求在101ms内完成,几乎所有其余请求在328.466ms内完成,只有48个在1097ms左右(最大1103.102ms)内完成:
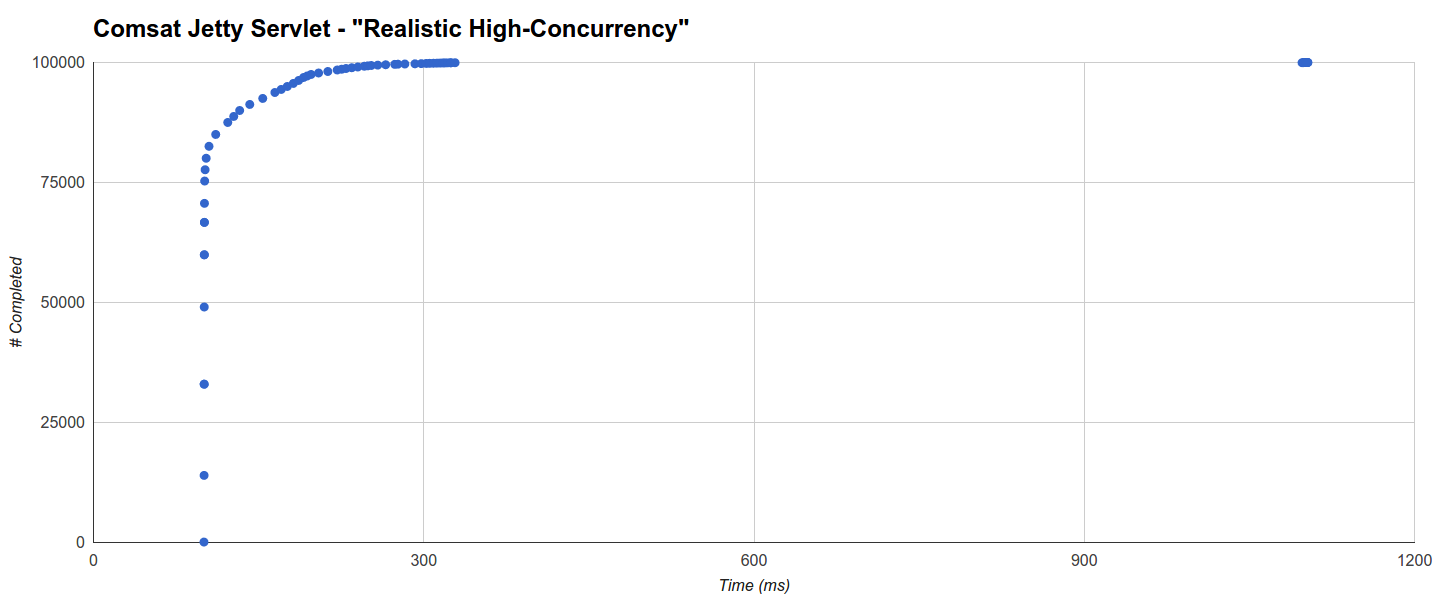
有趣的是,从主群集到“尾巴”的距离大致对应于该运行的最大GC暂停时间(576毫秒)。
基于稍早的9.3 Jetty构建的Spark表现出类似的行为,但是第一个集群的时间分布更多(超过一半,或者请求在101ms和391ms之间完成),另外还有大约1300ms和3118ms(其“尾”集群)距离太粗略地对应于该运行的最大GC时间(即1774ms):
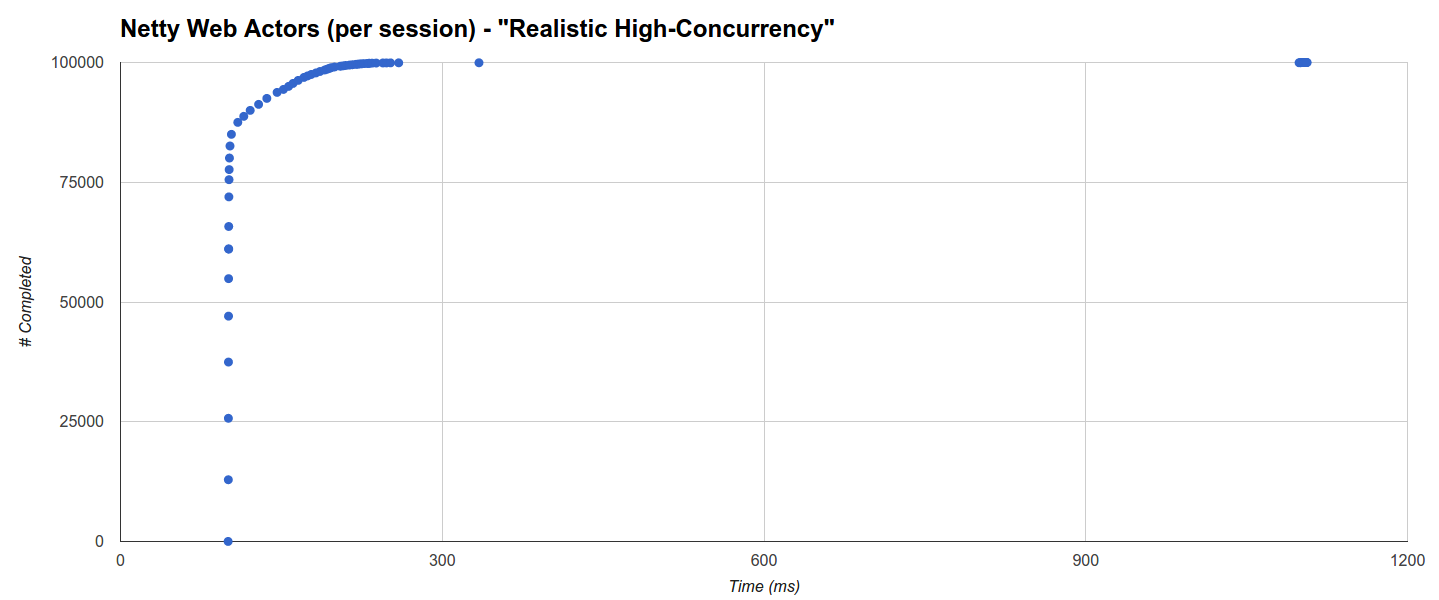
Comsat Netty Web Actor的分布(每次会话)是不同的:大约66%的分布在101毫秒内完成,而85%的分布在103.5毫秒内,然后直到ca. 260毫秒,此时有一个中断,一个群集发生在334毫秒,最后一个群集发生在1098毫秒至1106毫秒之间。 在这种情况下,似乎与GC活动无关,后者与预期的要高得多,并且最长GC时间超过4s:
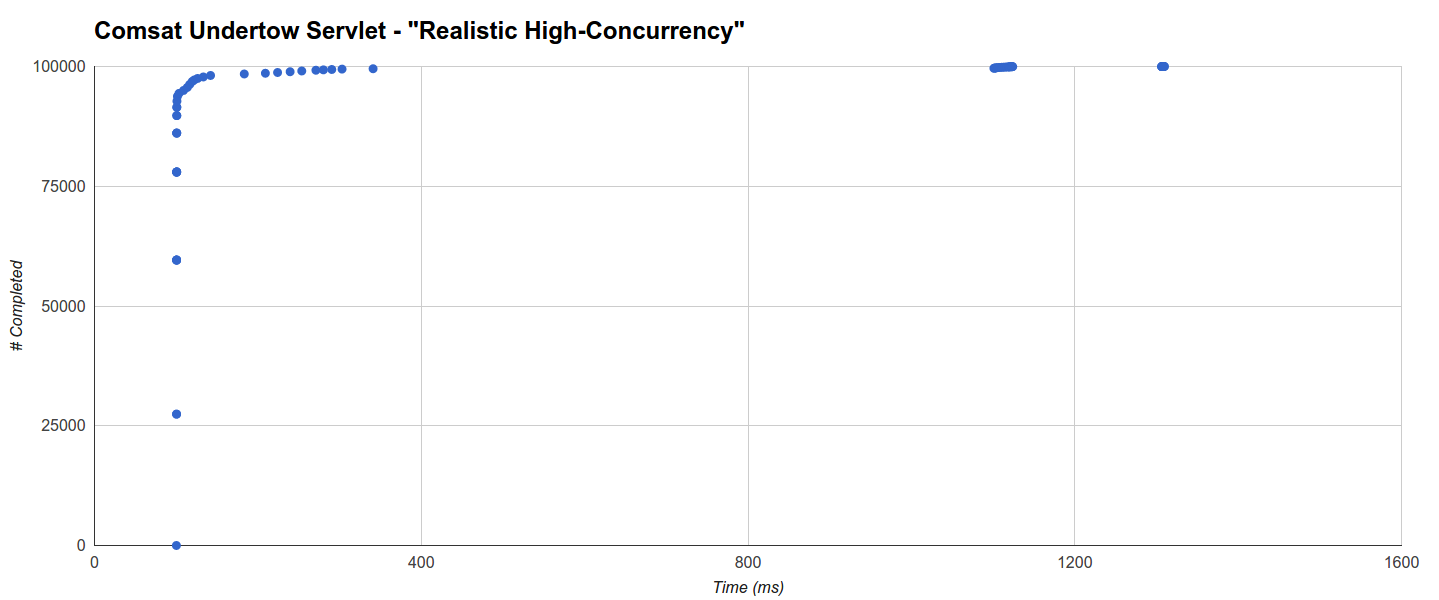
相反,Undertow的GC开销非常低,包括与Quasar光纤集成时(在后一种情况下,运行6个GC时最长为407ms)。 具体来说,Comsat Undertow Servlet在101毫秒内完成了超过92.5%的请求,一个长达341毫秒的主集群包含了99.5%的请求,以及另外两个似乎与GC活动没有严格关联的集群:
Undertow Sync的图形非常相似,主群集更加紧密,在101毫秒内完成了90%以上的请求,从而获得了非常好的平均值,但附加的尾部群集使最大值进一步超过了3秒。
最终,使用dispatch调用的Undertow异步Servlet的性能最差,并且其多集群分发在15秒内非常缓慢地上升! 群集距离似乎与最大GC运行时间没有特别的关系:
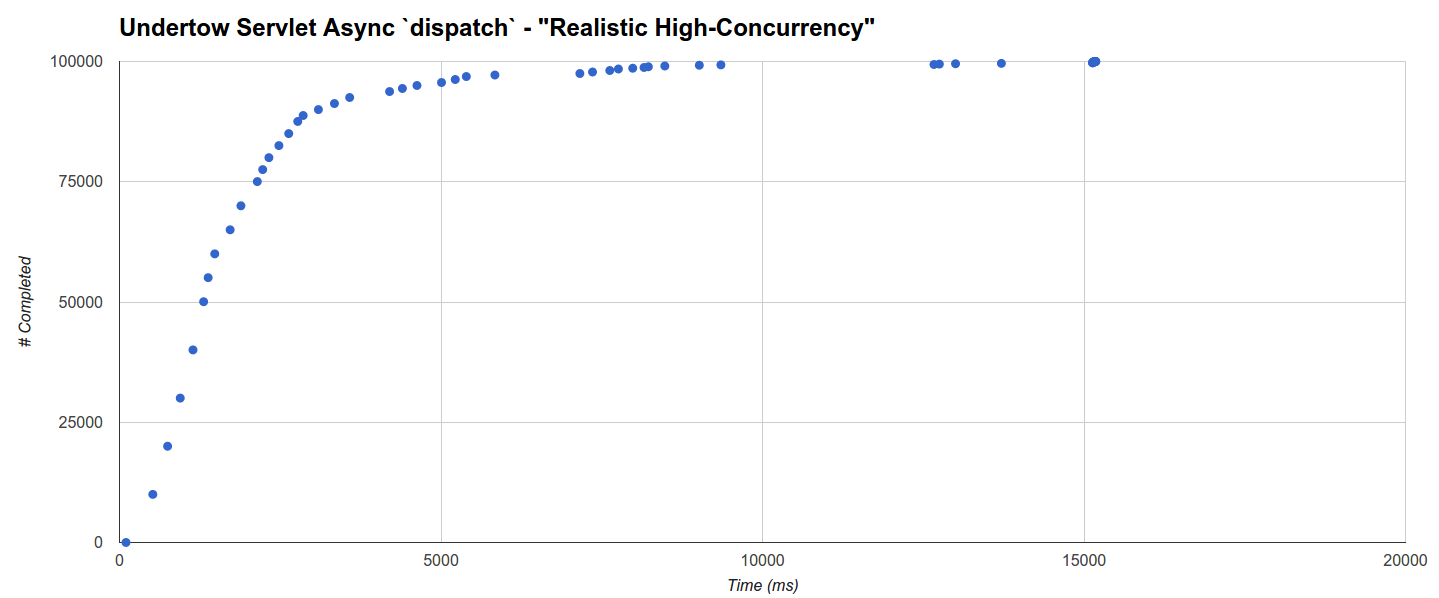
在“现实开销”基准中,此负载目标的性能也很差,这表明Undertow可能不太理想地实现了dispatch servlet异步调用。
这些观察结果认为,在中高并发情况下,高延迟似乎与底层网络/ HTTP技术的关联更多,而不是与请求处理技术或API的关联,在某些情况下,更具体地,与敏感性相关。由GC活动引起的抖动。 它还表明分布的主要集群也与基础网络/ HTTP技术相关。
除了使用dispatch Undertow Servlet Async之外,“现实开销”直方图显示了具有2或3个不同趋势的所有目标所共有的均匀分布的结构:一个关于快速完成的请求,直到一个目标特定的数目,另一个关于包括已完成的剩余请求的请求更慢。
例如,Jetty Sync Handler目标(最佳)在31.457毫秒内完成了75%的请求,而其他请求似乎平均分配,直到最大1779.433毫秒:
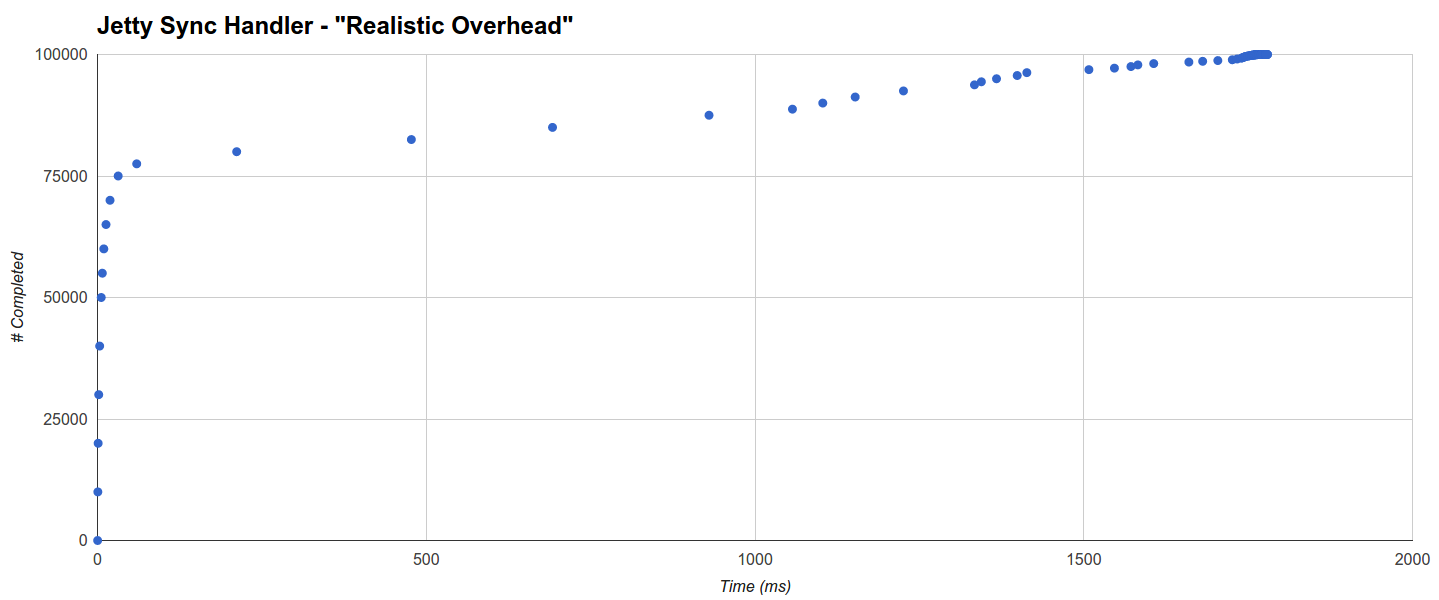
它的GC活性也非常有限(3次运行,最长113ms)。
Tomcat Servlet最差,其中65%的请求在32.621ms内完成,99219个请求在2227ms内完成,并且进一步的趋势是,仅ca的完成时间增加了5s。 80个请求。 在这种情况下,GC干预也很低(尽管比Jetty更高):
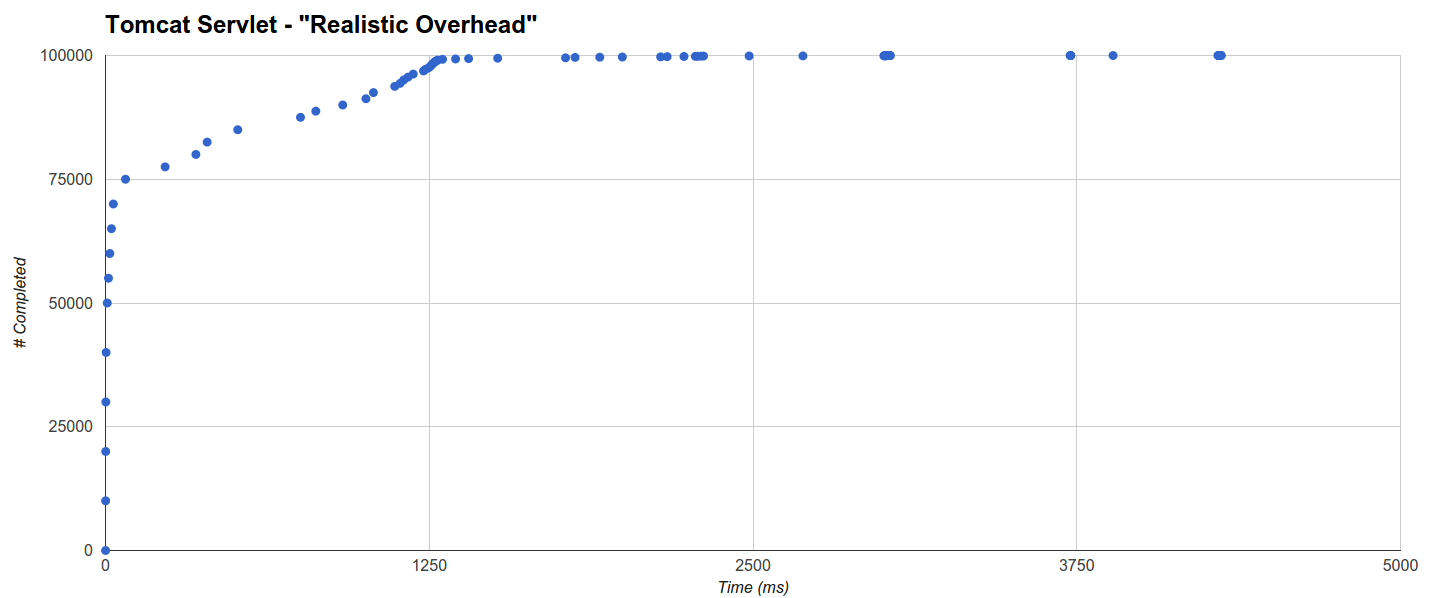
经验教训
结果导致一些重要的考虑:
- 如果您不处理高并发情况,则无需考虑异步库,因为基于光纤和线程的服务器可以完美运行,并且同样重要的是,它们将允许您编写高度可读,可维护且面向未来的同步代码。
- 即使在高并发情况下,也确实不需要跳入异步陷阱,因为基于光纤的服务器具有广泛的适用性:借助Quasar光纤,您可以在一个单一的服务器中获得非常高的并发性,非常好的通用性能和面向未来的代码包。
- 必须说,即使在高并发情况下,某些同步的线程阻塞服务器也设法获得良好的性能,并且确切地了解这绝对是一个有趣的研究。 它们的实际最大并发性比异步或Quasar的低得多,因此,如果您希望尽早开始处理尽可能多的请求,则最好还是使用异步/光纤技术。
- 在零请求处理时间的情况下,即使是同步单线程服务器也可以很好地工作:当请求处理时间增加并且并发效应开始时,麻烦就开始了。
同样,在运行基准测试时(甚至在分析结果之前)所观察到的(和错误)也强调了充分应对某些JVM特有特征的重要性:
- JVM在使用运行时信息优化代码方面做得非常出色:如果您不相信我尝试使用带有
-Xcomp标志(不-Xcomp标志)来运行您的应用程序,该标志将执行预运行JIT,并亲自了解如何获得最佳结果(提示:-Xcomp可能会产生明显较差的性能)。 另一方面,这意味着逐渐进行JVM预热是将HTTP服务器暴露于传入请求之前必须执行的重要步骤,因为未优化的代码路径很容易无法跟上突然的高并发和/或高速率负载会导致或多或少的严重故障。 - 抖动/打cup是一个严重的问题,尤其是对于最大延迟而言,但如果它发生在“糟糕”的时刻(例如,大量传入请求),它甚至可能使系统崩溃。 GC暂停是造成抖动的一个重要原因,因此通常最好仔细考虑JVM内存设置和将要使用的GC。 特别是,基准测试中的最大延迟似乎受到影响,甚至在某些情况下甚至与GC运行有关。 朝着这个方向的另一个提示是,即使在低并发情况下,由于即使在较简单的服务器上,GC压力也会增加,因此使用较小的1GB堆运行的基准测试仍偏爱更复杂的技术(异步和光纤)。 这意味着减少GC的数量和持续时间是值得的,但是我们该怎么做呢? 一种方法是准确选择JVM内存设置,并在可能的情况下使用较低延迟的GC(例如G1或商用JVM Azul Zing) 。 另一种方法是再次选择最简单的工具来完成这项工作:如果您不处于高并发情况下,请使用最简单的技术,因为与更复杂的技术相比,它们将产生更少的垃圾。
- 出于类似的原因,如果您需要会话,则每个会话的Web Actor很棒,因为它们基本上也像Erlang一样启用“每个用户的Web服务器”范例 。 另一方面,如果您不需要会话或那种可靠性,那么您将获得GC开销,因为可能需要为每个请求实例化(然后稍后进行垃圾收集)新的参与者(及其对象图) 。 这反映在“现实开销”结果中。
进一步的工作
虽然此基准可以作为您评估的一个很好的起点,但它绝不是详尽无遗的,可以通过许多方式加以改进,例如:
- 添加更多的负载目标。
- 添加基准案例。
- 在其他系统(例如硬件,其他云,其他AWS实例)上进行基准测试。
- 在非Oracle JVM上进行基准测试。
- 使用不同的JVM设置进行基准测试。
- 进一步分析系统数据。
- 研究奇怪的行为,包括令人惊讶的好行为(例如,高并发情况下的Jetty线程阻塞同步服务器)和出奇的坏行为(例如,Undertow的基于
dispatch的处理程序和Tomcat Servlet)。 - 更好地分析相关性,例如GC引起的抖动和统计数据之间的相关性。
尽管这是一项昂贵的工作,但我认为通常仍需要更多的基准测试,因为这实际上可以更好地理解,改进和评估软件系统。
结论
此处的主要目标是查看不同的HTTP服务器API和技术如何在更接近真实的场景中执行,在这些场景中,具有预定系统资源的单独的客户端和服务器JVM进程通过真实网络进行通信,并且请求处理为非零时间。
事实证明,Quasar光纤可用于构建承受高并发负载的多功能执行器,并且至少同样重要的是,与异步API相比,它们是更好的软件编写工具。 事实再次证明,没有灵丹妙药:不同的情况需要不同的解决方案,甚至有时被认为是过时的技术(例如线程阻塞服务器(甚至单线程服务器))也可以胜任。
除了性能以外,API的选择还应在您的决定中起主要作用,因为这将决定服务器代码的未来。 根据情况,根据项目的需求和开发环境,非标准API(及其相关风险,采用和退出成本)可能是可行的,也可能不是可行的选择。 要考虑的另一件事是,异步API比同步API难用得多,并且倾向于通过异步7感染整个代码库,这意味着使用异步API可能会妨碍代码的可维护性并缩短其未来。
也就是说,我完全意识到以下事实:性能基准会尽力而为,以有限的工具和知识不断变化的局面(和使用)不断变化,设计,运行和发布基准是一项艰苦的工作,也是一项重大的投资。 。
我希望这一轮对许多人有用,我将热烈欢迎和赞赏并鼓励任何建议,改进和进一步的努力。
- 纯I / O的数量故意减少到最低限度,因为我不是,并且我仍然不希望检查套接字的读/写效率。 ↩
- 当然,即使目标利率基准也不能完全代表实际情况,因为该利率很少是固定的和/或事先知道的,但是我们至少可以看到发生的情况,例如某些最坏的情况。
- 仅与会话感知的API和技术相关。
- 无论您是否喜欢参与者,都可以使用
for(;;) { reply(process(receive())); }在JVM上处理HTTP请求的能力for(;;) { reply(process(receive())); }for(;;) { reply(process(receive())); }在附加到呼入/呼出队列轻量级线程环是什么个人而言,我一直想要的。 更重要的是,它带来了全新的可靠性, 几乎就像每个用户都有自己的Web服务器一样 。 - 它们基于Servlet,但不完全相同,尤其是设置/配置部分。
- 基于Netty和Undertow的Web Actor部署提供了现成的
per-session策略,但是它们还允许使用开发人员提供的策略以编程方式将actor分配给请求。 - 这是因为调用异步函数的代码要么需要传递某种回调,要么需要处理future或promise返回值(这反过来意味着要么在等待结果的同时阻塞线程,要么尽可能)。告诉有空的人如何继续)。
翻译自: https://www.javacodegeeks.com/2016/05/benchmarking-high-concurrency-http-servers-jvm.html
jvm高并发















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









