





 Apache Lucene是一个高性能的全文本搜索引擎库,支持跨平台,能对多种文件格式进行索引。通过创建倒排索引,Lucene实现了更快的搜索。文章介绍了Lucene的安装、工作原理、核心类别、目录、分析仪、字段属性定义以及搜索示例。还提到了诊断工具Luke和Limo,提供了一个完整示例和相关资源链接。
Apache Lucene是一个高性能的全文本搜索引擎库,支持跨平台,能对多种文件格式进行索引。通过创建倒排索引,Lucene实现了更快的搜索。文章介绍了Lucene的安装、工作原理、核心类别、目录、分析仪、字段属性定义以及搜索示例。还提到了诊断工具Luke和Limo,提供了一个完整示例和相关资源链接。
lucene索引搜索

什么是Lucene?
Apache LuceneTM是完全用Java编写的高性能,功能齐全的文本搜索引擎库。 它是一项适用于几乎所有需要全文本搜索的应用程序的技术,尤其是跨平台。
Lucene可以纯文本,整数,索引PDF,Office文档。 等等。,
Lucene如何启用“更快的搜索”?
Lucence创建了一个称为倒排索引的东西。 通常我们在文档中映射文档->术语。 但是,Lucene则相反。 创建索引词->包含该词的文档列表,这使搜索速度更快。
安装Lucene
Maven依赖
<pre class='brush:xml'><dependency>
<groupid>org.apache.lucene</groupid>
<artifactid>lucene-core</artifactid>
<version>3.0.2</version>
<type>jar</type>
<scope>compile</scope>
</dependency>下载依赖
从http://lucene.apache.org/下载Lucene,并将lucene-core.jar添加到类路径中
Lucene如何工作?
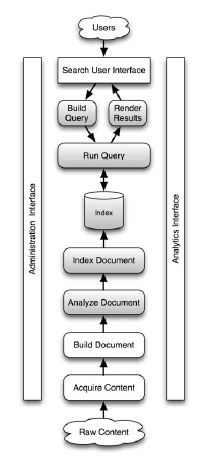
首先让我们从底部开始了解图片-中心。 原始文本用于创建Lucene“文档”,使用指定的分析器对其进行分析,然后根据字段的Store,TermVector和Analzed属性将文档添加到索引中。
接下来,从上到下搜索。 用户以文本格式指定查询。 查询对象是基于查询文本构建的,执行查询的结果作为TopDocs返回。
核心Lucene类别
| 目录,FSDirectory,RAMDirectory | 包含索引的目录 基于文件系统的索引目录 基于内存的索引目录 | 目录 indexDirectory = FSDirectory.open(新文件('c:// lucene // nodes')); |
| 索引作家 | 处理写入索引– addDocument,updateDocument,deleteDocuments,merge等 | IndexWriter writer =新的IndexWriter(indexDirectory, 新的StandardAnalyzer(Version.LUCENE_30), 新的MaxFieldLength(1010101)); |
| IndexSearcher | 使用indexReader进行搜索-搜索(查询,整型) | IndexSearcher searcher =新的IndexSearcher(indexDirectory); |
| 文件 | DTO用于索引和搜索 | Document document = new Document(); |
| 领域 | 每个文档包含多个字段。 有2部分,名称,值。 | 新字段('id','1',Store.YES,Index.NOT_ANALYZED) |
| 术语 | 测试一个字。 用于search.2零件。要搜索的字段和要搜索的值 | 条款term = new Term('id','1'); |
| 询问 | 所有查询类型的基础-TermQuery,BooleanQuery,PrefixQuery,RangeQuery,WildcardQuery,PhraseQuery等。 | 查询查询=新的TermQuery(term); |
| 分析仪 | 从文本构建令牌,并帮助从文本构建索引词 | 新的StandardAnalyzer() |
Lucene目录
目录–是Lucene在其上运行的数据空间。 它可以是文件系统或内存。
以下是常用的目录
| 目录 | 描述 | 例 |
| FS目录 | 基于文件系统的目录 | 目录= FSDirectory.open(文件文件); //文件->目录路径 |
| RAM目录 | 基于内存的Lucene目录 | 目录=新的MemoryDirectory() Directory = new MemoryDirectory(Directory dir)//将基于文件的目录加载到内存 |
创建索引条目
Lucene的“文档”对象是索引中使用的主要对象。 文档包含多个字段。 分析器在文档字段上进行工作以将其分解为令牌,然后使用索引编写器写入目录。
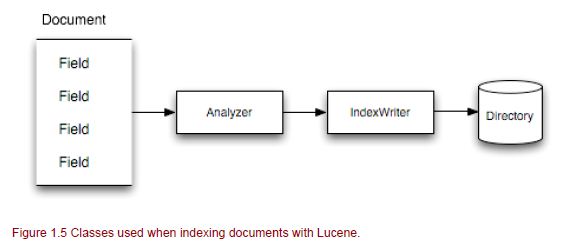
索引作家
IndexWriter writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_30), true, MaxFieldLength.UNLIMITED);分析仪
将文本分析为要搜索的标记或关键字的工作。 Lucene提供的默认分析器很少。 分析器的选择定义了如何对索引文本进行标记和搜索。
以下是一些标准分析仪。
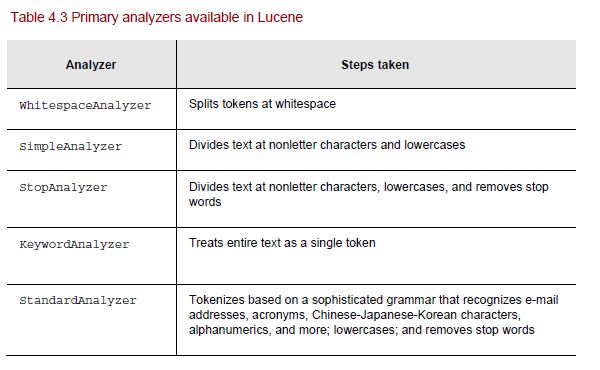
示例–分析器如何处理示例文本

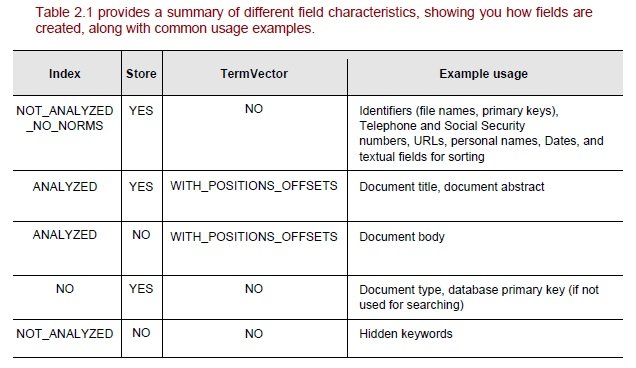
定义字段索引的属性
- 存储–是否应存储该字段以便将来检索
- 分析–应将内容拆分为令牌
- TermVECTOR –是否存储基于术语的详细信息
店铺:
该字段是否应存储以便以后撤退
| 是的 | 存储值,以后可以从索引中检索 |
| 商店编号 | 不要储存。 与Index.ANALYZED一起使用。 当令牌仅用于搜索时 |
分析:
如何分析文字
| 索引分析 | 将文本分解为标记,对每个标记编制索引以使其可搜索 |
| 索引:NOT_ANALYZED | 将整个文本作为单个标记编制索引,但不要进行分析(拆分) |
| Index.ANALYZED_NO_NORMS | 与ANALYZED相同,但不存储规范 |
| 索引:NOT_ANALYZED_NO_NORMS | 与NOT_ANALYZED相同,但没有规范 |
| 索引号 | 别 使该字段完全可搜索 |
词向量
相似,突出显示等需要术语详细信息
| TermVector.YES | 记录 每个文档中的唯一条款+计数+无位置+无偏移 |
| TermVector.WITH_POSITIONS | 记录 每个文档中的唯一条款+计数+位置+无偏移 |
| TermVector.WITH_OFFSETS | 记录 每个文档中的唯一条款+计数+无位置+抵消 |
| TermVector.WITH_POSITIONS_OFFSETS | 记录 每个文档中的唯一条款+计数+位置+偏移 |
| TermVector.NO | 不要记录术语向量信息 |
创建索引的示例
IndexWriter writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_30), true,MaxFieldLength.UNLIMITED);
Document document = new Document();
document.add(new Field('id', '1', Store.YES, Index.NOT_ANALYZED));
document.add(new Field('name', 'user1', Store.YES, Index.NOT_ANALYZED));
document.add(new Field('age', '20', Store.YES, Index.NOT_ANALYZED));
writer.addDocument(document);更新索引的示例
IndexWriter writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_30), true,MaxFieldLength.UNLIMITED);
Document document = new Document();
document.add(new Field("id", "1", Store.YES, Index.NOT_ANALYZED));
document.add(new Field("name", "user1", Store.YES, Index.NOT_ANALYZED));
document.add(new Field("age", "20", Store.YES, Index.NOT_ANALYZED));
writer.addDocument(document);删除索引的例子
IndexWriter writer = new IndexWriter(indexDirectory, new StandardAnalyzer(Version.LUCENE_30), MaxFieldLength.UNLIMITED);
Term term = new Term('id', '1');
writer.deleteDocuments(term); 搜索索引: 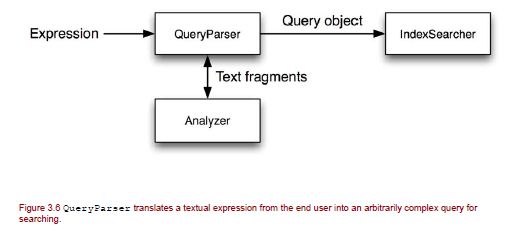 用户以文本格式指定查询。 根据查询文本构建查询对象,对其进行分析,然后将执行的查询结果作为TopDocs返回。
用户以文本格式指定查询。 根据查询文本构建查询对象,对其进行分析,然后将执行的查询结果作为TopDocs返回。
查询是搜索的主要输入。
| 术语查询 | |
| 布尔查询 | 是否(合并多个查询) |
| 前缀查询 | 以。。开始 |
| 通配符查询 | ? 和* – *开头不允许 |
| 词组查询 | 精确短语 |
| 范围查询 | 术语范围或数字范围 |
| 模糊查询 | 相似词搜索 |
样本查询
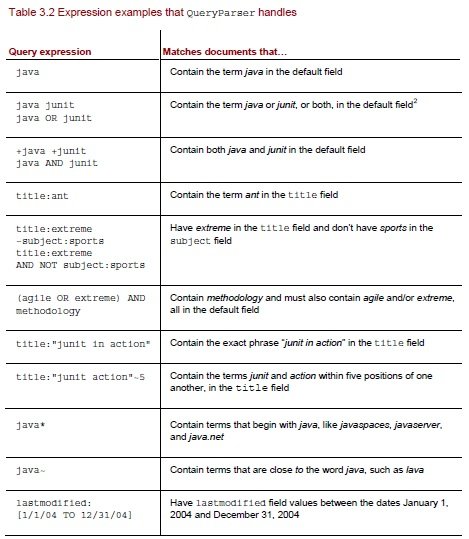
搜索示例:
IndexSearcher searcher = new IndexSearcher(indexDirectory);
Term term = new Term('id', '1');
Query query = new TermQuery(term);
TopDocs docs = searcher.search(query, 3);
for (int i = 1; i <= docs.totalHits; i++)
{
System.out.println(searcher.doc(i));
}Lucene诊断工具:
- 卢克– http://code.google.com/p/luke/
Luke是一个方便的开发和诊断工具,它可以访问现有的Lucene索引,并允许您以几种方式显示和修改其内容: - 豪华轿车– http://limo.sourceforge.net/
这个想法是要有一个小的工具作为Web应用程序运行,它提供有关Lucene搜索引擎使用的索引的基本信息。
完整的例子:
在这里下载: LuceneTester.java
资源资源
- http://lucene.apache.org/core/
- http://www.amazon.com/Lucene-Action-Second-Edition-Covers/dp/1933988177/ref=dp_ob_title_bk
参考: Lucene –在Techie博客的Thoughts中,从我们的JCG合作伙伴 Srividhya Umashanker 快速添加了索引和搜索功能 。
翻译自: https://www.javacodegeeks.com/2012/12/lucene-quickly-add-index-and-search-capability.html
lucene索引搜索















 616
616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









