









摘要:
生成式对抗网络(GAN, Generative Adversarial Networks )是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。模型通过框架中(至少)两个模块:生成模型(Generative Model)和判别模型(Discriminative Model)的互相博弈学习产生相当好的输出。我们利用GAN网络对图片进行处理,在保有原始输入图片的整体特征的情况下,将其图像风格转换为另一种图像,实现图像的风格迁移。
1. 背景介绍
在艺术绘画的创作过程中,人们通过将一张图片的内容和风格构成复杂的相互作用来产生独特的视觉体验。然而,所谓的艺术风格是一种抽象的难以定义的概念。因此,如何将一个图像的风格转换成另一个图像的风格更是一个复杂抽象的问题。尤其是对于机器程序而言,解决一个定义模糊不清的问题是几乎不可行的。
在神经网络之前,图像风格迁移的程序采用的思路是:分析一种风格的图像,为这种风格建立一个数学统计模型;再改变要做迁移的图像使它的风格符合建立的模型。该种方法可以取得不同的效果,但是有一个较大的缺陷:一个模型只能够实现一种图像风格的迁移。因此,基于传统方法的风格迁移的模型应用十分有限。
随着神经网络的发展,机器在某些视觉感知的关键领域,比如物体和人脸识别等有着接近于人类甚至超越人类的的表现。这里我们要介绍一种基于深度神经网络的机器学习模型——卷积神经网络,它可以分离并结合任意图片的风格和内容,生成具有高感知品质的艺术图片。本文介绍一篇在2015年由 Gatys 等人发表的一篇文章 A Neural Algorithm of Artistic Style,该文章介绍了一种利用卷积神经网络进行图像风格迁移的算法。相比于传统的风格迁移的方法,该方法具有更好的普适性。
2. 概述
2.1 内容表示
处理图像任务最有效的一种深度神经网络就是卷积神经网络。卷积神经网络由多个网络层组成的前馈神经网络,每个网络层包含了许多用于处理视觉信息的计算单元(神经元)。每一层的计算单元可以被理解为一个图片过滤器的集合,每一层都可以提取图片的不同的特定特征。我们把给定层的输出称为特征图谱(Feature Map)——输入图像的不同过滤版本。
当卷积神经网络用于物体识别时,随着网络的层次越来越深,网络层产生的物体特征信息越来越清晰。这意味着,沿着网络的层级结构,每一个网络层的输出越来越关注于输入图片的实际内容而不是它具体的像素值。通过重构每个网络层的特征图谱,我们我可以可视化每一层所表达的关于输入图片的信息。从中可以看出,位于更高层的网络层能够根据物体及其在输入图像中的排列来捕获输入图像的高级内容而不包含具体的像素值信息。因此,我们参考网络模型的高层结构作为图片的内容表示。
2.2 风格表示
为了获取输入图片的风格表示,我们使用一个被用来获取纹理特征的特征空间。该特征空间包含了特征图谱空间范围内不同滤波器响应之间的相关性。通过多个层的特征相关性,我们获得输入图像的静态多尺度表示,它能够捕获图片的纹理信息却不包含全局排列。
2.3 内容和风格的分离
本文的一个关键点是图片的内容表示和风格表示在卷积神经网络中是可分离的。也就是说,我们可以独立地操纵这两种表示来产生新的有感知意义上的图片。为了证明这一观点,该论文展示了一些由不同内容和风格的图片混合生成的合成图片。
这些图片是通过寻找一个同时匹配照片内容和对应的艺术风格的图片的方法而生成的。这些合成图片在保留原始照片的全局布置的同时,继承了各种艺术图片的不同艺术风格。风格表示是一个多层次的表达,包括了神经网络结构的多个层次。当风格表示只包含了少量的低层结构,风格的就变得更加局部化,产生不同的视觉效果。当风格表示由网络的高层结构表示时,图像的结构会在更大的范围内和这种风格匹配,产生更加流畅持续的视觉体验。
四、图像生成
数据预处理:把原来的像素先缩小到2/255然后减去1,随机产生(batch_size, 1, 1, 1)维度的数组,其值为0到1之间,对前面产生的像素,进行复制,复制之后的维度为[batch_size, 3, 1024, 1024],小于0.5的返回原值,否则返回对第三维进行翻转之后的值(经过一位小伙伴的提醒,进行了修改),把每张(1024, 1024)的图片图片分割成4快区域,每块区域为512*512个像素,每个区域都用他们的平均像素代替,lod越大,则越接近原图,其主要目的就是把原图损失的像素值补回来,当lod围殴10,即2的10次方插值,此时和原图一样。
G_mapping:其主要就是经过八个全连接操作,然后通过dlatent_broadcast进行广播,得到[?, 18, 512]的矩阵,后面与G_synthesis网络搭配使用。
G_synthesis:其网络首先是定义了第一层,然后根据structure参数,对网络结构进行选择,我们的网络使用的是structure == ‘linear’,其实反射变换A就是一个全连接层,这样就能通过网络迭代,学习到自己层相关的权重参数,其实现是在style_mod函数中。
Discriminator网络:输入图片,然后通过一系列的卷积激活,全连接操作,然后得到一个值,这个值就是对应图片图片是否为真是图片的概率值。
loss损失函数:G_logistic_nonsaturating计算的损失,都是生成图片的损失,因为它的目的十分的单纯,就是为了生成逼真的图片,所以只需要对生成的图片进行损失计算即可。但是对于判别网络,它的目的是在于鉴别图片的真假,它不仅要判断出造假的图片,还要判断出真实的图片。无论是造假还是真实他都要进行损失计算。
最后进行图片生成和融合。
备注
简介此部分摘自互联网,仅供参考,若侵权,联系删除
程序代码:

功能效果:
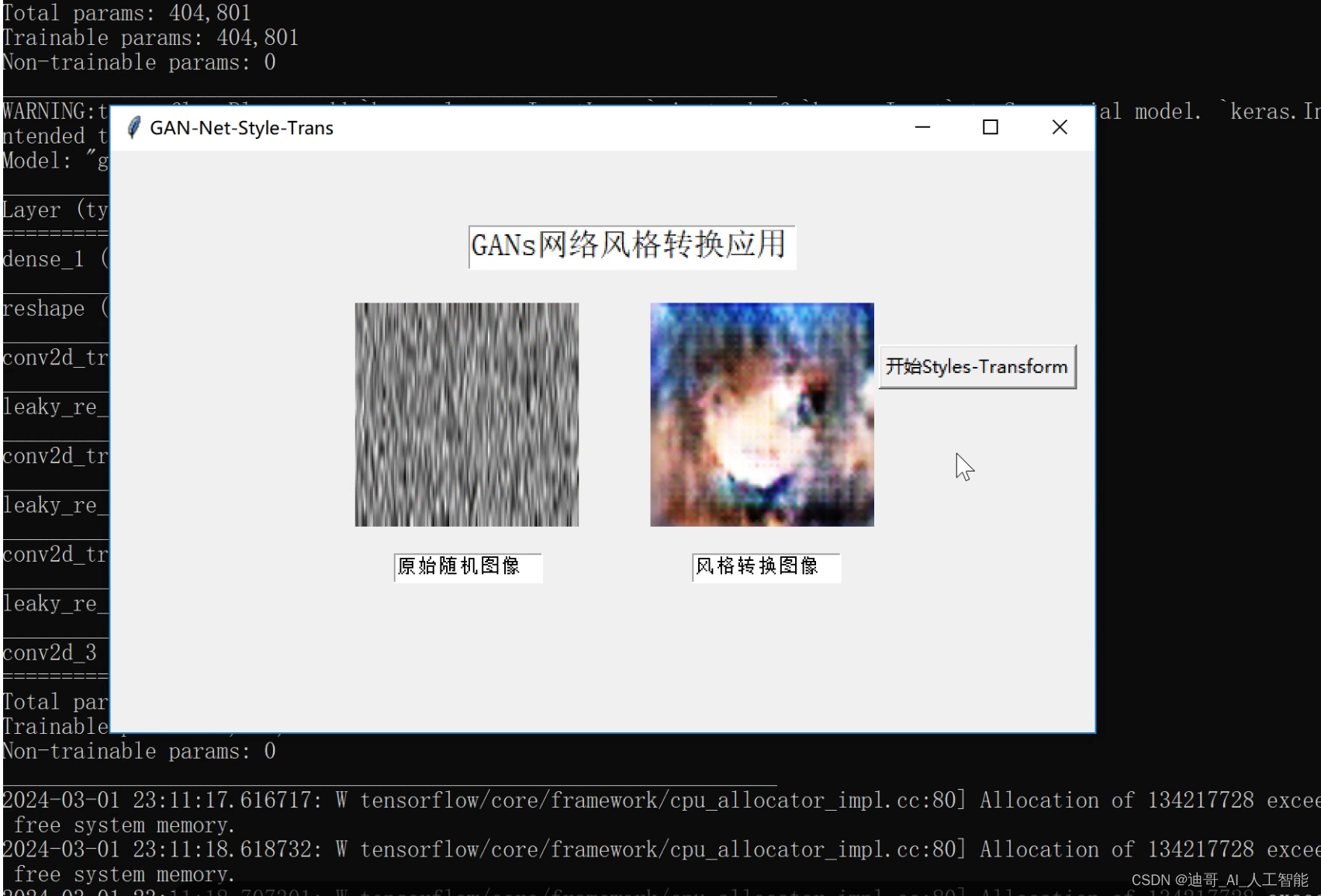
创作不易,相关程序,说明文档需求,如需要,可加作者新联系方式,WX:Q3101759565,QQ:3101759565[多加几次!!!]

祝您学业有成!工作顺利! 年薪百万!
















 673
673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











