







spark on yarn搭建
一、hadoop集群搭建
1. 解压
如未指出,以下用户均以hadoop用户运行命令
cd /data/soft
tar –xvzf hadoop-2.6.5.tar.gz –C /bigdata
mv hadoop-2.6.5 hadoop2. 修改配置 hadoop-env.sh文件
cd /bigdata/hadoop/etc/hadoop
vim hadoop-env.sh修改:
export JAVA_HOME=${JAVA_HOME}为:
export JAVA_HOME=/bigdata/jdk保存退出。
3. 修改配置文件core-site.xml
vim core-site.xml添加如下:
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata1:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/hadoop/storage/tmp/${user.name}</value>
</property>4. 修改hdfs-site.xml文件
vim hdfs-site.xml添加内容如下:
<property>
<name>dfs.namenode.name.dir</name>
<value>/bigdata/hadoop/storage/name/${user.name},/data/dfs-storage/name/${user.name}</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/bigdata/hadoop/storage/data/${user.name}</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>bigdata1:50090</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>bigdata1:50070</value>
</property>如果你的服务器挂载了两块硬盘可以设置两个路径,以逗号隔开,这样namenode的数据将保存两份,如果其中一份硬盘坏了,便可使用备份的数据进行恢复。
5. 修改mapred-site.xml 文件
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml修改内容如下:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>6. 修改yarn-site.xml文件
vim yarn-site.xml添加内容如下:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>7. 修改salves文件
vim salves添加内容如下:
bigdata2
bigdata3
bigdata48. 修改日志存储路径
vim $HADOOP_HOME/etc/hadoop修改HADOOP_LOG_DIR为:
export HADOOP_LOG_DIR=/data/logs/hadoop9. 复制节点
将hadoop-2.6.5文件夹复制到bigdata2、bigdata3、bigdata4节点中去
cd /bigdata
scp –r hadoop hadoop@bigdata2:$PWD
scp –r hadoop hadoop@bigdata3:$PWD
scp –r hadoop hadoop@bigdata4:$PWD10. 设置环境变量
在bigdata1服务器执行如下命令:
sudo vim /etc/profile添加如下内容:
export HADOOP_HOME=/bigdata/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin11. 格式化namenode
hadoop namenode -format12. 验证
1)、验证hdfs
在bigdata1启动hdfs,输入命令:
start-dfs.sh然后输入:
jps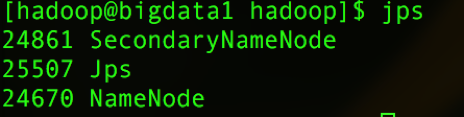
在bigdata2、bigdata3、bigdata4输入命令:
jps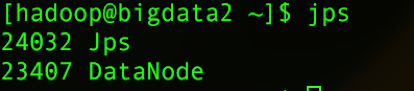
测试文件上传:
cd ~
vim test输入一些单词,以空格隔开。保存上传至hdfs中。
hadoop fs –put test /
hadoop fs –ls /
2)、验证yarn
在bigdata1启动yarn,使用命令:
start-yarn.sh出入jps命令查看进程:
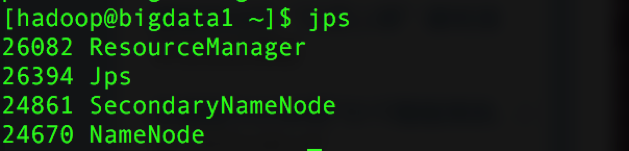
在bigdata2、bigdata3、bigdata4输入jps命令可查看到:

3)、mapreduce测试
cd $HADOOP_HOME
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount /test /testout
二、scala安装
1. 版本说明
由于livy仅支持scala2.10版本编译的spark,所以scala版本选择为scala2.10.6。
2. 解压
cd /date/soft
tar -xvf scala-2.10.6.tgz -C /bigdata
mv scala-2.10.6 scala3. 配置环境变量
sudo vim /etc/profile文件末尾添加:
export SCALA_HOME=/bigdata/scala
export PATH=$PATH:$SCALA_HOME/bin保存退出。
4. 验证
source /etc/profile
scala
三、 安装Apache-Maven
1. 解压maven
cd /data/soft
tar -xvzf apache-maven-3.3.9-bin.tar.gz -C /bigdata
mv apache-maven-3.3.9 maven2. 设置环境变量
sudo vim /etc/profile在文件末尾添加:
export MAVEN_HOME=/bigdata/maven
export PATH=$PATH:$MAVEN_HOME/bin保存退出。
3. 验证
source /etc/profile
mvn –version显示如下内容:
Apache Maven 3.3.9 (bb52d8502b132ec0a5a3f4c09453c07478323dc5; 2015-11-11T00:41:47+08:00)
Maven home: /bigdata/maven
Java version: 1.7.0_79, vendor: Oracle Corporation
Java home: /bigdata/jdk/jre
Default locale: en_US, platform encoding: UTF-8
OS name: “linux”, version: “3.10.0-327.el7.x86_64”, arch: “amd64”, family: “unix”
四、 spark on yarn编译安装
1. 编译说明
livy目前版本只支持scala2.10编译的spark版本,且spark2.0以后仅提供基于scala2.11的预编译版本,所以需基于scala2.10手动编译spark2.0.1,所以采用可联通外网的linux服务器进行编译spark,不过目前github主干上的livy已经支持scala2.11编译的spark了。
2. 环境准备
maven3.3.9
jdk1.7+
3. 解压spark
上传至本地可联网服务器/home/hadoop目录解压:
cd /data/soft
tar -xvzf spark-2.0.1.tgz -C /bigdata
mv /bigdata/spark-2.0.1 /bigdata/spark4. 编译
1)、设置maven编译内存:
export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m -XX:MaxPermSize=512M"注:如果不设置编译过程导致内存溢出。
2)、设置编译scala的版本
cd /bigdata/spark
./dev/change-version-to-2.10.sh注:该命令将所有pom.xml文件的中scala版本依赖改成2.10版本,相应的也有change-version-to-2.11.sh的文件,该文件将所有的scala依赖更改为2.11版本。如果编译前不执行该命令,编译出错,错误如下:
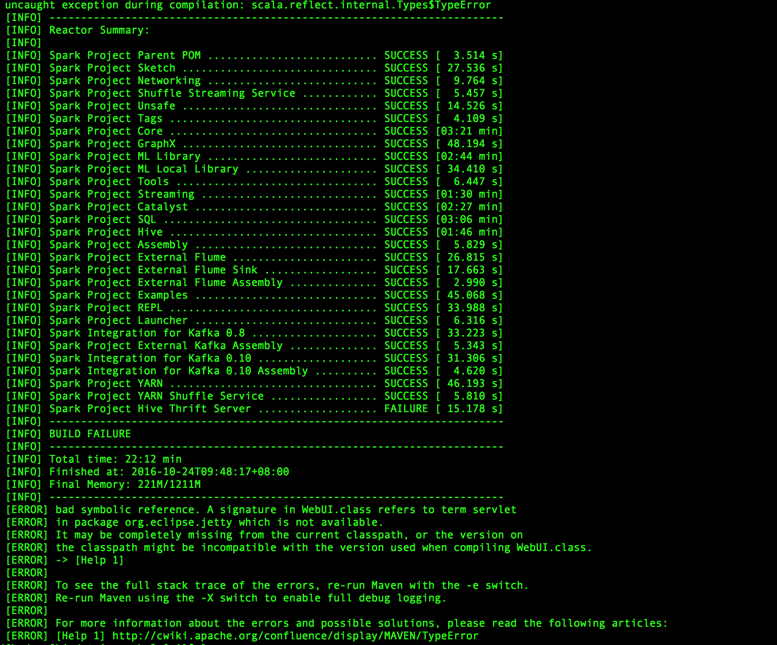
3)、设置json4s的jar包版本
cd /bigdata/spark
vim pom.xml搜索:/json4s
修改前:

修改后:

注:
当spark整合livy的时候,如果不修改json4s的版本的话,由于使用默认的版本为3.2.11,导致整合失败,因此在编译过程中需要更改该jar包的版本号为3.2.10。如果使用3.2.11版本,livy整合spark错误信息如下:

4)、编译:
编译有两种方式。
方式一:
cd /bigdata/spark
mvn -Psparkr -Pyarn -Phadoop-2.6 -Dhadoop.version=2.6.5 -Phive -Phive-thriftserver -Dscala-2.10 -DskipTests clean package直接在spark目录下进行编译,这样导致的编译后的文件和源码全都在同一个包内,且编译后的jar包全部存放在各个子项目的target文件夹下,不推荐使用。
方式二:
执行spark自带的编译脚本
cd /bigdata/spark
./dev/make-distribution.sh --name custom-spark --tgz -Psparkr -Pyarn -Phadoop-2.6 -Dhadoop.version=2.6.5 -Phive -Phive-thriftserver -Dscala-2.10 -DskipTests编译结果将在编译目录下生成可分布部署的压缩包:
spark-2.0.1-bin-custom-spark.tgz
建议使用方式二进行编译。
编译参数说明:
| 编译参数 | 参数说明 |
|---|---|
| -Psparkr: | 支持sparkR |
| -Pyarn: | 支持yarn |
| -Phadoop-2.6 | 支持hadoop版本 |
| -Phadoop.version=2.6.5 | 支持hadoop的具体版本 |
| -Phive | 支持hive |
| -Phive-thriftserver | 支持thriftserver发布sparksql server |
| -Dscala-2.10 | 基于scala编译版本 |
| -DskipTests | 编译过程忽略测试类 |
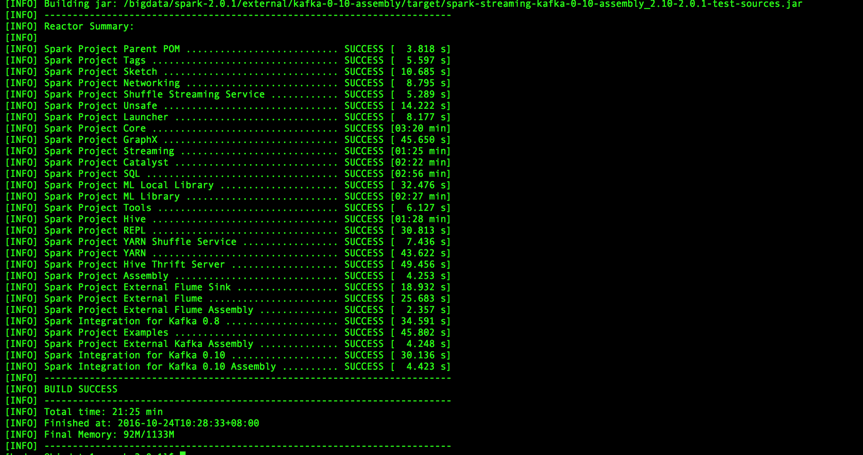
至此spark编译成功。
注:编译过程常常因为网络原因导致编译失败,只要重新运行编译代码即可,耐心等待,总会成功。
5. 无法联网环境编译spark
可以在联网的环境下编译成功spark,如果采用方式二编译的spark,可以将该分布式部署包上传到不可联网的环境下进行部署。如果为了追求最佳性能,希望能在无法联网的环境下也编译成功spark,可以进行如下操作:
1)、将编译成功spark的linux环境下的maven本地仓库打包
vim $MAVEN_HOME/conf/settings.xml查看本地仓库的位置。此处的设置为:/home/hadoop/.m2/repository
cd /home/hadoop/.m2/repository
tar –xvcf repository.spark.tar.gz repository2)、上传至不可联网的集群服务器
a、如果本地服务器能够联通集群服务器,直接使用如下命令:
scp repository.spark.tar.gz 用户名@主机名或ip:存放路径b、如果无法联通,可以借助secureCRT工具,从本地linux环境将相应的软件包下载至可联通集群服务器器bigdata1的系统环境中,然后借助secureCRT工具上传至集群服务器。
c、如果未安装secureCRT工具,可以使用ftp服务器进行进行拉取。首先在本地linux服务器安装ftpd服务,具体安装步骤请自行查阅资料。
本次使用方法a直接上传至集群服务器。
3)、覆盖maven仓库
查看集群maven仓库
vim $MAVEN_HOME/conf/settings.xml未设置,未默认存储路径: $HOME/.m2/repository
将上传的到集群服务器的repository.tar.gz解压到该目录并覆盖repository:
cd $HOME/.m2
tar -xvzf /data/soft/repository.spark.tar.gz –C .
find ~/.m2/repository -name _remote.repositories |xargs rm –rf注:如果不执行find ~/.m2/repository -name _remote.repositories |xargs rm –rf该命令直接进行编译,maven依旧会从远程服务器更新版本,而无法编译。主要是因为maven的repository中的每个jar包所在目录都会存在一个这样的文件:_maven.repositories。这个文件存放着原始repository的相关信息,由于移动了repository仓库,编译过程中,maven发现原始记录的repository信息与实际不一致,便会试着去更新相关的pom文件。
因此执行该命令,删除所有的_maven.repositories文件,便可阻止maven更新。
4)、集群编译
cd /bigdata/
tar -xvf /date/soft/spark-2.0.1.tar -C .
mv spark-2.0.1 spark
cd spark编译前的设置参照前文设置。
执行mvn命令进行编译。使用./dev/make-distribution.sh该脚本编译始终要下载些文件,导致无法编译,可能还需要拷贝maven的什么设置才行,具体没有研究。
mvn -Psparkr -Pyarn -Phadoop-2.6 -Dhadoop.version=2.6.5 -Phive -Phive-thriftserver -Dscala-2.10 -DskipTests clean package6. 配置spark-env.conf
cd /bigdata/spark/conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh文件末尾添加如下内容:
export JAVA_HOME=/bigdata/jdk
export SCALA_HOME=/bigdata/scala
export HADOOP_HOME=/bigdata/hadoop如果/etc/profile设置了也可以跳过此步骤
7. 修改日志存储路径
vim spark-env.sh添加以下内容:
export SPARK_LOG_DIR=/data/logs/spark8. 配置/etc/profile
sudo vim /etc/profile文件末尾添加以下内容:
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
export SPARK_HOME=/bigdata/spark保存退出。
9. 验证
source /etc/profile
cd /bigdata/spark运行Pi测试:
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster\
--driver-memory 2g \
--executor-memory 3g \
--executor-cores 3 \
examples/jars/spark-examples_2.10-2.0.1.jar \
10
主节点进程:

子节点进程:
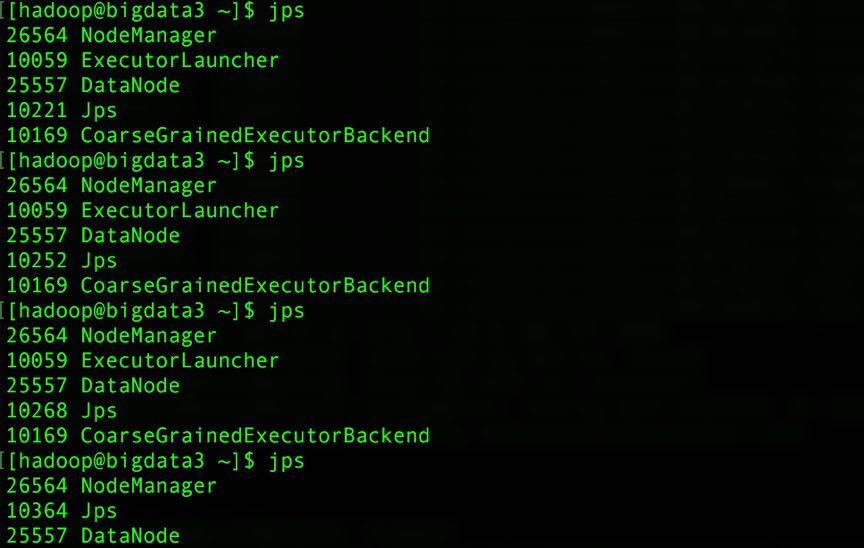
子节点会出现ApplicationMaster、ExecutorLauncher、CoarseGraineExecutorBackend相关进程,ApplicationMaster就相当于driver端了,一个sparkContext在集群中对应生成一个ApplicationMaster。随着任务结束,进程最终消失。
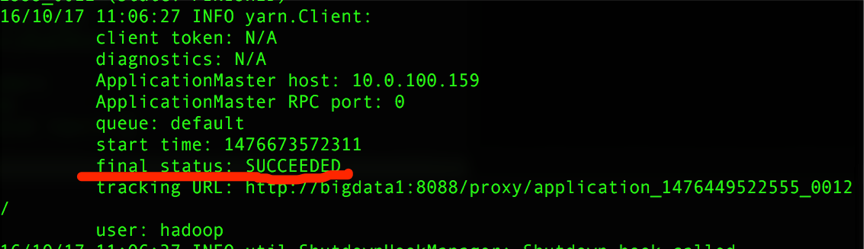
输出结果:
./bin/spark-submit –class org.apache.spark.examples.SparkPi \
–master yarn \
–deploy-mode client \
–driver-memory 2g \
–executor-memory 3g \
–executor-cores 3 \
examples/jars/spark-examples_2.10-2.0.1.jar \
10
client模式,那spark-submit就相当于driver端了,结果可以直接在控制台看到。输出结果:
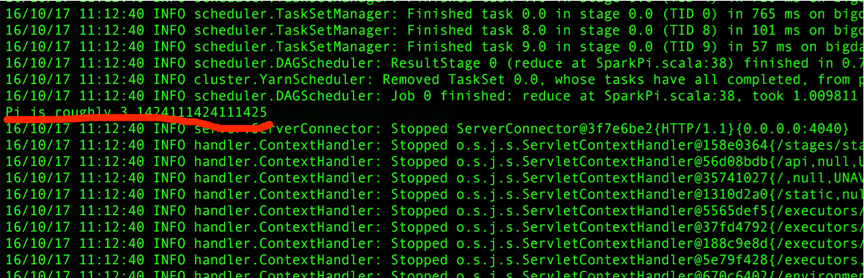
限水平有限,哪里说的不对,欢迎拍砖,相互学习,相互进步















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









