







hue+hive+sparksql
1、 配置hue
cd /bigdata/hue/desktop/conf
vim /hue.ini配置hive与hue整合,找到[beeswax]修改内容如下:
[beeswax]
# Host where HiveServer2 is running.
# If Kerberos security is enabled, use fully-qualified domain name (FQDN).
hive_server_host=bigdata1
# Port where HiveServer2 Thrift server runs on.
hive_server_port=10000
# Hive configuration directory, where hive-site.xml is located
hive_conf_dir=/bigdata/hive/conf
# Timeout in seconds for thrift calls to Hive service
server_conn_timeout=120注:hive_server_host=bigdata1 #指向运行hue的主机
hive_server_port=10000 #端口号
hive_conf_dir=/bigdata/hive/conf #执行hive配置文件的路径
2、启动hue
/bigdata/hue/build/env/bin/supervisor3、启动hive的matestore服务
hive --service metastore4、 启动sparkSql Server
cd /bigdata/spark/sbin
./start-thriftserver.sh --master yarn --deploy-mode client使用以下命令查看是否启动成功(注:启动过程比较长,需要等待数秒才能查看到结果):
netstat -nltp | grep 10000

启动sparkSql server是为了支持sql查询,否则点击install spark出现以下错误。
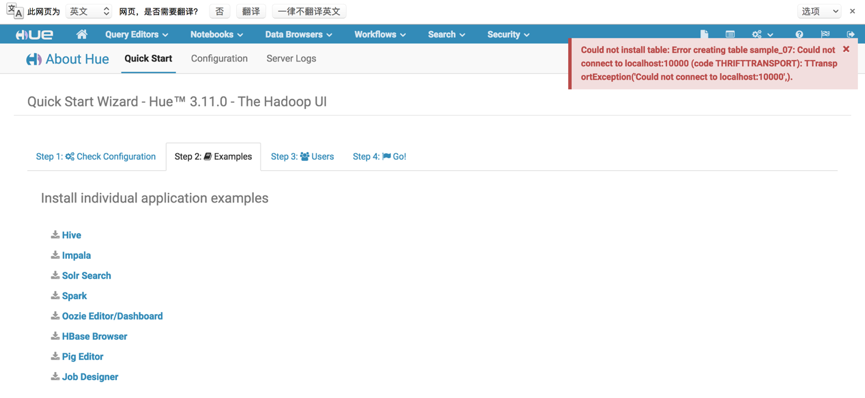
当开启sparkSql Server服务时,点击install spark会向default数据库中插入四张表。
5、测试sparksql
1)、打开notebook
如果notebook打不开,首先查询后台日志,查看是否报错,如果确定没有报错。则可能是前台原因导致,首先排查浏览器是否兼容,可更换不同浏览器进行测试。如果网速过慢也可能导致notebook无法正常打开,此时可以打开开发者工具查看是否有js脚本或其他什么资源加载超时的,刚搭建好的时候就出现网速过慢足足加载了1分多钟还未加载完成,导致部分js加载超时,无法正常显示,如果是网速原因,多刷新下网页就出来了。
2)、左侧导航栏测试
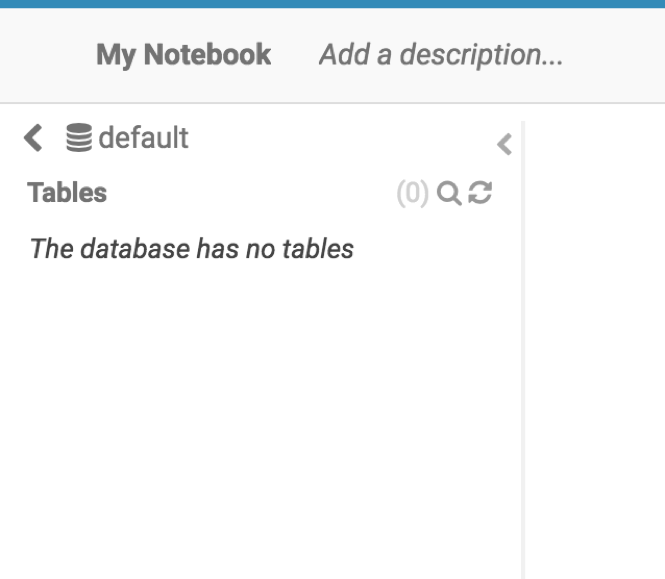
左侧侧边栏无法加载数据库和数据库中的表,查看后台日志。
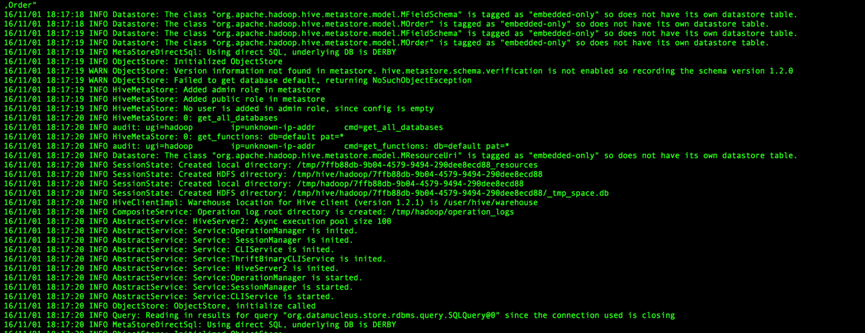
16/11/01 18:17:20 INFO Query: Reading in results for query “org.datanucleus.store.rdbms.query.SQLQuery@0” since the connection used is closing
16/11/01 18:17:20 INFO MetaStoreDirectSql: Using direct SQL, underlying DB is DERBY
这两句表示使用derby数据库。主要因为thriftserver运行时,客户端访问直接访问derby数据库,所以只看到一个default数据库,且并未显示那4张表,而不是直接访问mysql中的matestore数据库中的数据。
该问题可能是spark存在的一个bug未解决,具体查看如下:
具体查看:https://issues.apache.org/jira/browse/SPARK-9686
解决方案:
使用hiveserver2代替spark的thriftserver。
3)、使用hive的hvieserver2代替thriftserver
停止thriftserver
$SPARK_HOME/sbin/stop-thriftserver.sh启动hiveserver2
hive --service hiveserver2
4)、创建数据库
网址:http://blog.cloudera.com/blog/2015/10/how-to-use-hues-notebook-app-with-sql-and-apache-spark-for-analytics/
csv文件下载地址:http://www.bayareabikeshare.com/datachallenge
导航栏找到DataBrowers,打开metastore tables进入metastore manager管理页面。
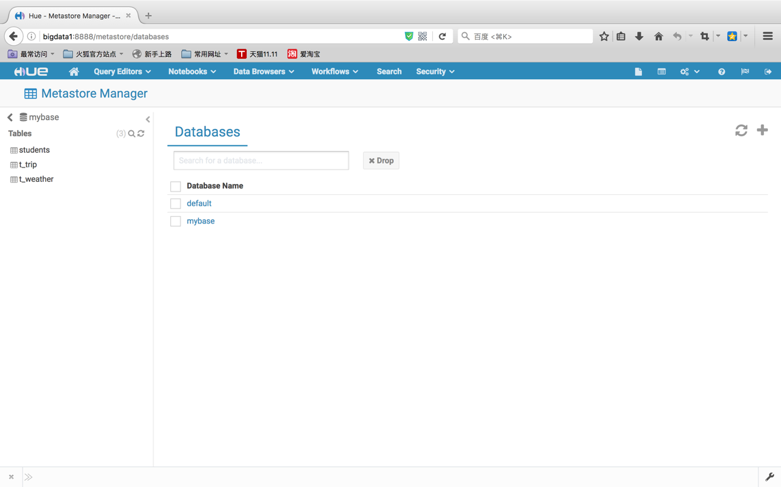
点击右上角的+号按钮,添加数据库。
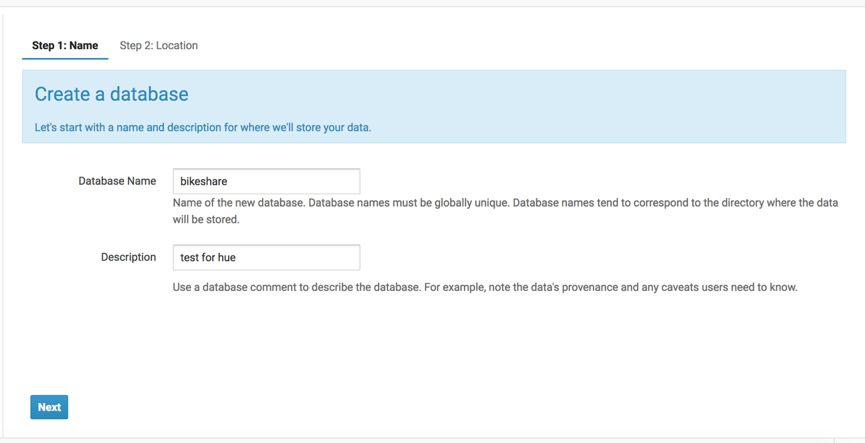
创建数据库:bikeshare
创建成功后,选择bikeshare数据库,为该数据库创建表:
点击右上角的,create table from file,导入trips表。
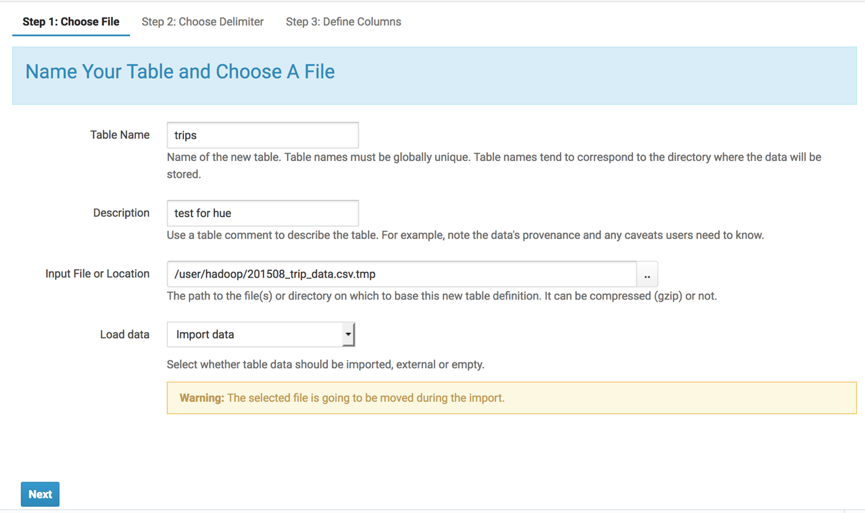
然后next,进入step2,next进入step3,在step3中可以修改字段类型,名称。
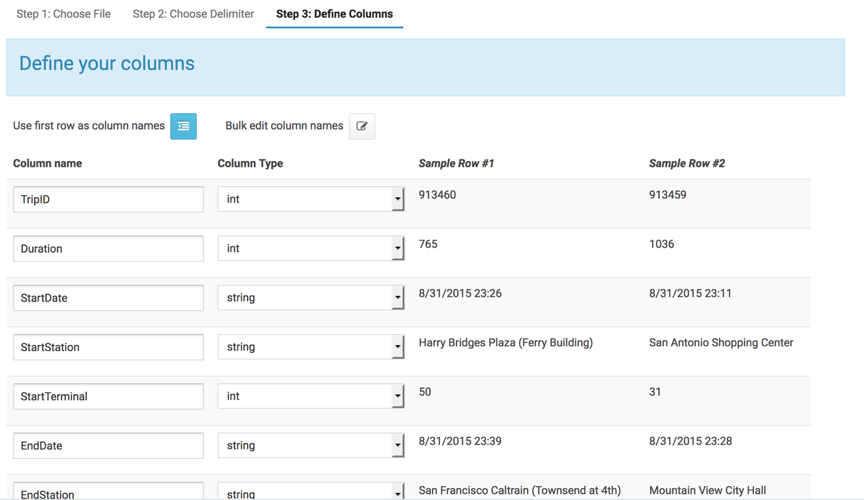
然后点击create table便可以创建成功了。
然后导入stations表。
进入notebook,选择sql选项执行以下sql便可以得到结果。
SELECT startterminal, startstation, COUNT(1) AS count FROM bikeshare.trips GROUP BY startterminal, startstation ORDER BY count DESC LIMIT 10;返回:
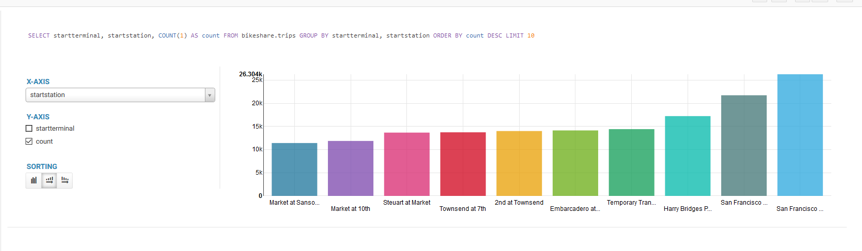
执行:
SELECT
s.station_id,
s.name,
s.lat,
s.long,
COUNT(1) AS count
FROM `bikeshare`.`trips` t
JOIN `bikeshare`.`stations` s ON s.station_id = t.endterminal
WHERE t.startterminal = 70
GROUP BY s.station_id, s.name, s.lat, s.long
ORDER BY count DESC LIMIT 10返回:
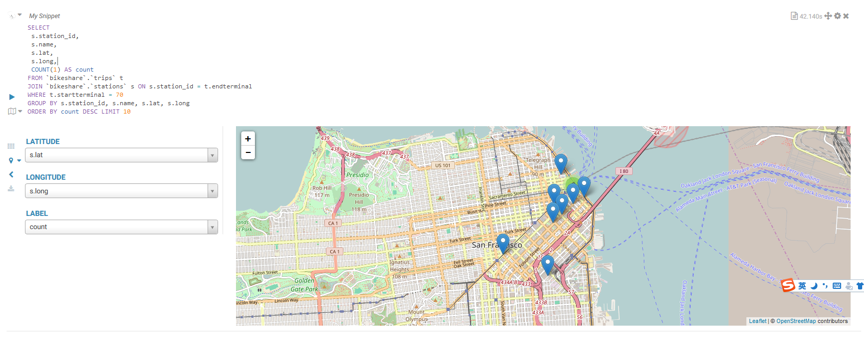
执行:
SELECT
hour,
COUNT(1) AS trips,
ROUND(AVG(duration) / 60) AS avg_duration
FROM (
SELECT
CAST(SPLIT(SPLIT(t.startdate, ' ')[1], ':')[0] AS INT) AS hour,
t.duration AS duration
FROM `bikeshare`.`trips` t
WHERE
t.startterminal = 70
AND
t.duration IS NOT NULL
) r
GROUP BY hour
ORDER BY hour ASC;返回:
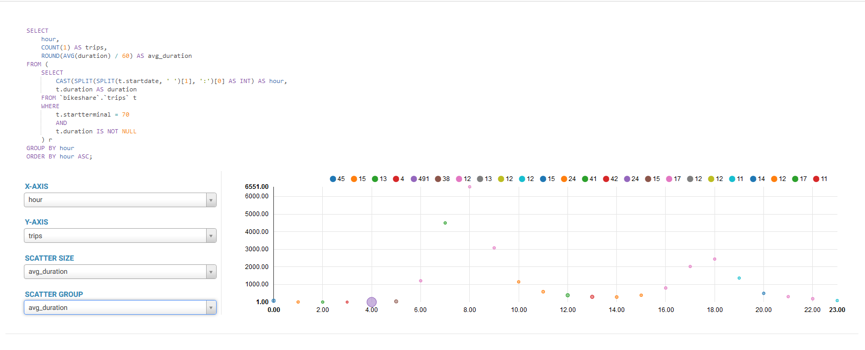
至此hue与hive便整合成功了。但是由于hive是在mapreduce中运行,自然速度是不理想了。虽然,我们不能使用sparksql来获取导航栏数据库、数据库表、已经表字段的数据,那么我们单单执行查询能不能把sparksql整合进来呢,答案是可以的。
6、整合sparksql
1)、配置hue
cd /bigdata/hue/desktop/conf
vim /hue.ini找到[spark]选项进行修改:
[spark]
# Host address of the Livy Server.
#livy_server_host=bigdata1
# Port of the Livy Server.
#livy_server_port=8998
# Configure Livy to start in local 'process' mode, or 'yarn' workers.
#livy_server_session_kind=yarn
# Host of the Sql Server
sql_server_host=bigdata1
# Port of the Sql Server
sql_server_port=10008可以看到,有专门的sparksql配置。
打开sparksql选项:
# One entry for each type of snippet. The first 5 will appear in the wheel.
[[interpreters]]
# Define the name and how to connect and execute the language.
[[[hive]]]
# The name of the snippet.
name=Hive
# The backend connection to use to communicate with the server.
interface=hiveserver2
[[[impala]]]
name=Impala
interface=hiveserver2
[[[sparksql]]]
name=SparkSql
interface=hiveserver2找到[[interpreters]]中的[[[sparksql]]]选项卡,把注释去掉。这样在notebook的选项卡中就能找到sparksql选项了。
配置spark:
vim $SPARK_HOME/conf/hive-site.xml添加如下内容,将thriftserver的端口号更改成10008
<property>
<name>hive.server2.thrift.port</name>
<value>10008</value>
<description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'.</description>
</property>重启hue,已经spark的thriftserver服务。
打开notebook,随意执行一条sql语句,发现不起作用,任务依然通过hive执行,启动的是mapreduce任务。
经过查看hue源码,这里是hue的一个bug。
具体修改如下:
vim $HUE_HOME/desktop/libs/notebook/src/notebook/connectors/hiveserver2.py将该方法:
def _get_db(self, snippet):
if snippet['type'] == 'hive':
name = 'beeswax'
elif snippet['type'] == 'impala':
name = 'impala'
else:
name = 'spark-sql'
return dbms.get(self.user, query_server=get_query_server_config(name=name))中的name = ‘spark-sql’修改成name=’sparksql’。保存退出,重启hue,然后运行sparksql便可以成功了。
不过此处还存在一个问题,第一次启动spark的thriftserver,并执行第一sql查询,会报错,通过日志分析,应该是第一次查询derby数据库,导致没有对应的数据库已经表,后续的查询表成功连接到metastore了。
欢迎拍砖,能力有限,相互学习,相互进步















 2948
2948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









