







hue livy spark整合
1、配置hue
cd /bigdata/hue/desktop/conf
vim /hue.ini找到[spark]选项进行修改:
[spark]
# Host address of the Livy Server.
livy_server_host=bigdata1
# Port of the Livy Server.
livy_server_port=8998
# Configure Livy to start in local 'process' mode, or 'yarn' workers.
livy_server_session_kind=yarn
# Host of the Sql Server
sql_server_host=bigdata1
# Port of the Sql Server
sql_server_port=10008此处不配置也是可以的,将采用默认配置,以上显示内容就是默认配置。
2、启动hue
/bigdata/hue/build/env/bin/supervisor3、启动livy
/bigdata/livy/bin/livy-server启动livy用于编写scala、pyspark、R等语言。
4、spark测试
浏览器选择谷歌或者火狐较好,其他浏览器可能存在不兼容问题。打开页面:
http://bigdata1:8888/
登入后进入quick start页面。该页面未提示spark未配置,表示livy和hue配置成功,启动thriftserver则表示hive已经配置成功了。
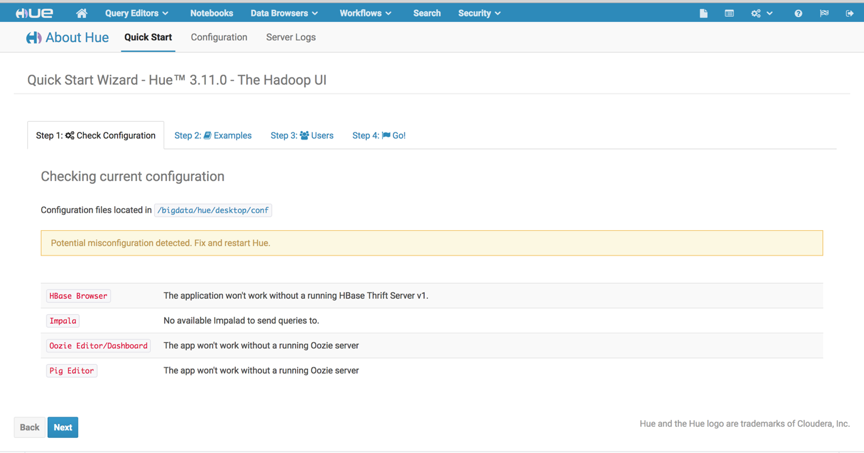
1)、测试scala
打开netobooks
点击+号,选择scala选项,执行以下代码,做一个简单wordcount测试。
sc.textFile("/test").faltMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect; 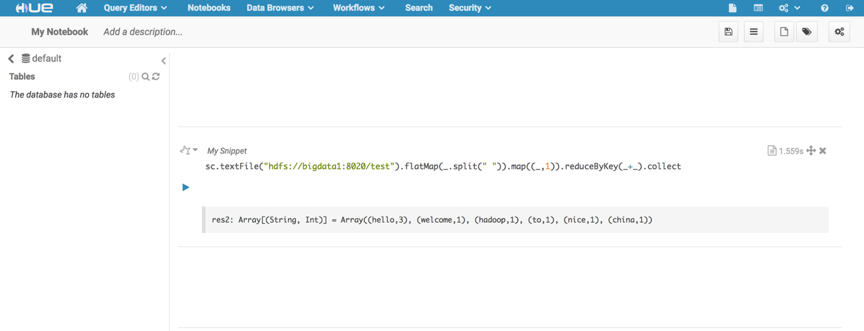
2)、pySpark测试
点击+号,选择pySpark选项,执行以下代码,做一个简单的wordcount测试。
sc.textFile("/test").flatMap(lambda x:x.split(" ")).map(lambda x:(x,1)).reduceByKey(lambda x,y:x+y).collect();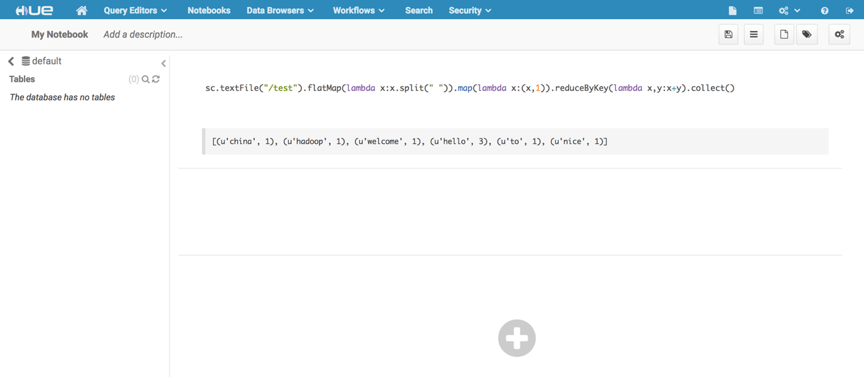
3)、R测试
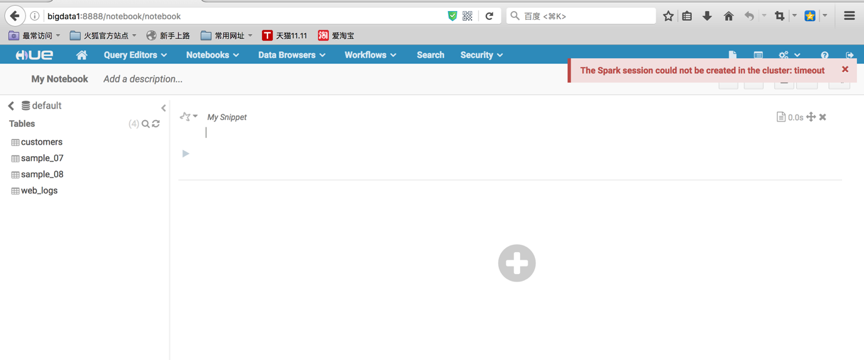
由于sparkR使用yarn-cluster模式运行,所以每个Executor主机必须安装R已经rJava
每个Executor主机安装完成R和rJava后,安装步骤参考前一个章节。
将该路径下的
$SPARK_HOME/examples/src/main/resources/people.jsonpeople.json文件上传至hdfs的根目录中。执行测试代码:
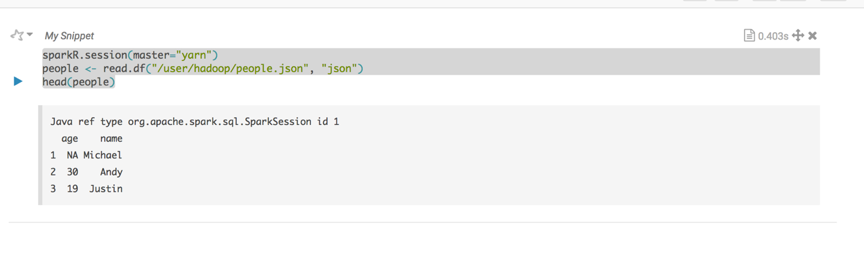
sparkR.session(master="yarn")
people <- read.df("/people.json", "json")
head(people)执行结果:
4)、spark submit jar测试
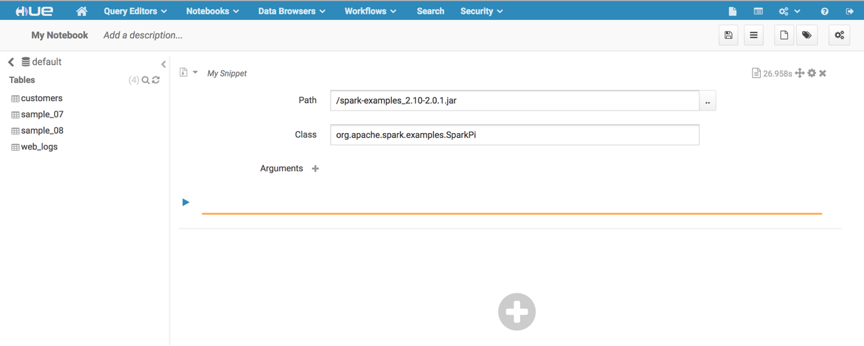
点击+号,选择spark submit jar选项,执行以下代码,做一个简单的pi测试。
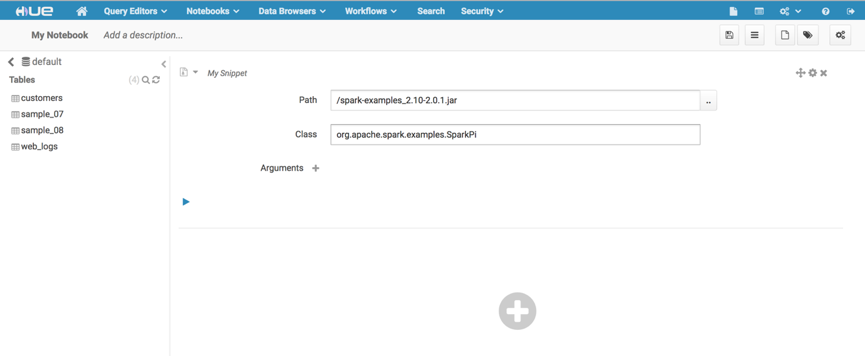
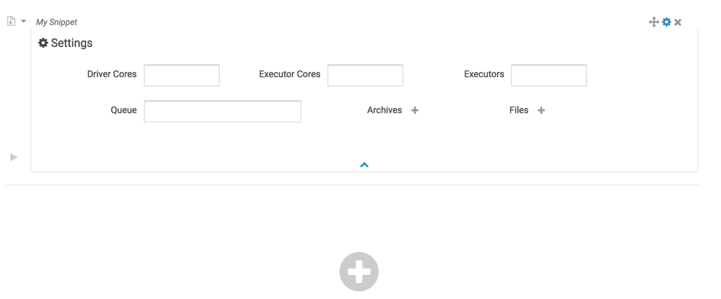
path指定的路径为hdfs中的路径,点击path右侧的按钮,弹出选择框,将jar包上传至hdfs中,并选中hdfs中的jar包,便会自动生成路径。输入calss,如果有入参可以点击添加arguments,点击右上角的齿轮可以设置执行的相关配置:
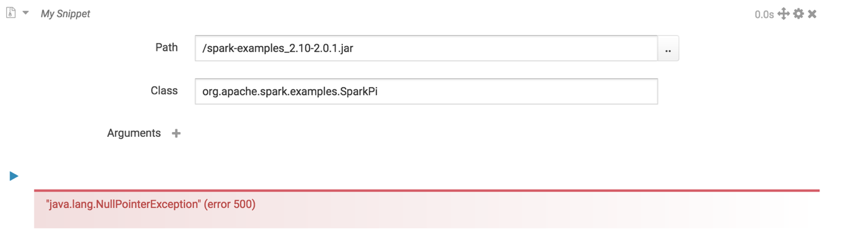
点击运行。
出现异常:
hue日志:
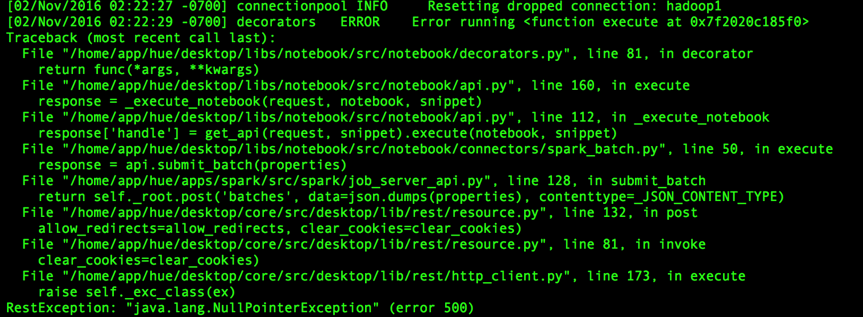
livy日志:
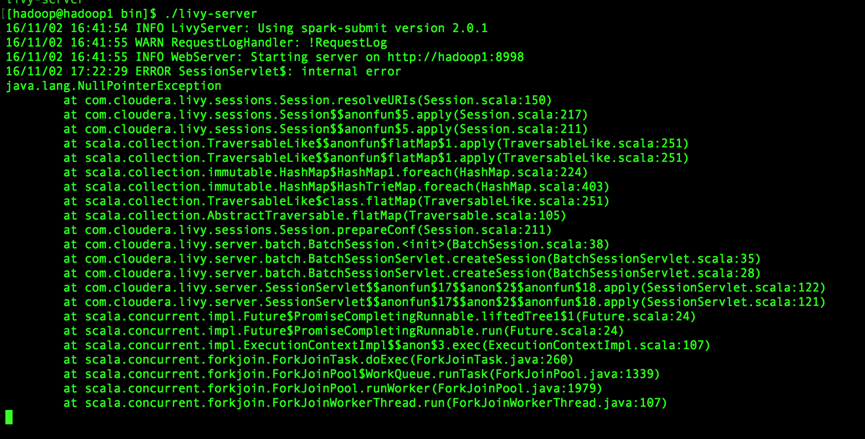
错误排查:
1)、在测试livy-batch提交jar包的时候,livy到spark是可以正常联通。
2)、spark-submit的默认启动模式已经改成了yarn-cluster
3)、且在任务浏览器中并没有该任务的提交记录,所以可以判断hue发送数据到livy,livy进行解析时就报错了。
导致的原因:
hue发送数据到livy不符合restful api规范。通过查询github中的是否有该bug处于open状态,果然有:
地址:
https://github.com/cloudera/hue/pull/441/files
修改该文件内容:
desktop/libs/notebook/src/notebook/connectors/spark_batch.py
def execute(self, notebook, snippet):
api = get_spark_api(self.user)
-
- properties = {
- 'file': snippet['properties'].get('app_jar'),
- 'className': snippet['properties'].get('class'),
- 'args': snippet['properties'].get('arguments'),
- 'pyFiles': snippet['properties'].get('py_file'),
- 'files': snippet['properties'].get('files'),
- # driverMemory
- # driverCores
- # executorMemory
- # executorCores
- # archives
- }
+ if snippet['type'] == 'jar':
+ properties = {
+ 'file': snippet['properties'].get('app_jar'),
+ 'className': snippet['properties'].get('class'),
+ 'args': snippet['properties'].get('arguments'),
+ }
+ elif snippet['type'] == 'py':
+ properties = {
+ 'file': snippet['properties'].get('py_file'),
+ 'args': snippet['properties'].get('arguments'),
+ }
+ else:
+ properties = {
+ 'file': snippet['properties'].get('app_jar'),
+ 'className': snippet['properties'].get('class'),
+ 'args': snippet['properties'].get('arguments'),
+ 'pyFiles': snippet['properties'].get('py_file'),
+ 'files': snippet['properties'].get('files'),
+ # driverMemory
+ # driverCores
+ # executorMemory
+ # executorCores
+ # archives
+ }
response = api.submit_batch(properties)
return {
注:-号表示删除,+号表示添加,修改对应编译好的hue项目对应的文件夹下的文件,保存,重启hue即可。该段代码采用python编写,使用空格缩进,一定要保持一致,很重要,否则无法启动。
然后重新执行任务。
至此便执行成功了。
查看job browers也显示成功了:

但是输入dirvercores、executor等启动配置信息时,无效:
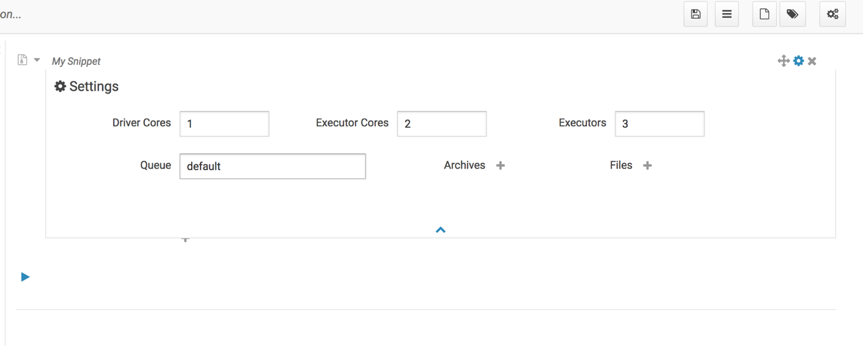
查看livy日志:
16/11/07 11:12:49 INFO SparkProcessBuilder: Running ‘/bigdata/spark/bin/spark-submit’ ‘–name’ ‘Livy’ ‘–class’ ‘com.jmmy.WordCount’ ‘hdfs://bigdata1:8020/original-com.jmmy-1.0-SNAPSHOT.jar’ ‘/wordcount’ ‘/testout’
说明改配置的参数并没有传入到spark-submit中。
经过分析,修改内容如下:
vim $HUE_HOME/desktop/libs/notebook/src/notebook/connectors/spark_batch.py在response = api.submit_batch(properties)之前添加如下代码:
driverCores=snippet['properties'].get('driverCores')
numExecutors=snippet['properties'].get('numExecutors')
executorCores=snippet['properties'].get('executorCores')
queue=snippet['properties'].get('queue')
archives=snippet['properties'].get('archives')
files=snippet['properties'].get('files')
if driverCores!='':
properties['driverCores']=driverCores
if numExecutors!='':
properties['numExecutors']=numExecutors
if executorCores!='':
properties['executorCores']=executorCores
if queue!='':
properties['queue']=queue
if len(archives)>0:
properties['archives']=archives
if len(files)>0:
properties['files']=files最终修改内容如下:
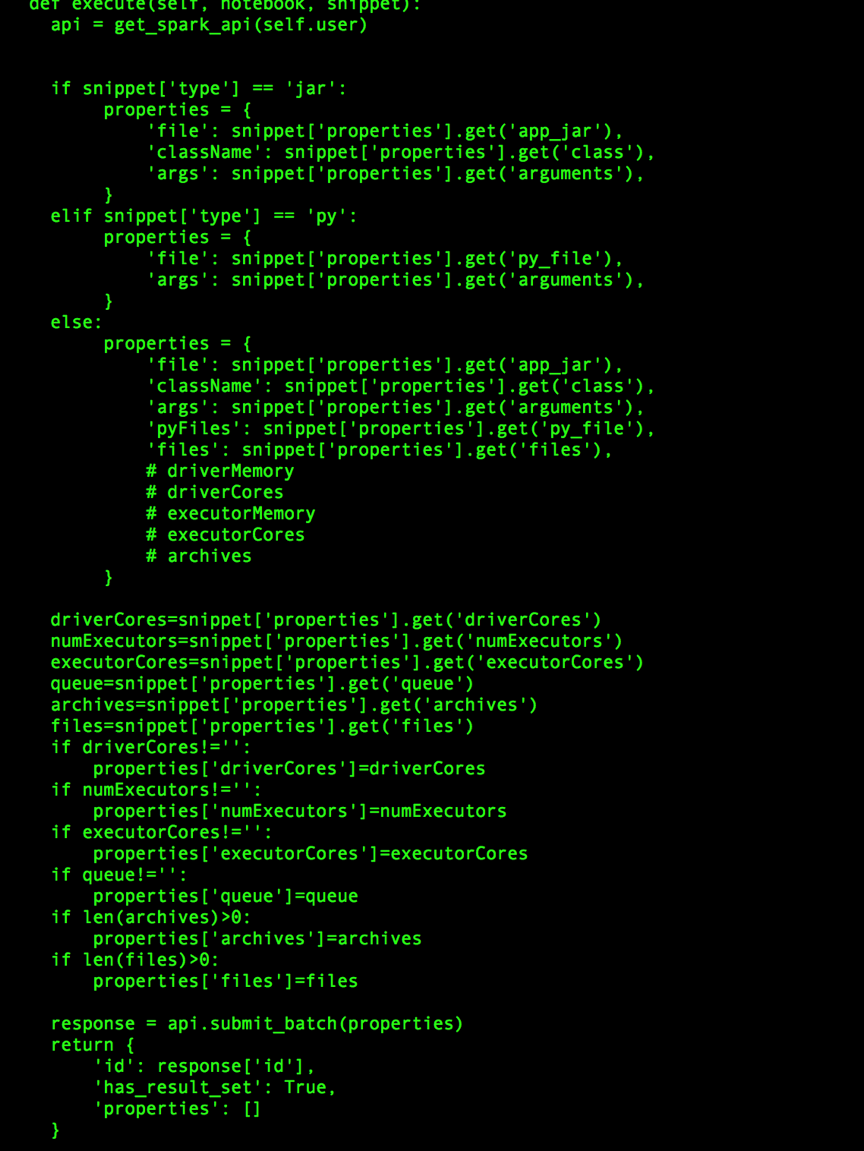
保存,重启hue。运行内容如下:
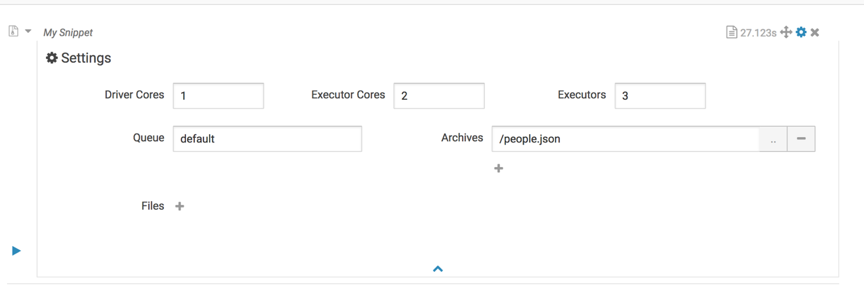
运行livy日志如下:
16/11/07 15:17:28 INFO SparkProcessBuilder: Running ‘/bigdata/spark/bin/spark-submit’ ‘–name’ ‘Livy’ ‘–class’ ‘com.jmmy.WordCount’ ‘–conf’ ‘spark.executor.instances=3’ ‘–conf’ ‘spark.driver.cores=1’ ‘–conf’ ‘spark.yarn.dist.archives=hdfs://bigdata1:8020/people.json’ ‘–conf’ ‘spark.executor.cores=2’ ‘–queue’ ‘default’ ‘hdfs://bigdata1:8020/original-com.jmmy-1.0-SNAPSHOT.jar’ ‘/wordcount’ ‘/testout’
至此,说明参数已经提交到livy了。已经可以成功提交spark submit jar了。
5)、spark submit py测试
点击+号,选择spark submit python选项,执行以下代码,做一个简单的pi测试。
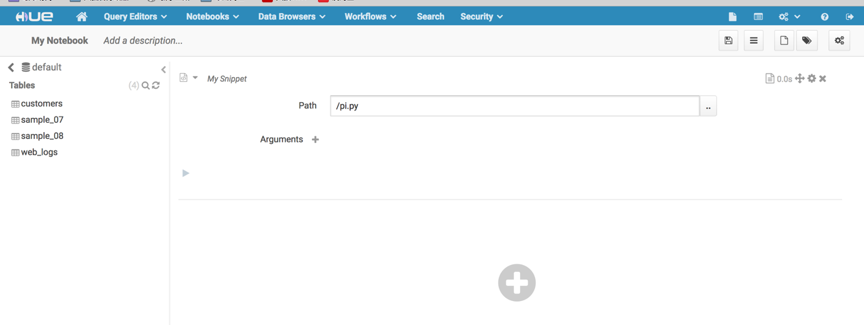
运行按钮不可用。通过spark submit jar可以正常使用进行分析,极有可能是前台代码bug导致,通过分析源码,具体修改内容如下:
cd $HUE_HOME/build/static/notebook/js/notebook.ko.js修改内容如下:
原始内容:

修改内容如下:
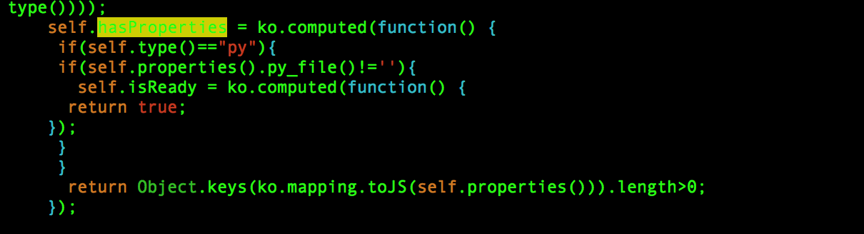
由于前台采用knockout.js以及python的django的web框架mako模版编写,本人甚是不熟,因此按该方法修改,点击提交python的按钮css样式失效,至此还未深入研究解决,但是已经可以正常提交python任务了。
运行结果:

欢迎拍砖,能力有限,相互学习,相互进步















 3367
3367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









