






只要操作点找对了,就只是逼近该点并维持,至于其它的不重要,甚至是错误的。
首先讲,reno/cubic 的操作点在 buffer 用尽 or red aqm 丢包,触发 aimd 动作驱动算法维持在稳定状态,这操作点在拥塞控制意义上没任何问题,但效率却是其美中不足:
- buffer 过小,带宽利用率不足,buffer 过大,时延增加。
其次讲,bbr 的操作点是无可达的,正交量 maxbw 和 rtprop 无法同时测得,存在 gap,该 gap 是不受控区间,bbr 必须定期 probebw,probertt 来重置 gap,确保 inflight 没有成为脱缰野马,因此 bbr 操作点是错误的。
正确的操作点是 E = max(bw / delay),下图一目了然:
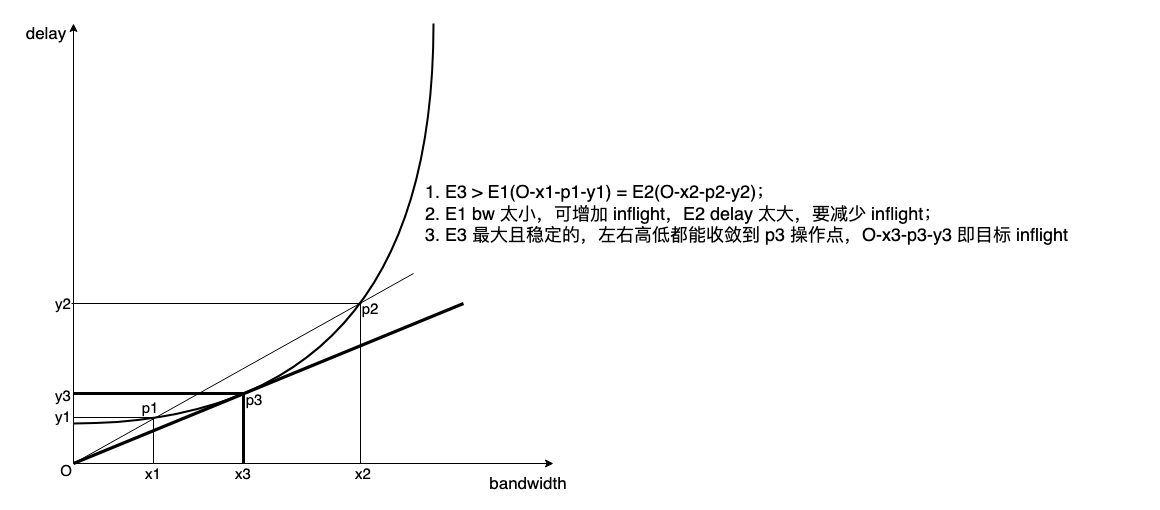
曲线横纵轴相除即斜率,斜率最小即最优,而横纵轴相乘的长方形面积即 bdp,控制 inflight 等于始发自 O 的射线和曲线的切点与 O 构成的长方形面积:
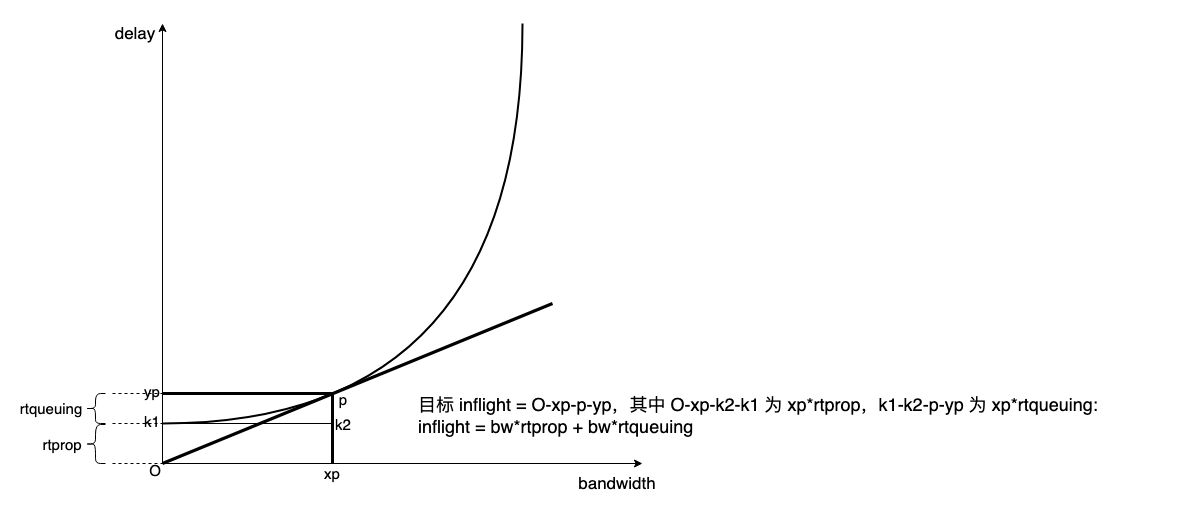
下面是逼近该操作点算法的 3 个版本:
- 版本 1:inflight = xp*(rtprop + rtqueuing),但它无法保证收敛,无法动态适应 bw,但却动态适应了 buffer;
- 版本 2:inflight = xp*rtprop + beta,确保了收敛和动态自适应 bw,但随流数量增多占用 buffer 增多;
- 版本 3:inflight = xp*rtprop + func(…),bw 和 rtqueuing 负反馈 func 确保 buffer 收缩,将 bw-delay 曲线往右下角拉的趋势,如下图:
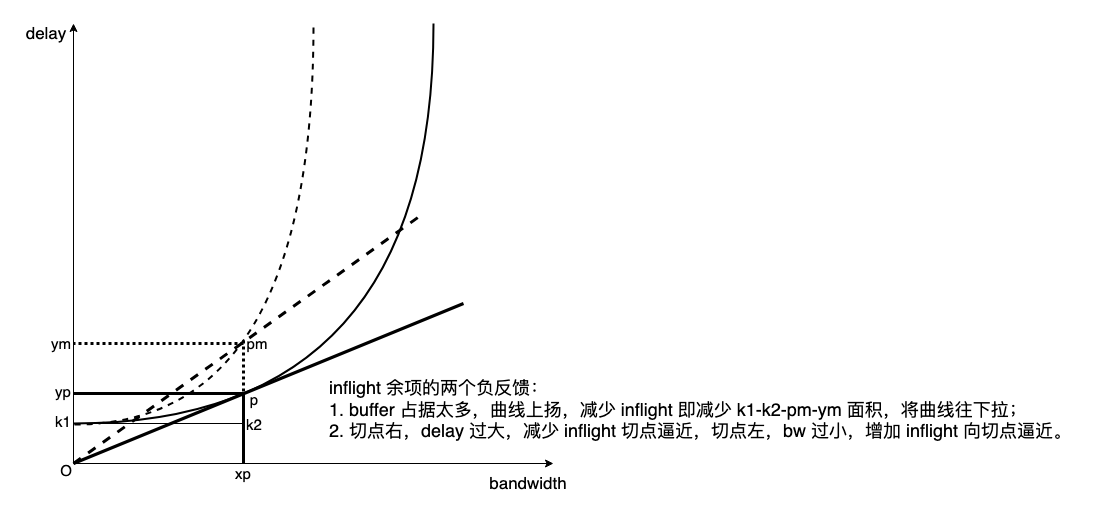
简单又直观。
这是个非常美观的自适应算法,阅读前段时间介绍该算法的系列文章,你会发现几乎什么都不用做就能同时保证高带宽利用率,公平,少 queuing,无抖动。
除此之外,即然找对了操作点,逼近它的方式就不止一种,以下是传统 aimd 方式逼近,与 reno/cubic 唯一不同的只是改变了操作点:
- 在 n-round 内 E = bw / delay 递增或持平,针对 cwnd 执行步长为 alpha 的 additive increase;
- 在 n-round 内 E = bw / delay 递减,针对 cwnd 执行小系数 multiplicative decrease。
如此小步快跑逼近 E = max(bw / delay),aimd 本身亦确保快速公平收敛。
为什么如此简单,切肉要对纹路,找对了操作点,只基于 inflight 做控制,别的就没什么余事了。我为什么说不要按照 delivery rate(测量而得到) 来 pacing,这就是余事,多一事都是坏事:

因此,包括 bbr 在内的所有 rate-based 算法(以 pacing rate 做 primary control parameter)都要不断以大于 1 的 gain 做 probe,小于 1 的 gain 做 drain 来调整 pacing rate,正是因为你做错了一件事,就要去弥补它的任何所有副作用,做得越错,要做的越多。
但再次重申,不按 delivery rate 做 pacing 并不意味着不做 pacing,pacing 的目的是防止第一跳 bufferbloat 而不是做配速,所以比 burst 加一点 gap 即可。
所以,拥塞控制的核心是控制 inflight,sender 做与 delivery rate 无关的 pacing,别多做,别做错。
有必要澄清一下 bufferbloat。bufferbloat 并非源端口接收的比目标端口发送的多,而指下面一种状态:

即使发送速率匹配瓶颈带宽,queue 也依然存在。这种 bufferbloat 状态往往是某次或偶然不经意或故意的连续 burst 造成的,一旦造成 bufferbloat 状态,端到端很难感知到,因此也没有主动 drain 的动机和时机,因此,考虑到统计突发,不要 burst 是避免 bufferbloat 状态的最佳方法,稍微 pacing 一下即可,这与 delivery rate 无关,后者是用来算 bdp 而控制 inflight 的。
就说这么多。
浙江温州皮鞋湿,下雨进水不会胖。














 6949
6949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









