






拥塞控制面临的几类问题:
- 网络拥塞时,大象流如何为微突发让路;
- 网络拥塞时,如何只惩罚造成拥塞的流量;
- 网络拥塞时,如何确保小流量不受影响。
既然不想在 host 将流按照大小分类,嫌没意义,麻烦或看不上,那其实交换机一直在做这件事,比如优先级队列,加权公平队列,加权随机早期检测等,不管是物理交换机还是虚拟交换机,这几样肯定跑不了。
但那些队列和调度策略往往配置复杂,实现太重,且无法自适应流量特征的变化。
codel 是个好东西,fq_codel 更有点意思,自适应携带负反馈环,这个我喜欢。
linux 的 fq_codel 实现中在 enqueue 位置有个针对最长队列的 fq_codel_drop 操作,只在队列满载时执行,还是太粗糙。我后来在它基础上修改了一版,改动如下:
- enqueue 队列长度超限后,在所有长度大于某个预设值的足够 fat 的 flow 中分担删除报文,flow 长度即分担权重(后面会提到一种预防重传风暴的情况,特意在同一个队列丢包,而不是分担)。
再后来,我增加了 dequeue 逻辑,就成了一个虚拟交换机的框架,它的原理如下:
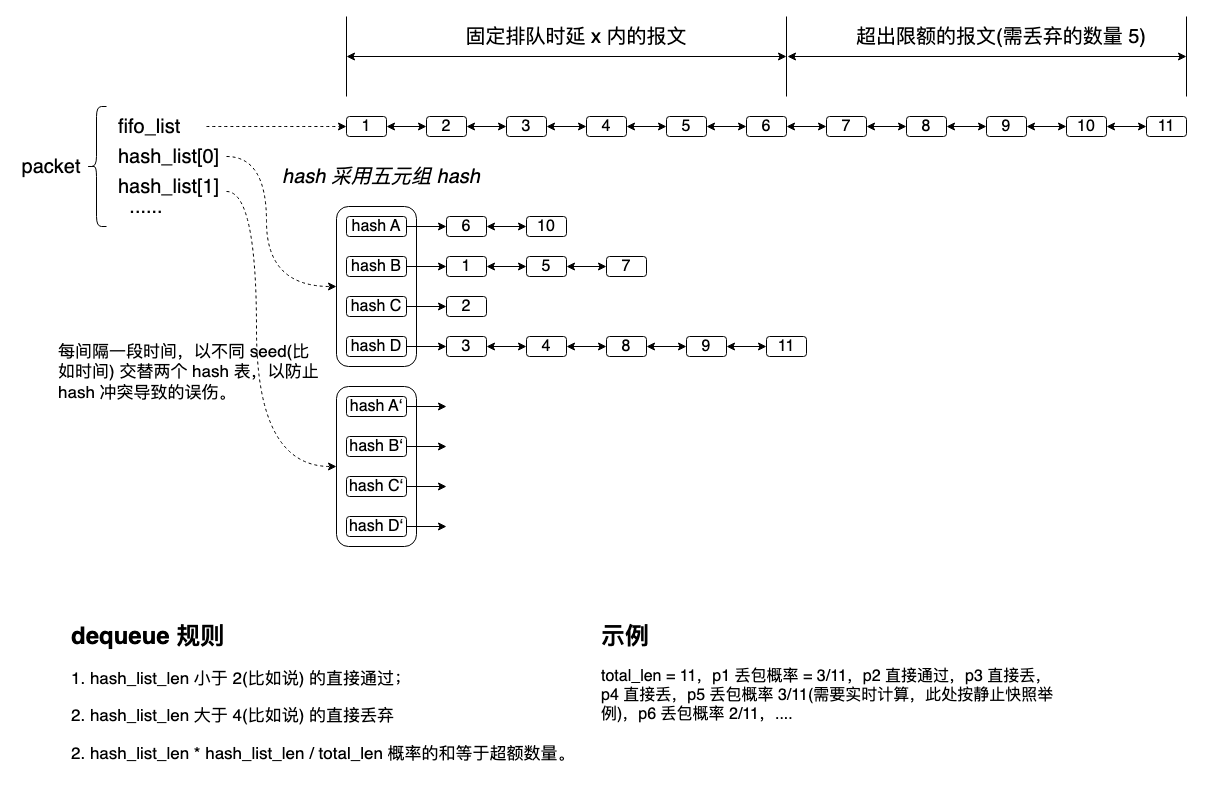
在 dequeue 而不在 enqueue 做的理由如下:
- enqueue 由不同的 ingress 端口(物理 or 虚拟)执行,执行复杂逻辑涉及 lock 过久问题;
- enqueue 逻辑对大象流丢包会导致队列中的流长度反转,误伤中等流量。
- dequeue 位置是个一致的并行 check 点。
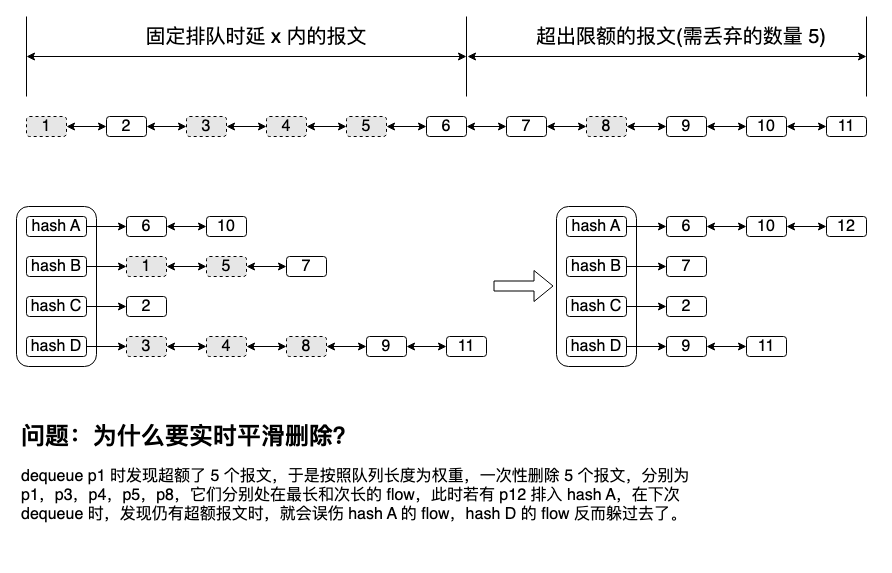
另一个点,在每一次 dequeue 报文时,按概率删除报文追求的不仅仅是平滑,另一种看起来更简单的方式反而会造成颠簸,误伤良性流量,与上述不在 enqueue 做此逻辑的理由 2 一样。简单分析一下 why:
最后,谈谈该 aqm 的算法细节。
这种自适应策略可以逐渐让各 hash list 长度趋向一致,迫使各流量收敛到公平(如果端到端算法不主动收敛,aqm 会迫使它们收敛),但如果所有 hash list 长度都快速增加,且长度趋向一致,那就是遇到 incast 了,应尽力缓存而不是丢包,因此应该夹带以下逻辑:
- 以均匀方差做指标切换策略,方差越大,越趋向丢包,方差越小,越趋向缓存;
- 趋向缓存,但 buffer 不足,必须丢包时,尽量在同一个队列丢,防止重传 incast。
所以,这一切能否自适应?答案是肯定的。保存一个系数 a = (max_len - min_len) * (mid_len - avg_len) * avg_len:
- 丢包概率计算时乘以 a 即可,hash 队列越畸变,丢包率越高,反之越平坦,丢包率越低;
- enqueue 逻辑的队列 limit 改为动态计算,a 越小,说明有 incast 微突发,limit 就要越大,limit 做成 a 的负相关函数即可;
- limit 越大,越倾向于在一个队列丢包,计算每队列丢包数量是要乘以 a 的负相关函数,a 越小,每队列丢包数量越多。
简单数学函数的威力无穷。
浙江温州皮鞋湿,下雨进水不会胖。















 1322
1322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









